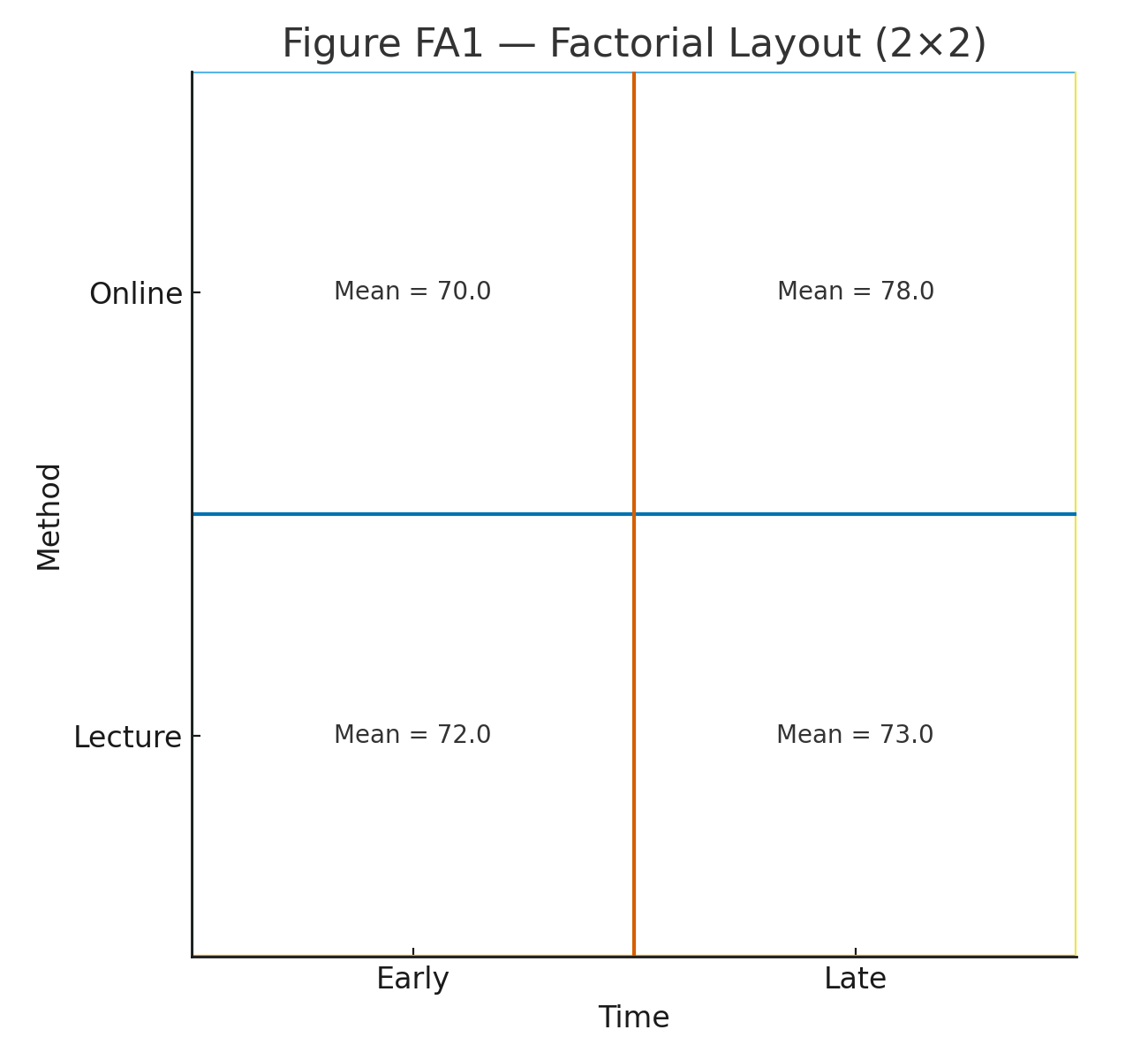
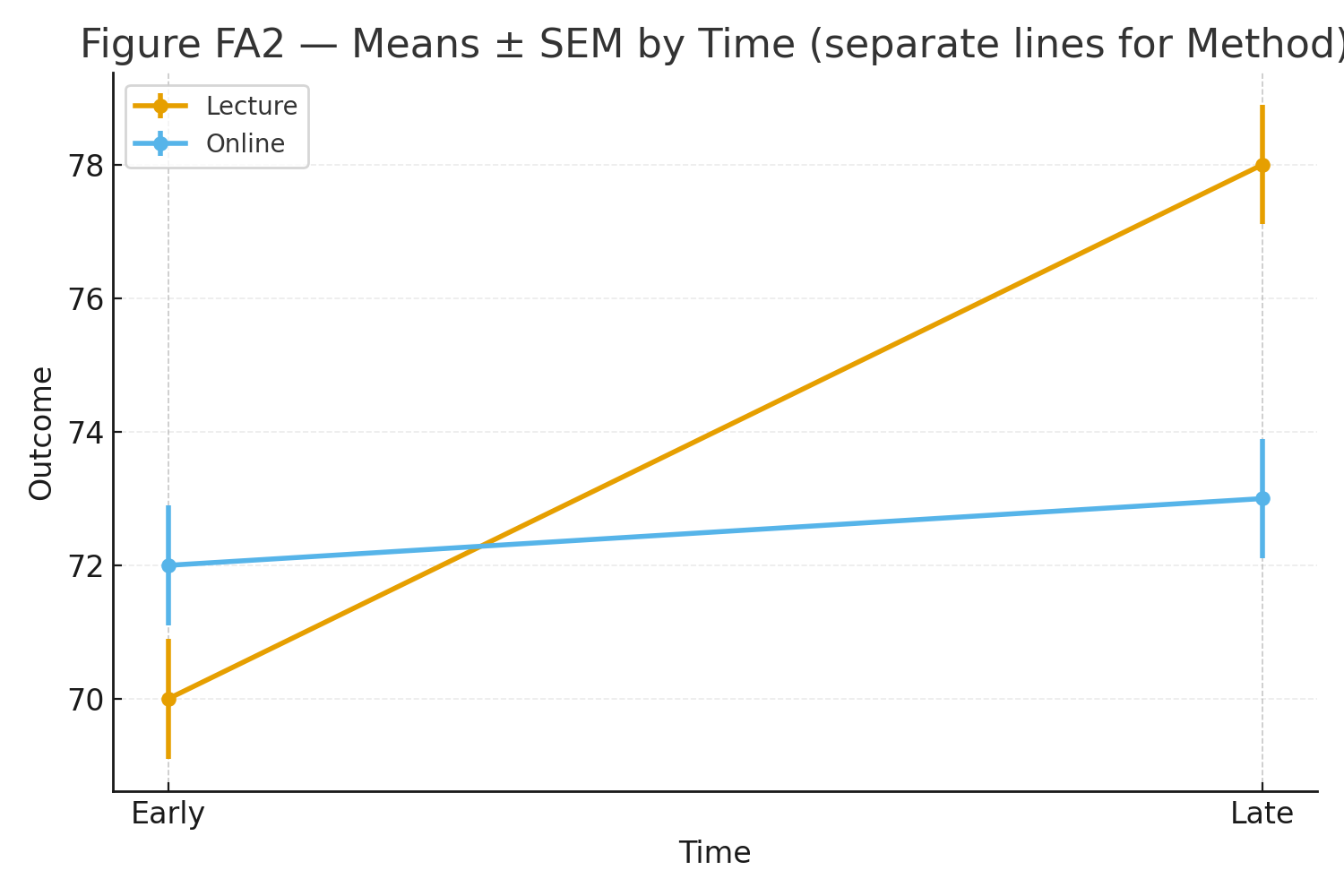
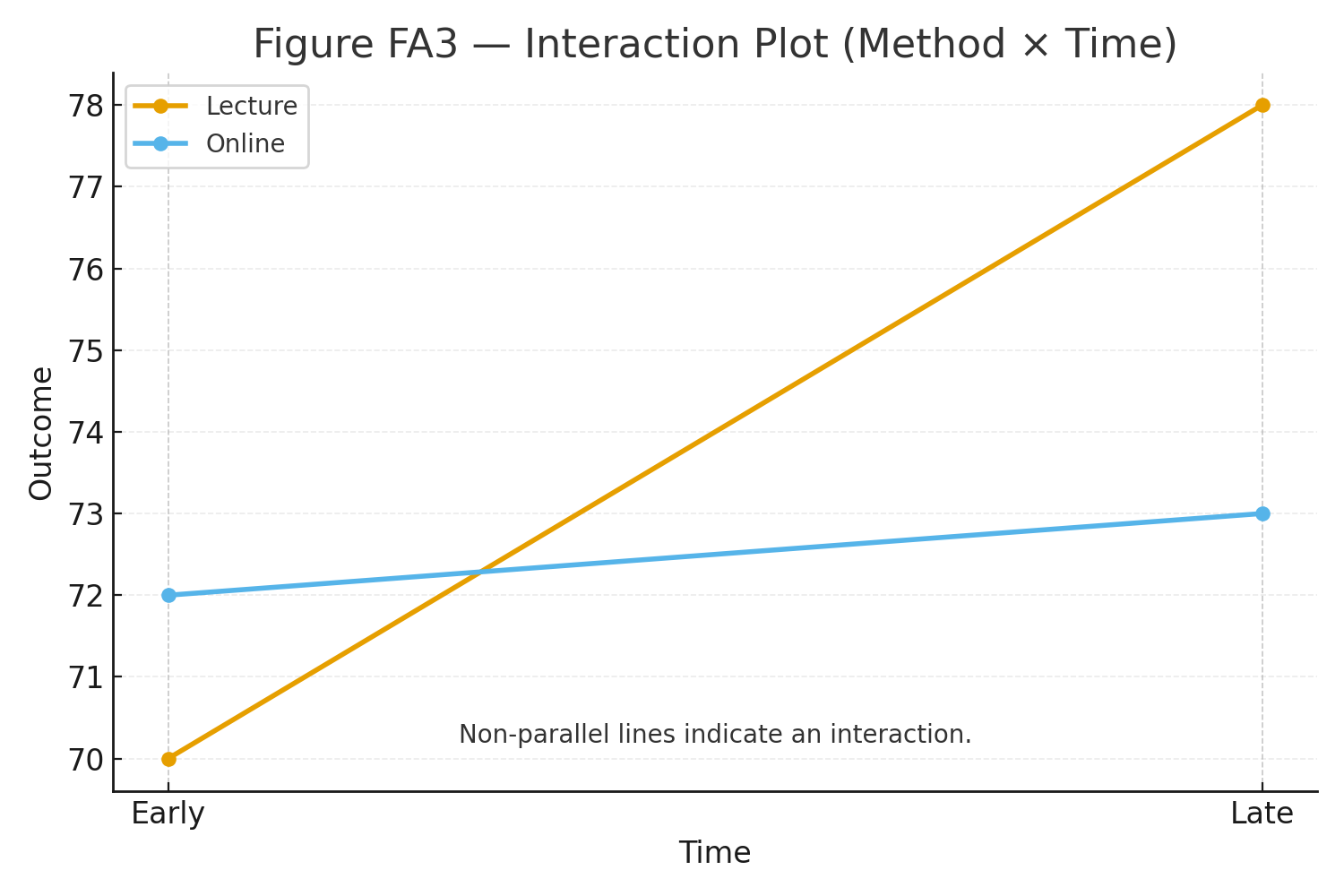
Repeated-Measures ANOVA
Goal. Test whether performance changes across four conditions measured on the same participants.
Design & Experiment
- Within-subjects factor: Condition with 4 levels (C1, C2, C3, C4).
- s = 8 participants measured in k = 4 conditions ⇒ total observations \(N = s \times k = 32\).
- Example context: the same students take four weekly quizzes after different study activities.
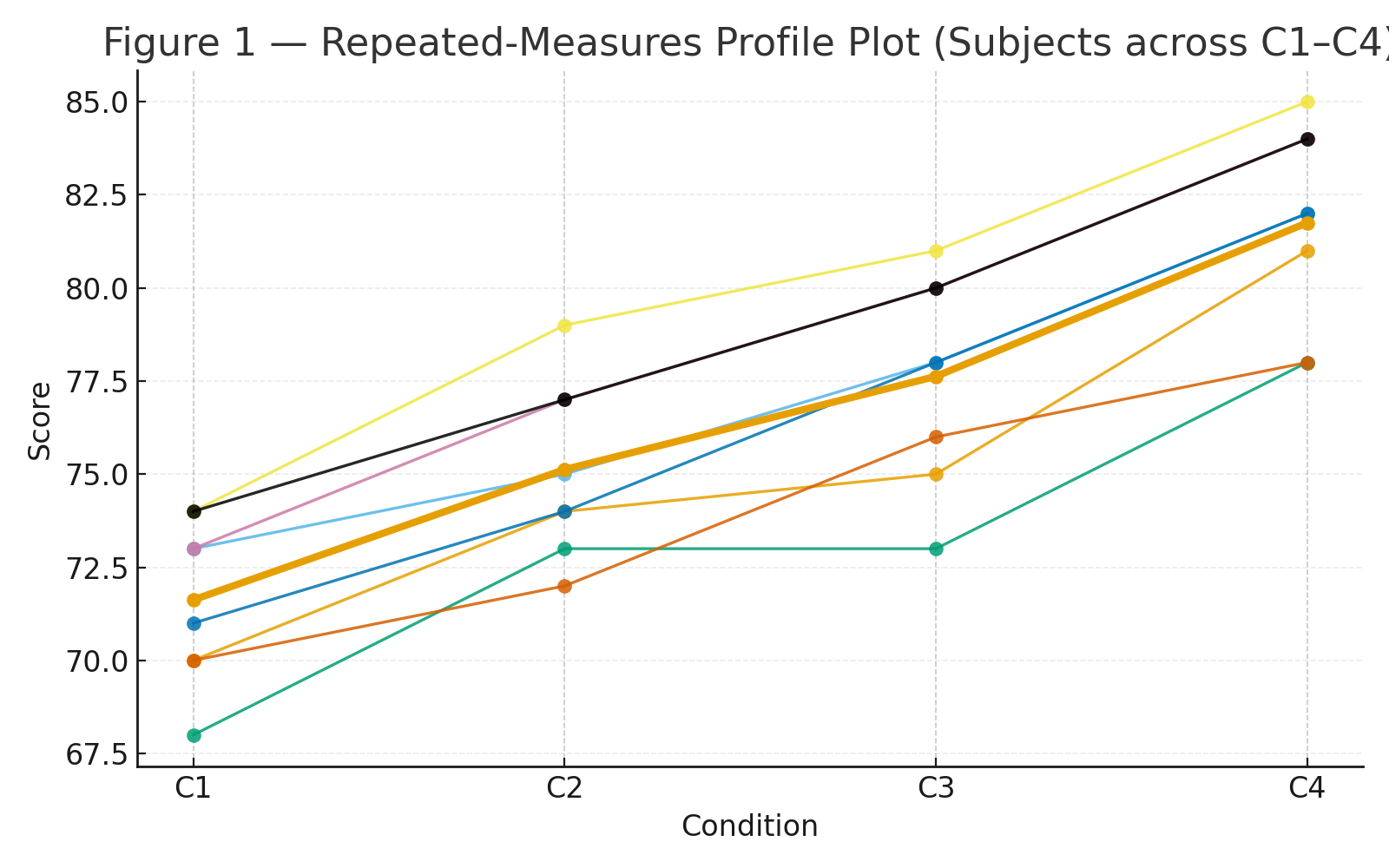
Figure 1: Profile plot (each subject as a line across the four conditions).
Data
Scores (rows = participants S1–S8; columns = conditions C1–C4):
| Subject | C1 | C2 | C3 | C4 | Row sum | Row mean |
|---|---|---|---|---|---|---|
| S1 | 70 | 74 | 75 | 81 | 300 | 75.00 |
| S2 | 73 | 75 | 78 | 82 | 308 | 77.00 |
| S3 | 68 | 73 | 73 | 78 | 292 | 73.00 |
| S4 | 74 | 79 | 81 | 85 | 319 | 79.75 |
| S5 | 71 | 74 | 78 | 82 | 305 | 76.25 |
| S6 | 70 | 72 | 76 | 78 | 296 | 74.00 |
| S7 | 73 | 77 | 80 | 84 | 314 | 78.50 |
| S8 | 74 | 77 | 80 | 84 | 315 | 78.75 |
| Column sums | 573 | 601 | 621 | 654 | Grand sum = 2449 | Grand mean \( \bar X = 2449/32 = 76.53125 \) |
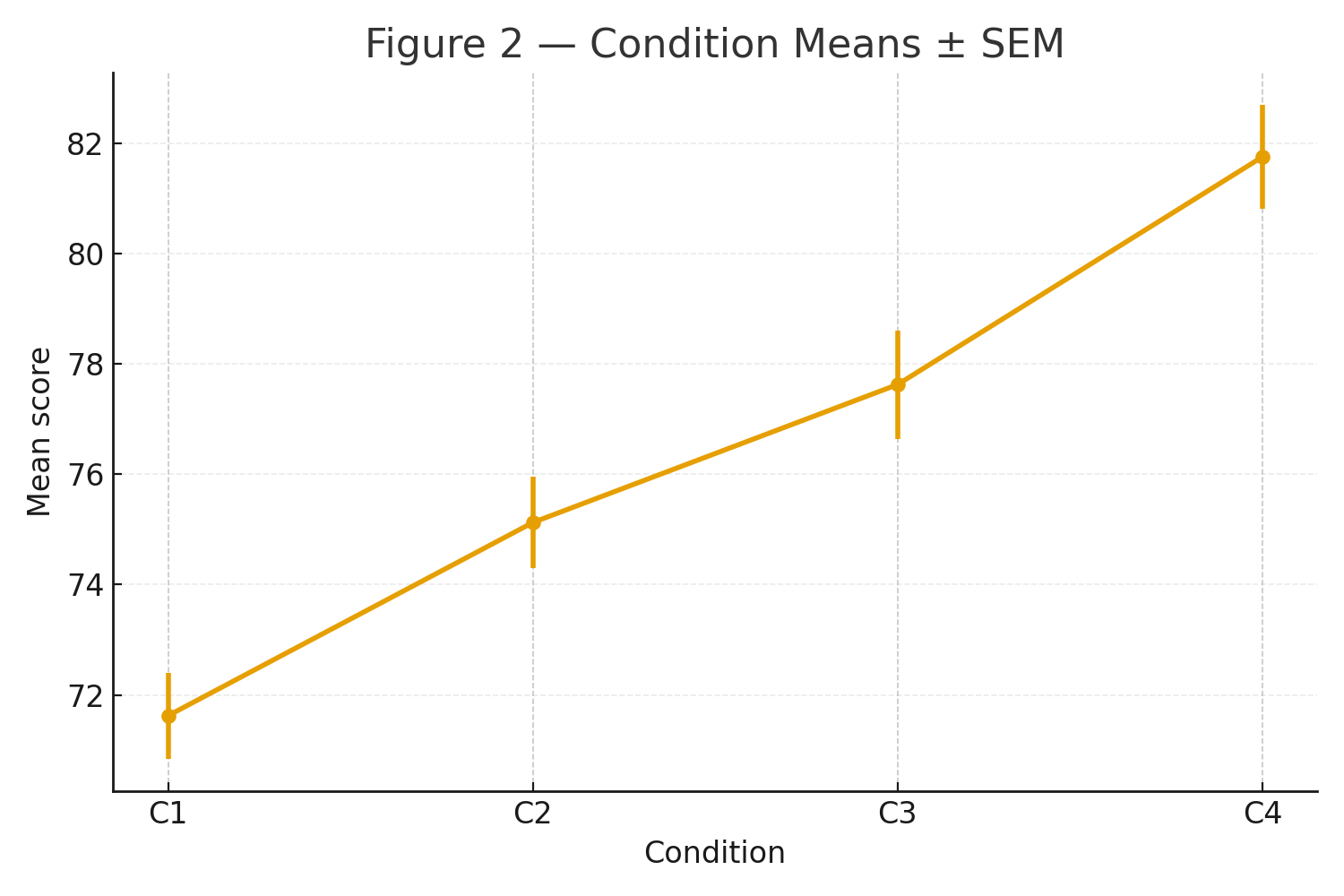
Figure 2: Means ± SEM for C1–C4 (bar/line).
Step 1 — Condition Means (and sample variances)
\[ \begin{aligned} \bar X_{\mathrm{C1}} &= 573/8 = 71.625, \quad & s^2_{\mathrm{C1}} &= 4.8393 \\ \bar X_{\mathrm{C2}} &= 601/8 = 75.125, \quad & s^2_{\mathrm{C2}} &= 5.5536 \\ \bar X_{\mathrm{C3}} &= 621/8 = 77.625, \quad & s^2_{\mathrm{C3}} &= 7.6964 \\ \bar X_{\mathrm{C4}} &= 654/8 = 81.750, \quad & s^2_{\mathrm{C4}} &= 7.0714 \end{aligned} \]
Step 2 — Sums of Squares
Notation: \(s=8\) subjects, \(k=4\) conditions, grand mean \( \bar X = 76.53125\).
2A. Total
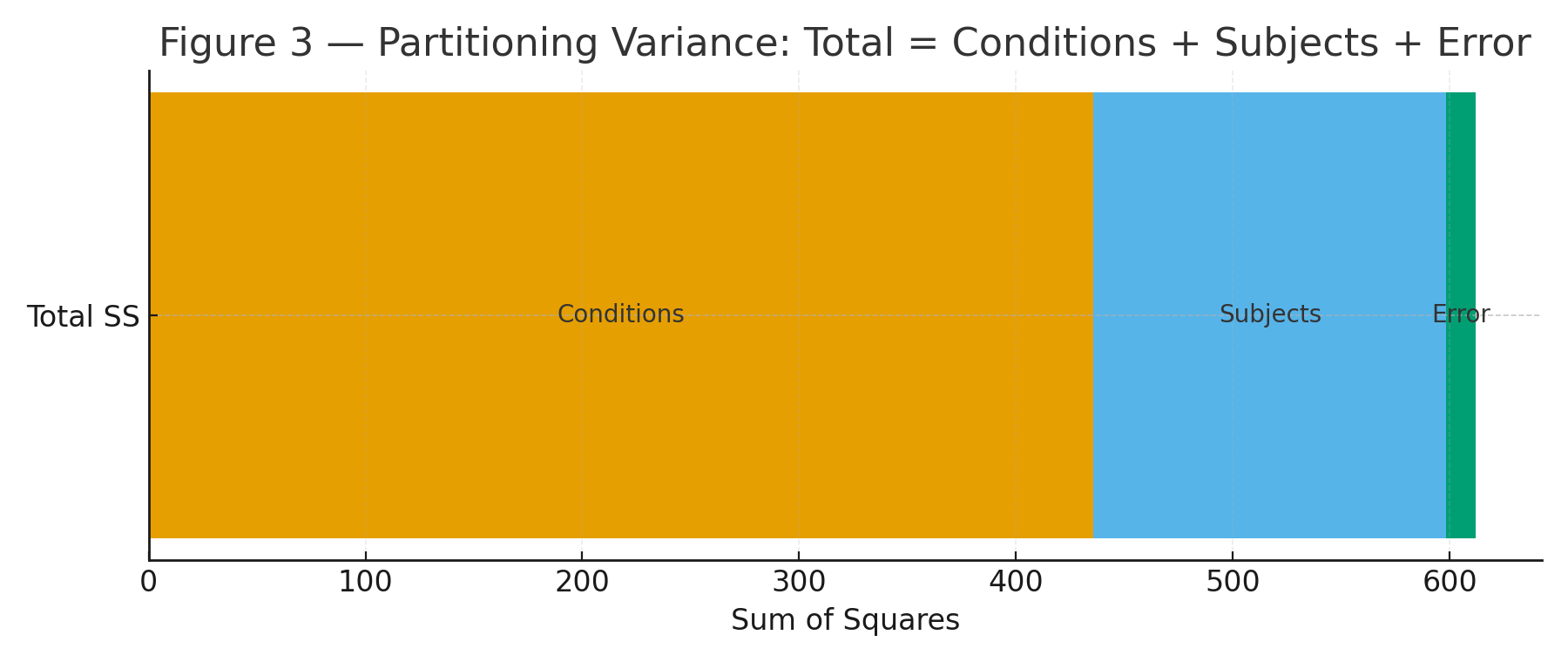
\[ SS_{\text{total}}=\sum_{i=1}^{s}\sum_{j=1}^{k}\bigl(X_{ij}-\bar X\bigr)^2 =\mathbf{611.96875}. \]
2B. Conditions (Treatment)
\[ SS_{\text{cond}}= s \sum_{j=1}^{k}\bigl(\bar X_{\cdot j}-\bar X\bigr)^2 = 8 \left[(71.625-76.53125)^2 + (75.125-76.53125)^2 + (77.625-76.53125)^2 + (81.75-76.53125)^2\right] =\mathbf{435.84375}. \]
2C. Subjects
\[ SS_{\text{subj}}= k \sum_{i=1}^{s}\bigl(\bar X_{i\cdot}-\bar X\bigr)^2 = 4 \sum_{i=1}^{8}\bigl(\bar X_{i\cdot}-76.53125\bigr)^2 =\mathbf{162.71875}. \]
2D. Error (Residual)
\[ SS_{\text{error}}= SS_{\text{total}} - SS_{\text{cond}} - SS_{\text{subj}} = 611.96875 - 435.84375 - 162.71875 =\mathbf{13.40625}. \]
Figure 3: Partitioning variance diagram (Total → Conditions + Subjects + Error).
Step 3 — Degrees of Freedom & Mean Squares
\[ \begin{aligned} df_{\text{cond}} &= k-1 = 3, \\ df_{\text{subj}} &= s-1 = 7, \\ df_{\text{error}} &= (s-1)(k-1) = 7\times3 = 21, \\ df_{\text{total}} &= sk-1 = 31. \end{aligned} \]
\[ MS_{\text{cond}} = \frac{SS_{\text{cond}}}{df_{\text{cond}}} =\frac{435.84375}{3}=\mathbf{145.28125},\qquad MS_{\text{error}} = \frac{SS_{\text{error}}}{df_{\text{error}}} =\frac{13.40625}{21}=\mathbf{0.6383928571}. \]
Step 4 — Test Statistic & p-value
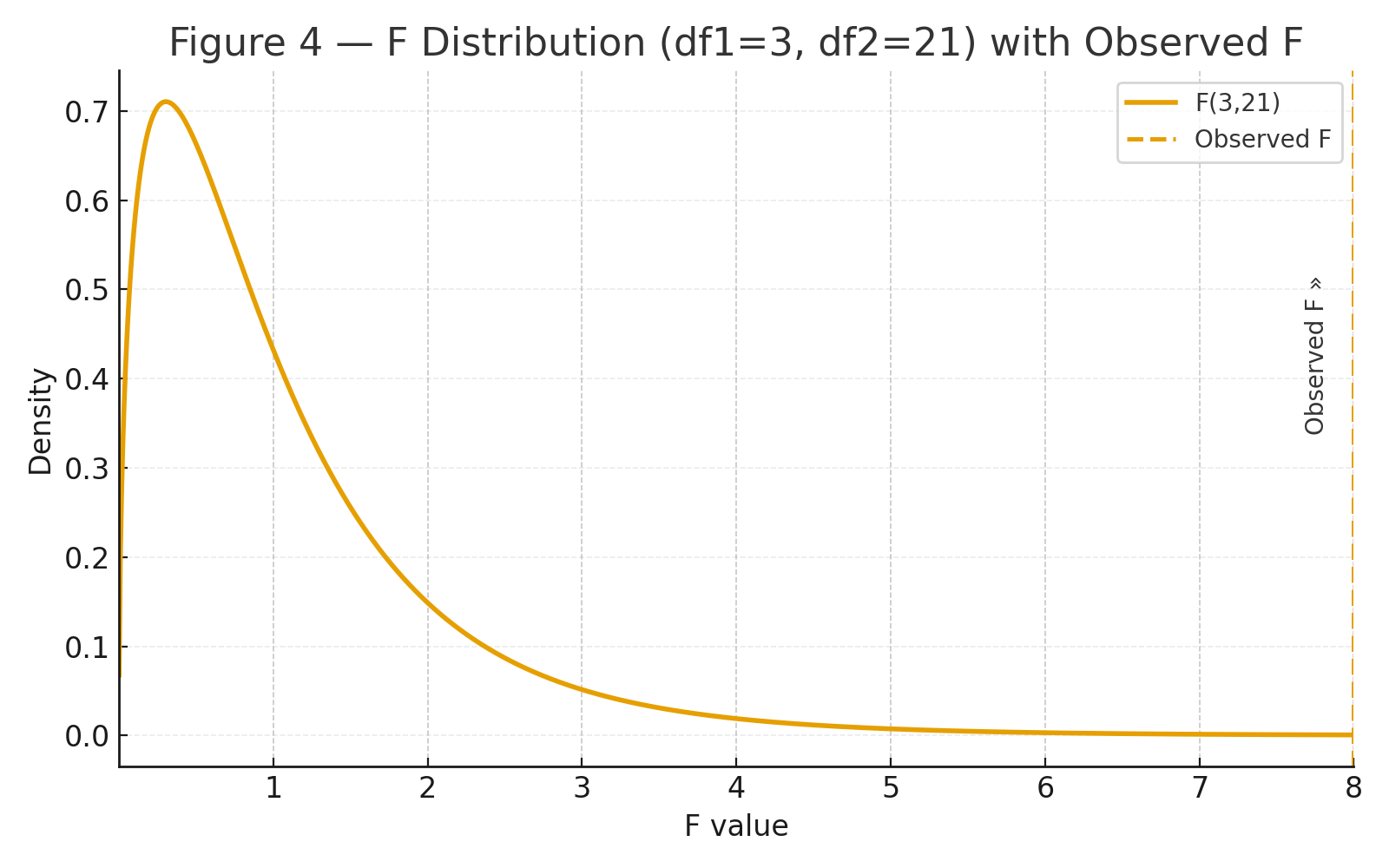
\[ F = \frac{MS_{\text{cond}}}{MS_{\text{error}}} = \frac{145.28125}{0.6383928571} =\mathbf{227.5734}. \] With \(df_1=3\) and \(df_2=21\), this is extremely large. The right-tail p-value is effectively \(p \lt 10^{-12}\) (i.e., \(p \ll .001\)).
Figure 4: F distribution with observed F marked and right-tail region shaded.
Repeated-Measures ANOVA Summary Table
| Source | SS | df | MS | F | p |
|---|---|---|---|---|---|
| Conditions (within) | 435.84375 | 3 | 145.28125 | 227.5734 | < 1e-12 |
| Subjects | 162.71875 | 7 | 23.24554 | — | — |
| Error (residual) | 13.40625 | 21 | 0.63839 | — | — |
| Total | 611.96875 | 31 | — | — | — |
Interpretation
Mean performance increases steadily from C1 → C4, and the repeated-measures ANOVA shows a highly significant effect of Condition, \(F(3,21)=227.57,\, p\ll .001\). Follow-ups (e.g., paired t-tests with Bonferroni/Holm) can localize which pairs of conditions differ.
Assumptions (checklist)
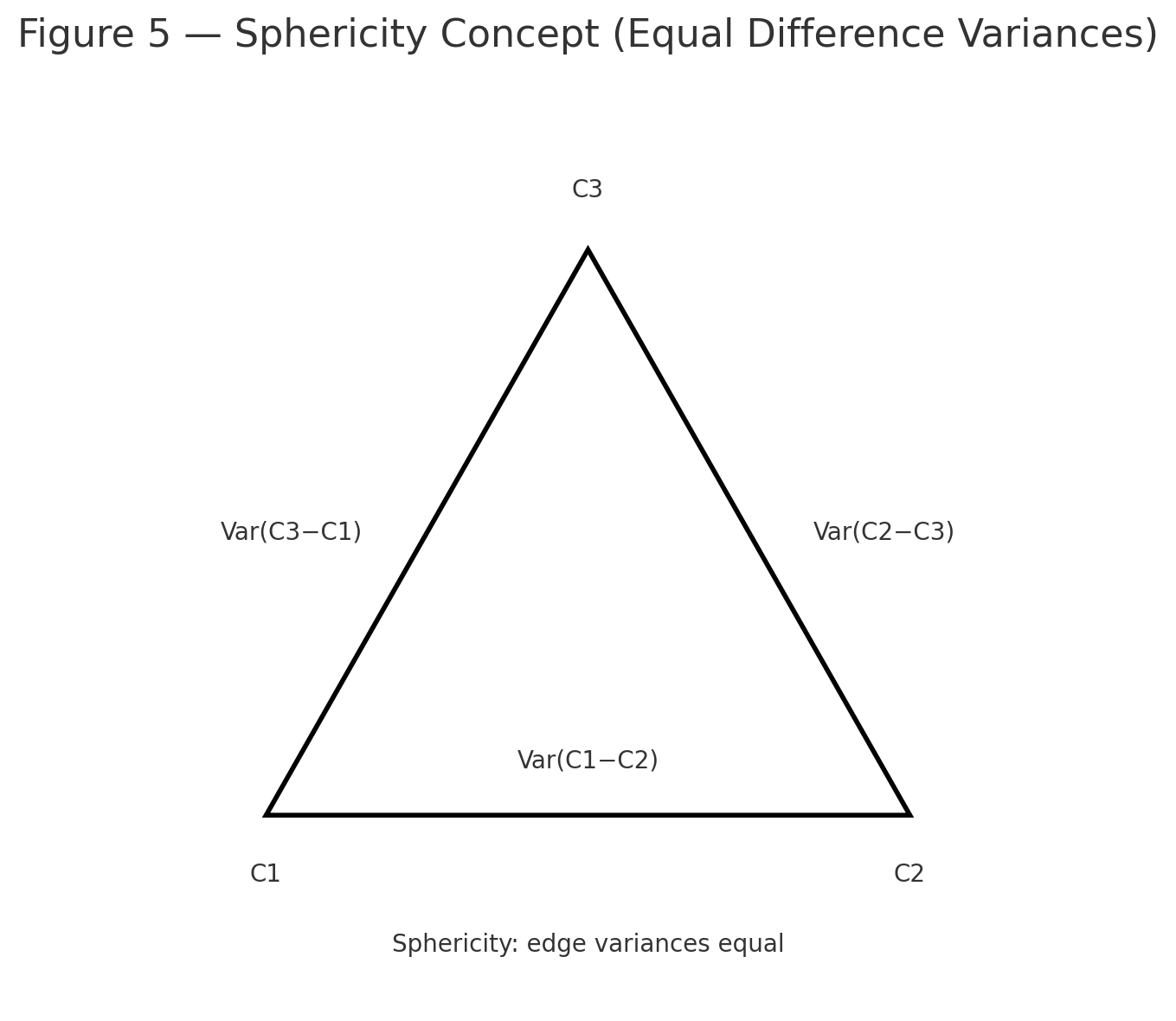
- Sphericity (equal variances of the differences between condition pairs). If violated, apply Greenhouse–Geisser or Huynh–Feldt correction to \(df\).
- Approximately normal scores within each condition.
- No carryover/fatigue effects that confound order (counterbalancing helps).
Figure 5: Sphericity concept sketch (pairwise difference variances).
Practice self-test quiz
In the space below, please find practice problems and self-test quizzes. For full access, please signup free.