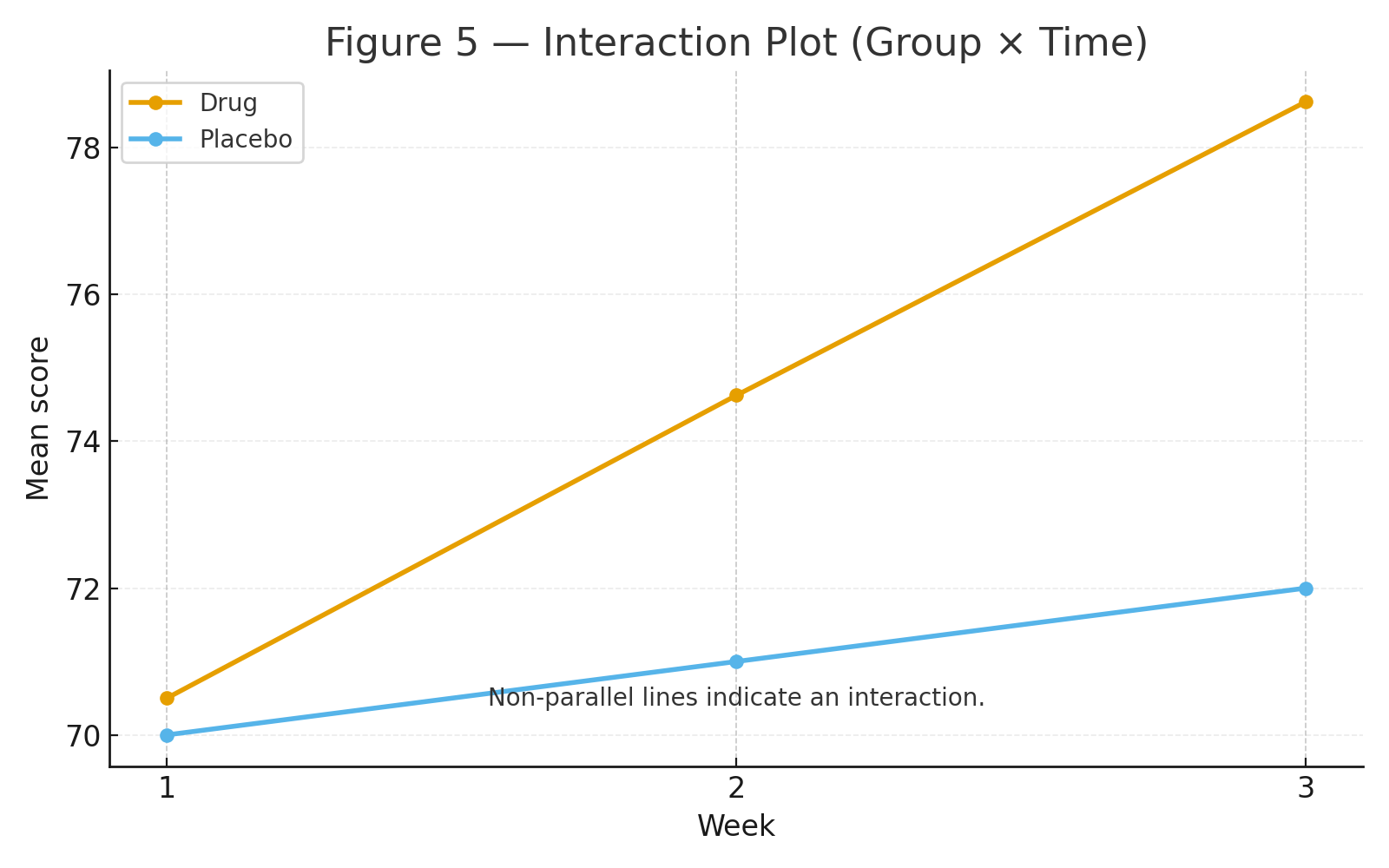
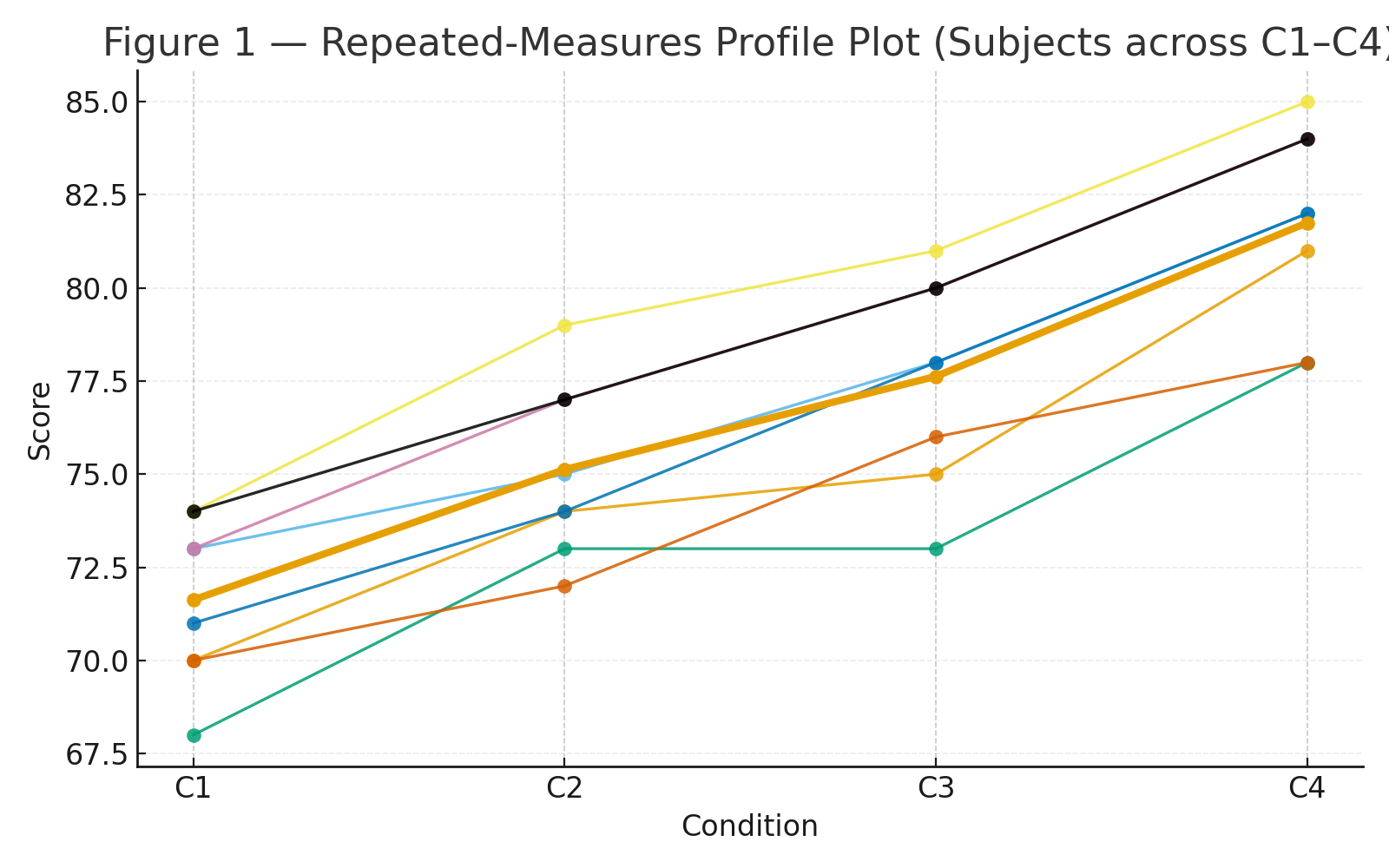
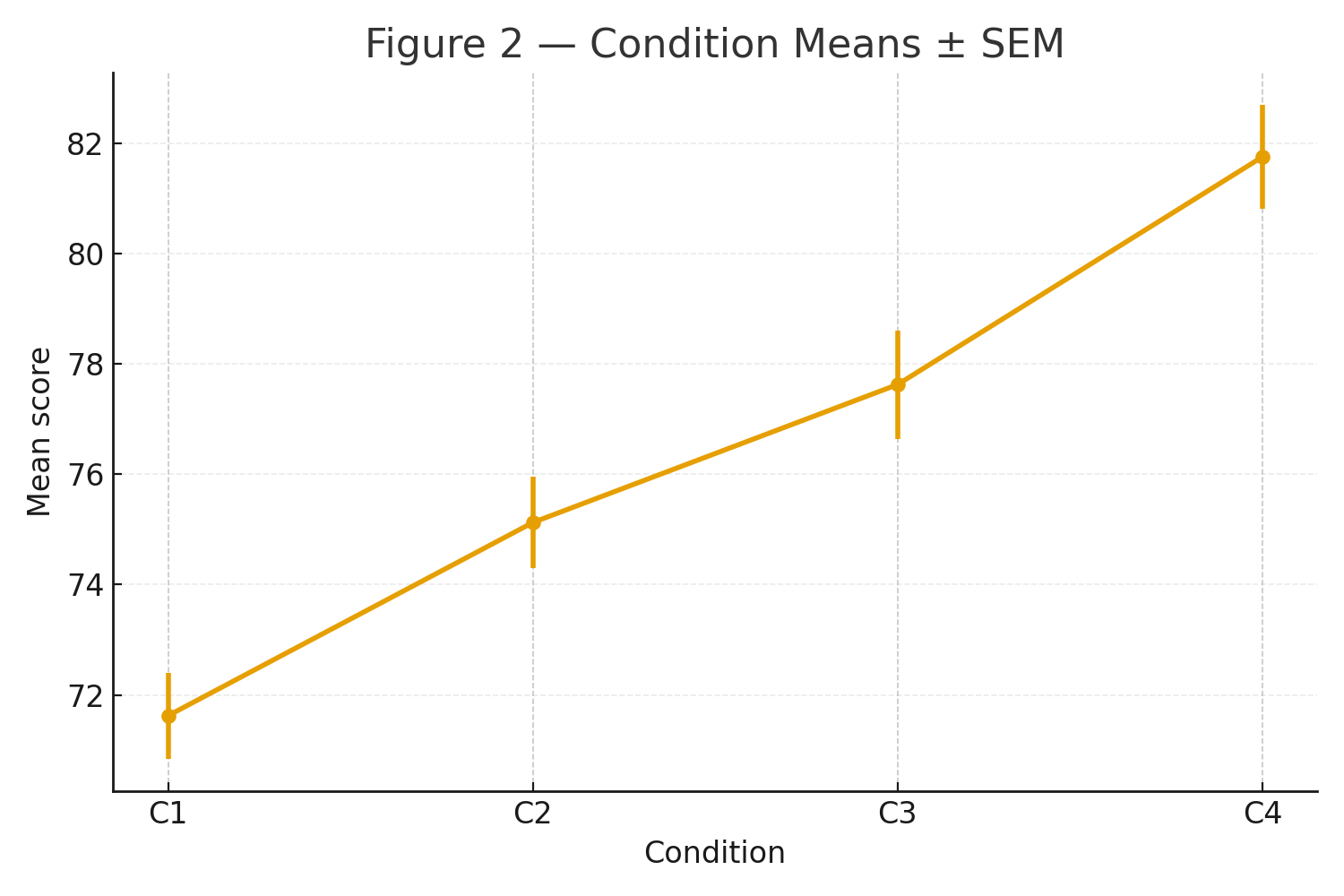
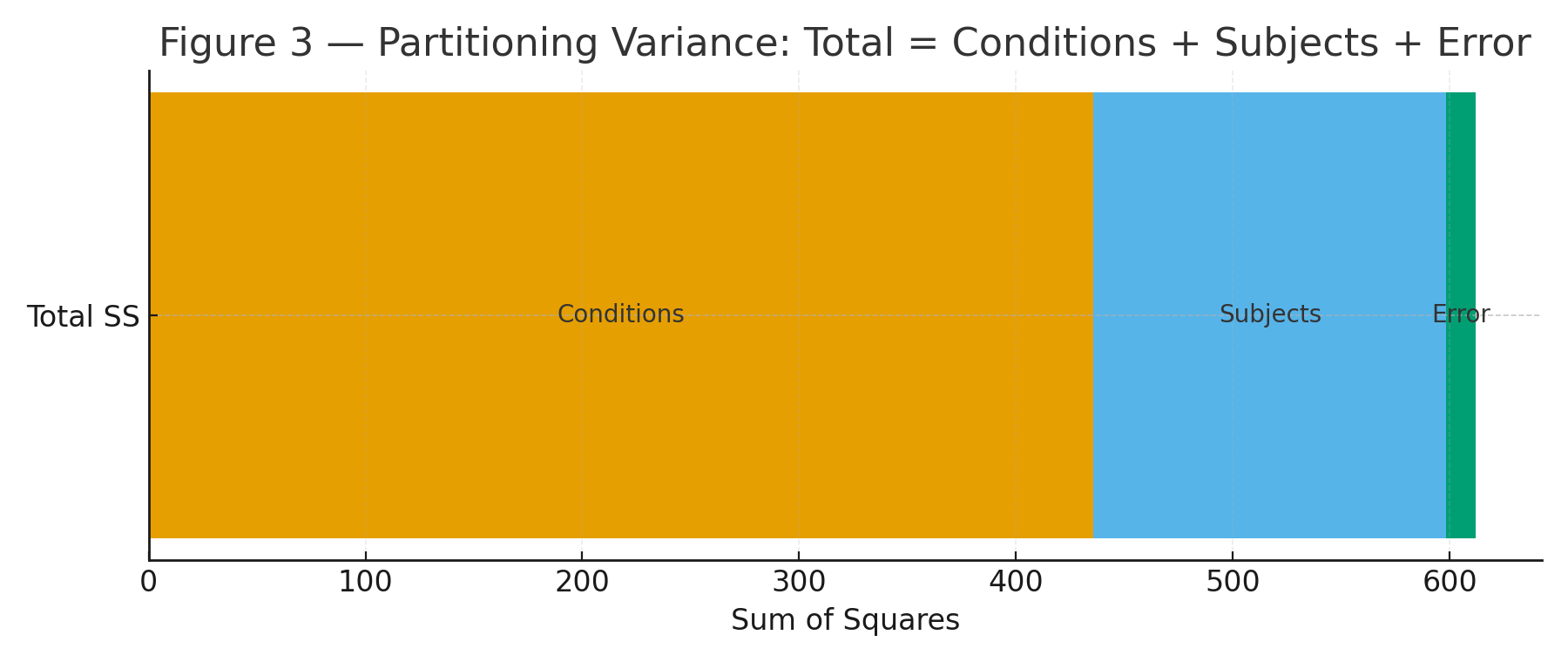
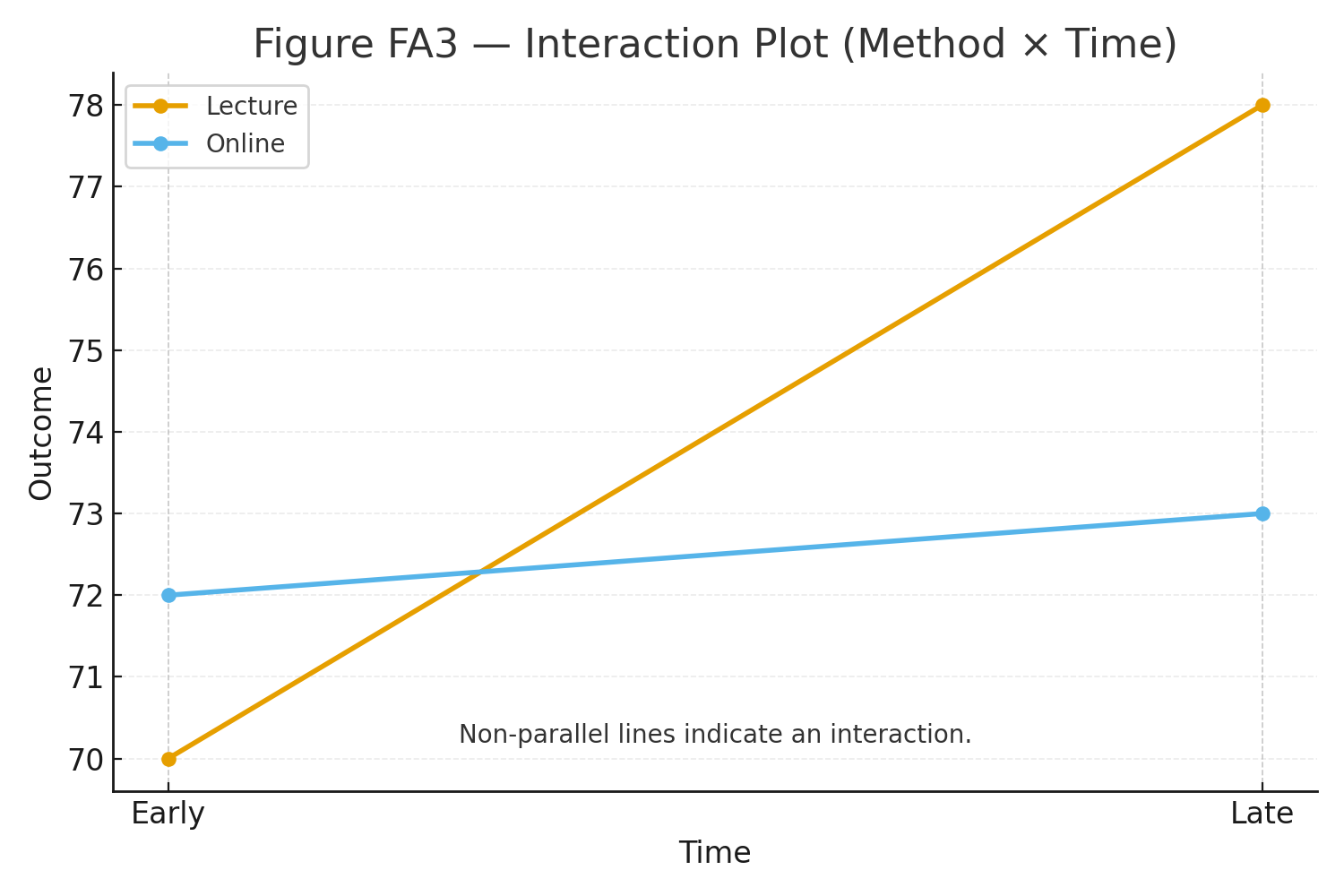
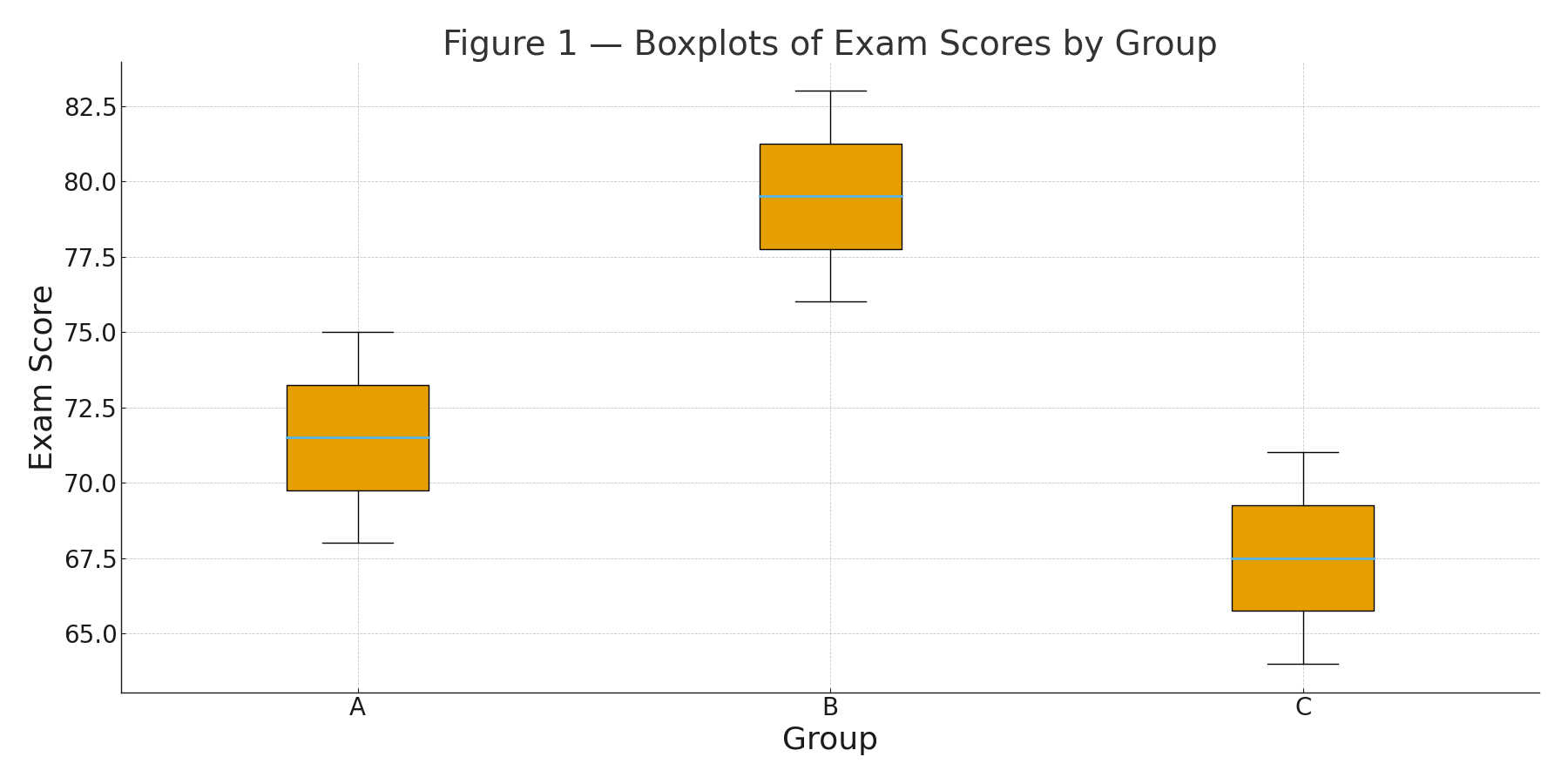
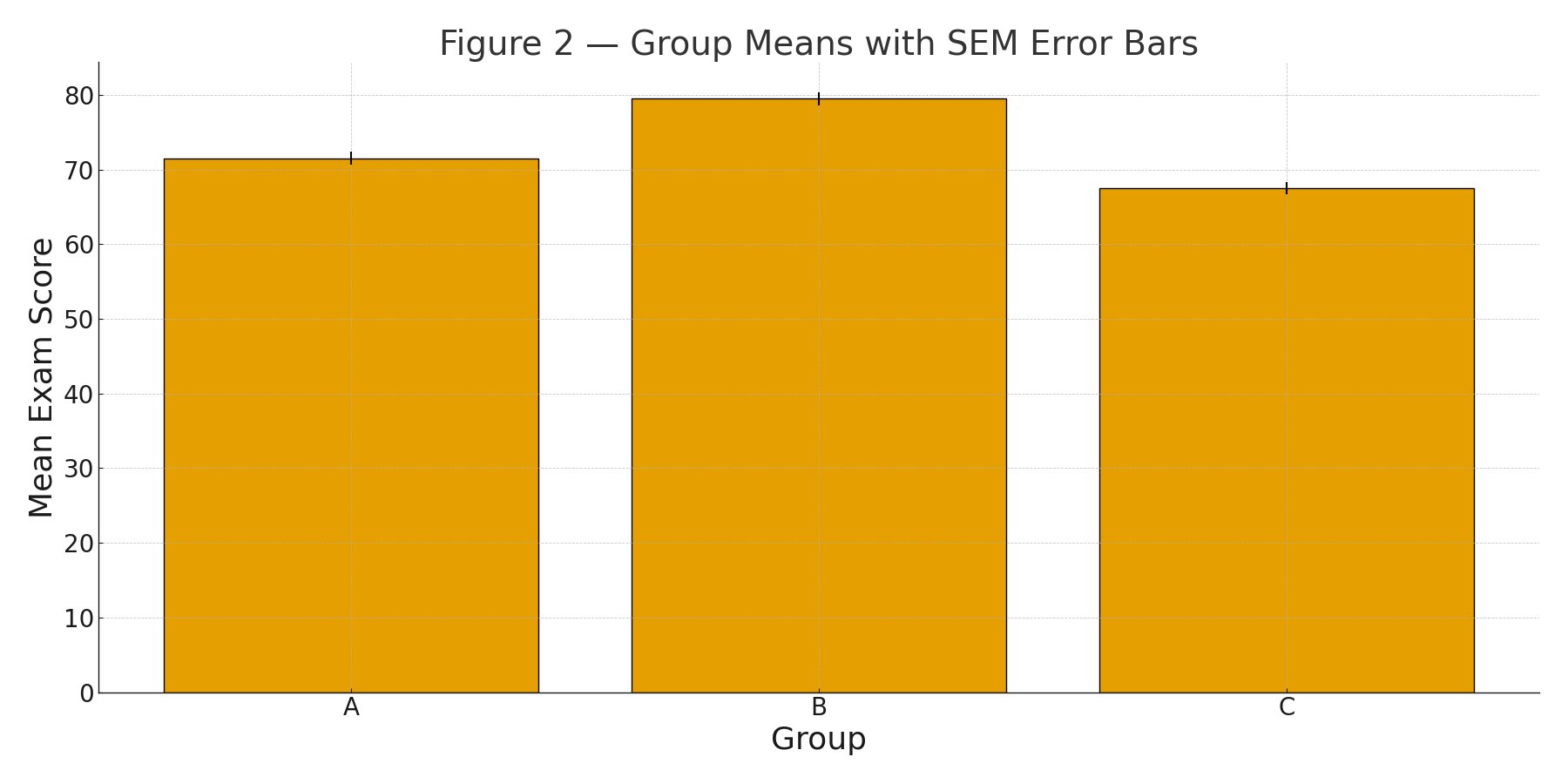
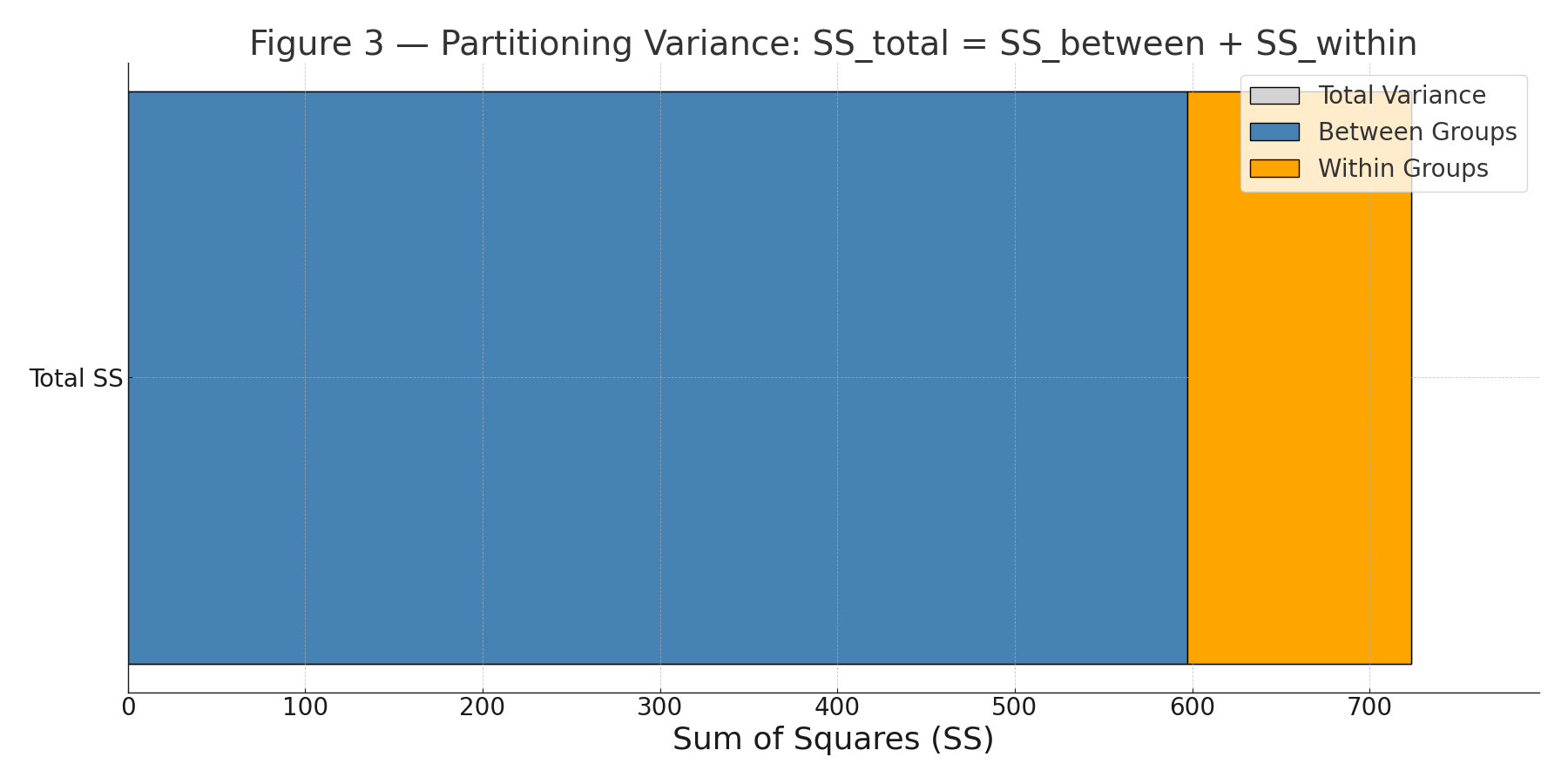
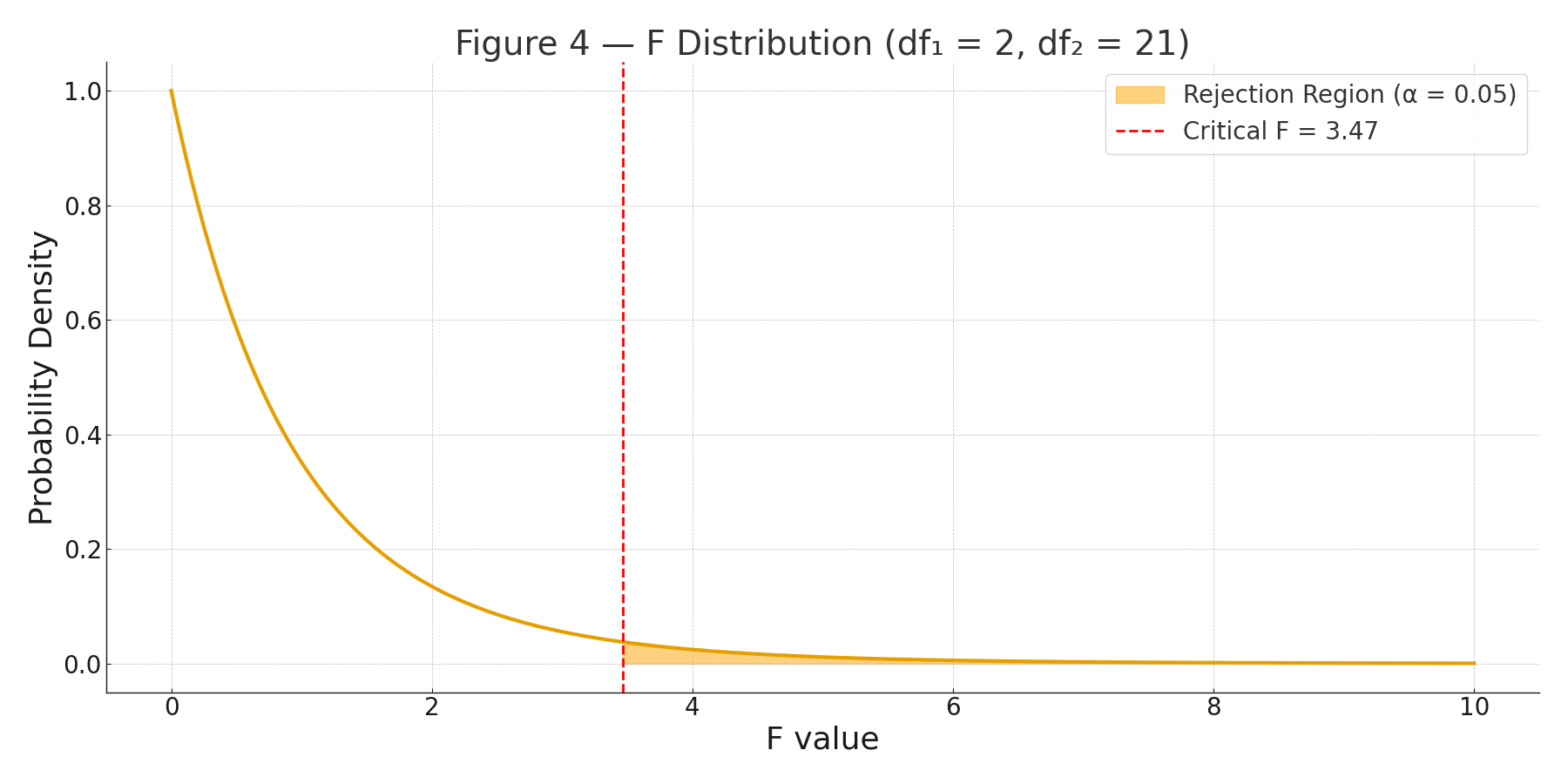
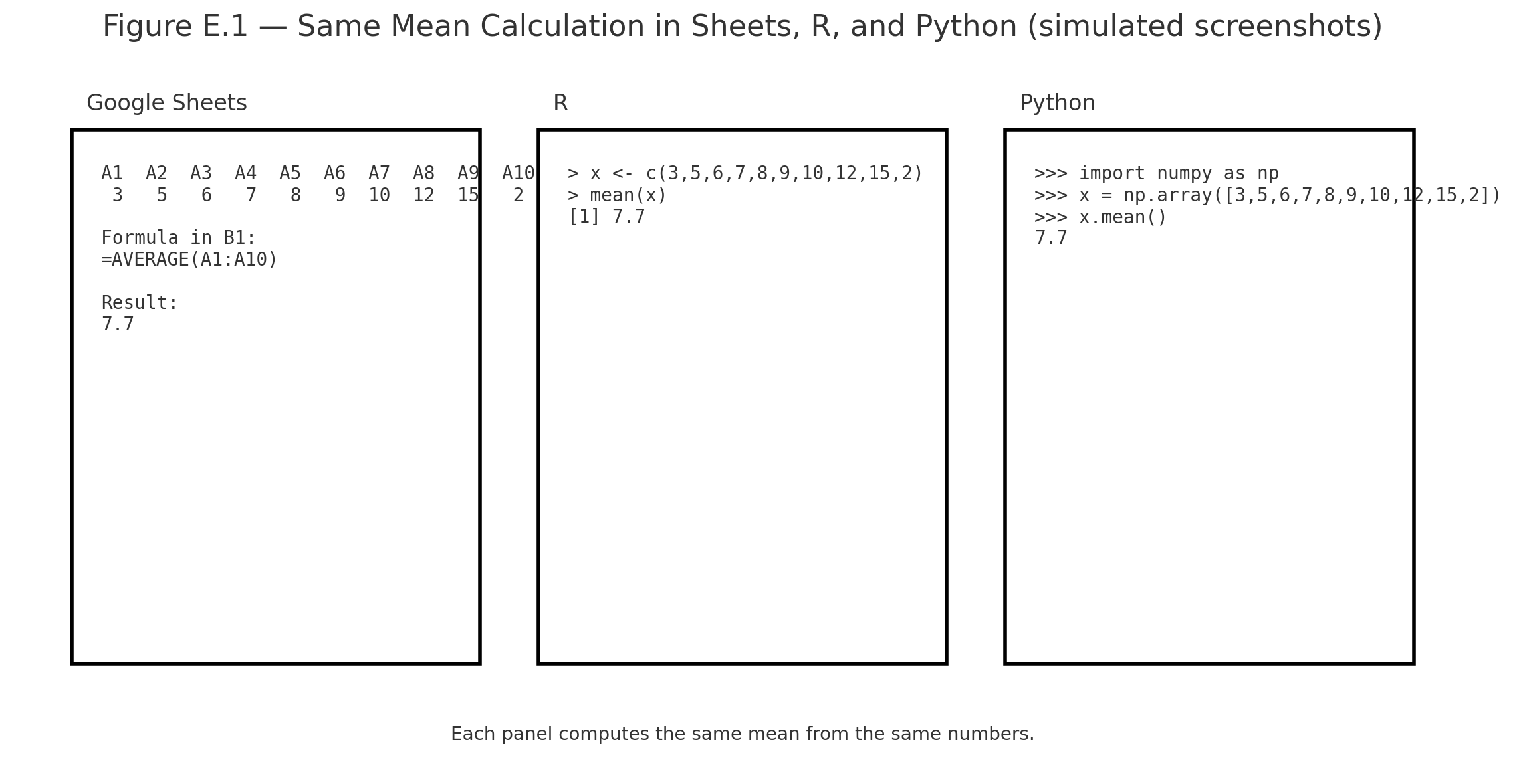
About | High School Statistics (Pre-College)
About This Textbook
Statistics for High School Students: Pre-College is a free, comprehensive, and interactive online textbook written by Dr. Michael Nikoletseas—a professor and researcher with numerous publications in neuroscience, philosophy of science, and mathematics. Using only simple arithmetic, straightforward formulas, and plain English, this resource is designed to be highly accessible. Despite its simplicity, it covers both elementary and advanced statistics topics, as well as modern data science concepts.
Mission & Vision
Our mission is to deliver a statistics textbook that:
- supports students across a wide range of disciplines (from social and behavioral sciences to engineering and mathematics) to acquire a deep understanding of statistical reasoning, not just procedural techniques;
- presents key statistical concepts in a manner that bridges theory and practice, emphasizing interpretive insight (“what does this mean?”) alongside computational method;
- adopts an open mindset toward pedagogy: the site is structured for readability, modular use (individual chapters may be used independently if desired), and easy updates as the field evolves;
- integrates modern elements—resampling, simulation, machine learning prelude, robust inference—while preserving the classical foundations (distributions, hypothesis testing, ANOVA, regression) so students are well‐grounded for further work.
Who This is For
This textbook is ideal for:
- high school students preparing for biology or social science majors.
- students in a one- or two-semester introductory statistics sequence who want more than formula memorization;
- non‐mathematics majors (e.g. philosophy of science) who need to understand how to interpret and apply statistical reasoning in their discipline;
- mathematics or statistics majors seeking a readable, web‐enabled resource that complements more formal references;
- educators who want a ready‐to-use, modular, up‐to‐date resource for their course, including figures, examples, and modern topics.
Author & Credentials
Dr Michael Nikoletseas is the author of this textbook and brings a unique interdisciplinary background: his published works span neuroscience, philosophy of science, and mathematics, and are held in leading academic libraries (Harvard, Oxford, Princeton). His ambition with this text is to raise the bar for clarity, coherence, and depth in undergraduate statistics education.
With this online text, he applies the same analytical rigor he uses in his philosophical and mathematical writing: clear definitions, structured exposition, precise notation, and an emphasis on the limits of inference and interpretation (a theme that resonates with his broader work in epistemology).
Structure of the Textbook
The book is arranged into chapters each designed to stand on its own while also fitting into an integrated whole. Typical chapters will proceed in this order:
- Introduction & motivation
- Essential theory and notation for mathematics and formulas)
- Detailed examples and figures (copyable images for instructor use)
- Worked problems, with step-by-step solutions and commentary
- Live self-test quizzes
- Ask questions in each chapter
- Advanced topics, extensions, and links (for students preparing for further study)
Current chapters already include: descriptive statistics, probability, distributions, the normal distribution, hypothesis testing, t‐tests, one‐way and multi‐way ANOVA (including mixed designs and post-hoc comparisons), resampling and simulation, machine learning foundations, and big data computational statistics.
Contact & Feedback
Your feedback is valuable. Should you spot an error, have a suggestion for improvement or want to request supplementary material use Feedback on main menu. Use the contact form below each chapter to ask questions.
Acknowledgements
The creation of this textbook has drawn on countless influences—from classical mathematics and modern statistics pedagogy to insights from neuroscience, philosophy of science, and epistemology. Special thanks to readers and educators who engage with the text, write with questions, and propose improvements. Together we advance statistical literacy and interpretive clarity.
Thank you for visiting StatisticsTextbook.com. May this textbook serve you well in your statistical journey.
— Michael Nikoletseas