Factorial ANOVA
Goal. Test the effects of Method (Lecture vs. Online) and Time (Early vs. Late) on exam scores, and whether there is an interaction between Method and Time.
Design & Experiment
- Factor A (Method): Lecture vs. Online
- Factor B (Time): Early vs. Late
- Balanced design: \(n=5\) per cell ⇒ total \(N=20\).
Students are randomly assigned to one of four cells (Method × Time). After a short module, all students take the same 100-point exam.
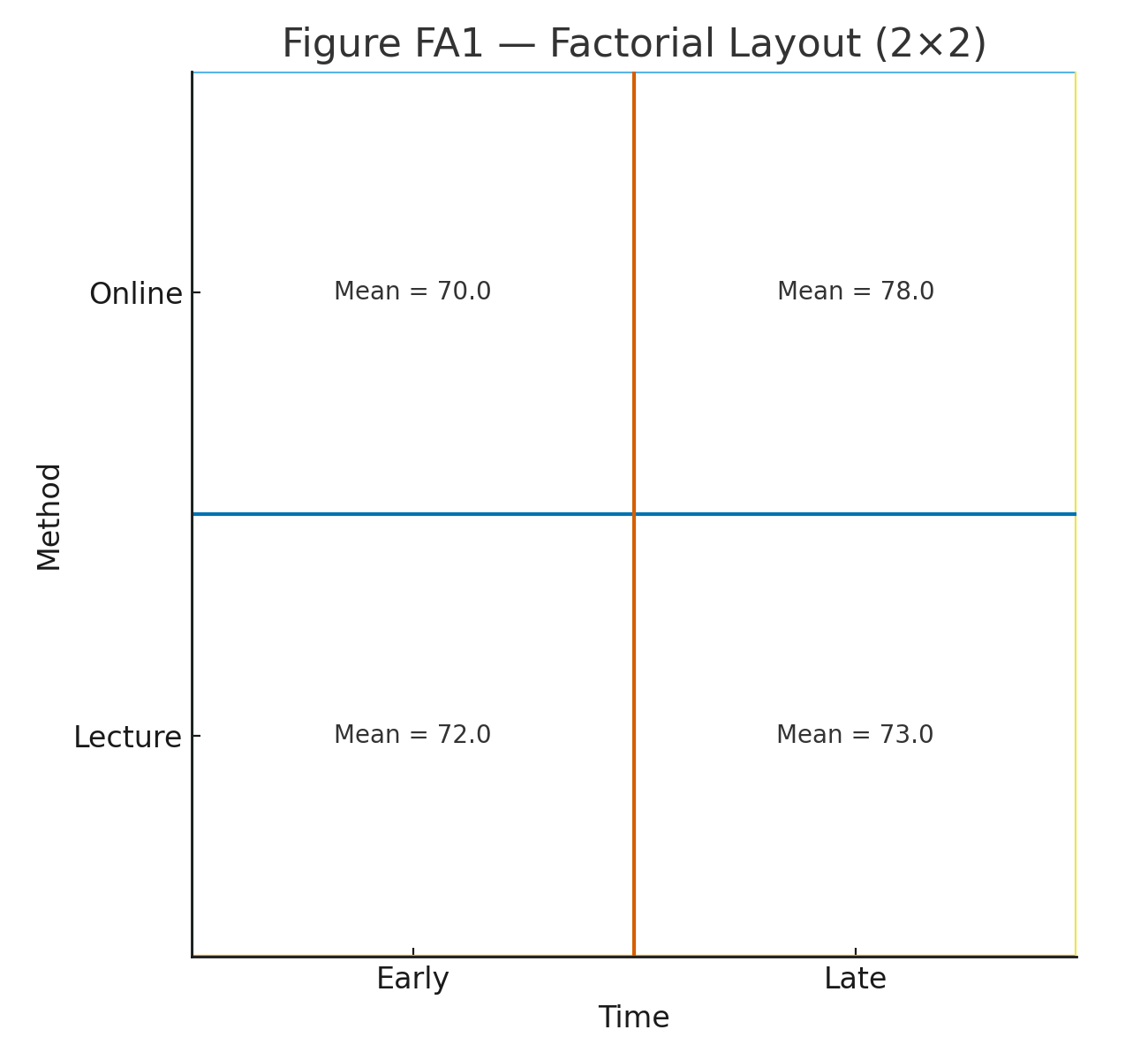
Figure 1: 2 × 2 layout (Method × Time).
Data
Scores by cell (five students per cell):
| Method | Time | Scores | Cell Mean | ||||
|---|---|---|---|---|---|---|---|
| Lecture | Early | 68 | 68 | 70 | 72 | 72 | 70.0 |
| Lecture | Late | 76 | 76 | 78 | 80 | 80 | 78.0 |
| Online | Early | 70 | 70 | 72 | 74 | 74 | 72.0 |
| Online | Late | 71 | 71 | 73 | 75 | 75 | 73.0 |
Within each cell the sample variance is 4 (SD = 2), so the within-cell sum of squares is \((n-1)s^2 = 4\times4 = 16\) per cell.
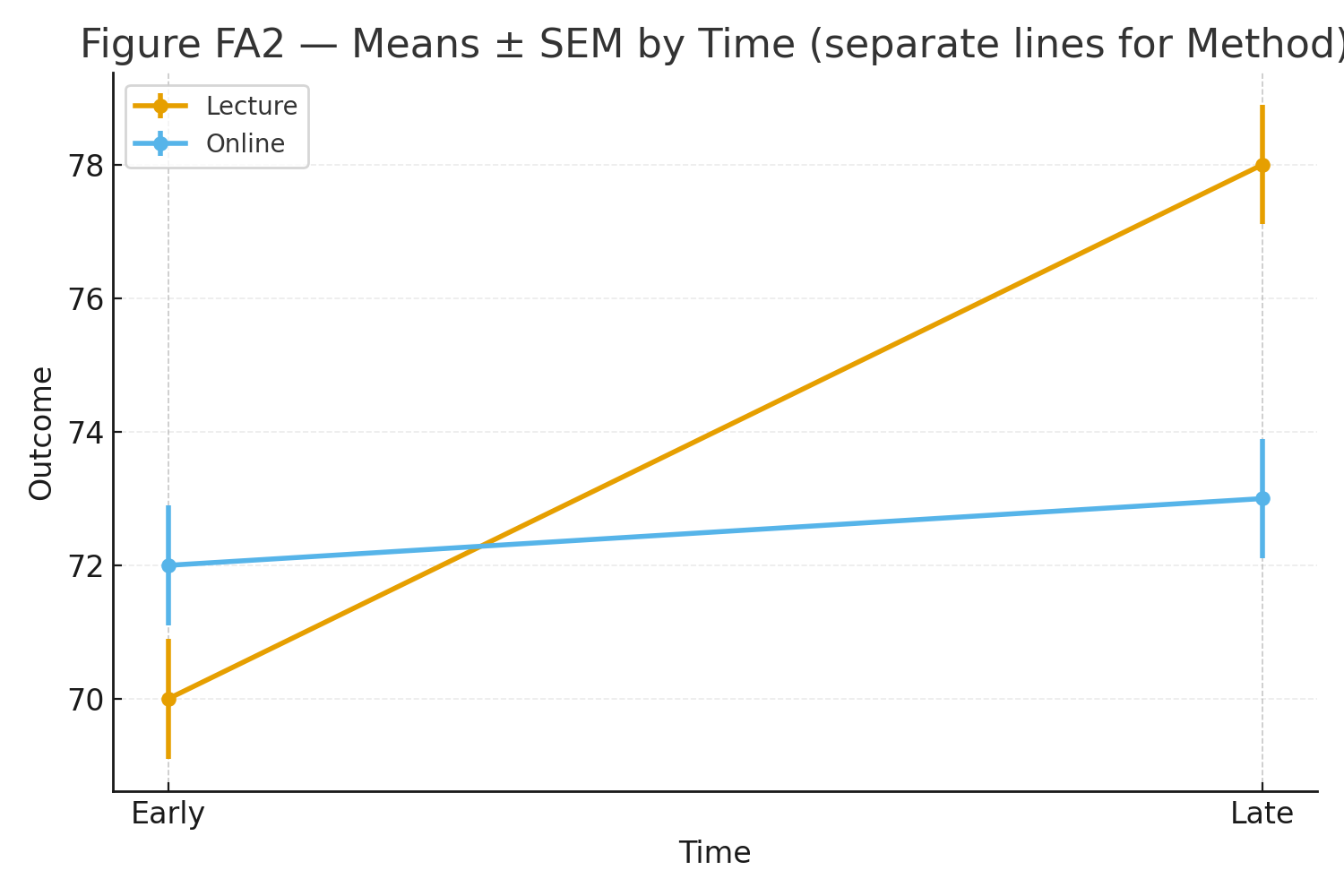
Figure 2: Means with SEM by Time, separate lines for Method.
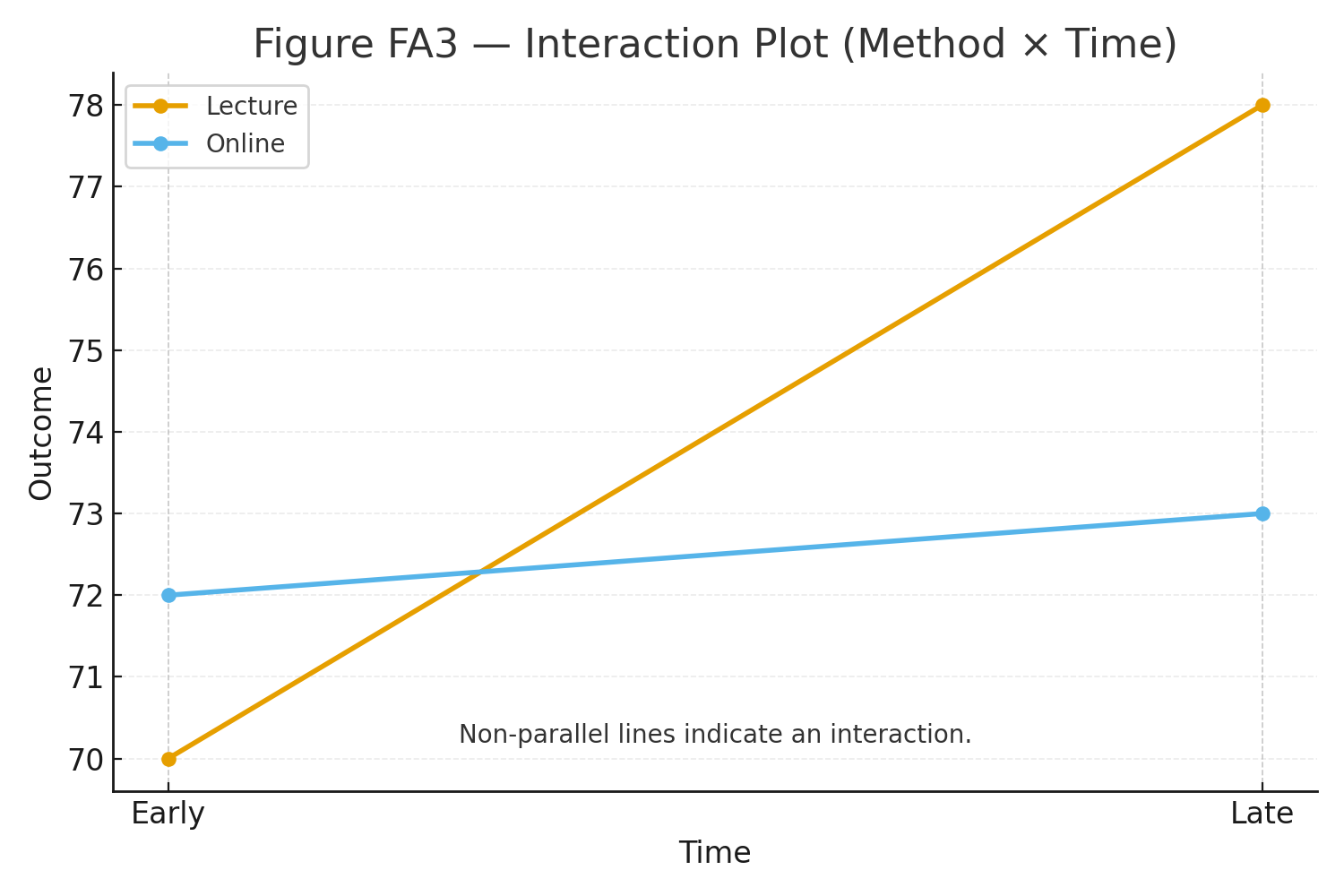
Figure 3: Interaction plot (Lecture rises sharply; Online nearly flat).
Step 1 — Marginal Means and Grand Mean
Cell means: \[ \bar X_{\text{Lecture,Early}}=70,\; \bar X_{\text{Lecture,Late}}=78,\; \bar X_{\text{Online,Early}}=72,\; \bar X_{\text{Online,Late}}=73. \] Marginal means: \[ \bar X_{\text{Lecture}}=\frac{70+78}{2}=74,\quad \bar X_{\text{Online}}=\frac{72+73}{2}=72.5; \qquad \bar X_{\text{Early}}=\frac{70+72}{2}=71,\quad \bar X_{\text{Late}}=\frac{78+73}{2}=75.5. \] Grand mean: \[ \bar X=\frac{70+78+72+73}{4}=73.25. \]
Step 2 — Sums of Squares (Between)
Balanced design formulas (with \(n\) per cell, \(a=b=2\)):
- \(SS_A = nb \sum_a(\bar X_{a\cdot}-\bar X)^2\), here \(nb=10\).
- \(SS_B = na \sum_b(\bar X_{\cdot b}-\bar X)^2\), here \(na=10\).
- \(SS_{AB} = n \sum_{a,b}\big(\bar X_{ab}-\bar X_{a\cdot}-\bar X_{\cdot b}+\bar X\big)^2\), here \(n=5\).
Compute each term:
Factor A (Method): \[ \begin{aligned} SS_A &= 10\Big[(74-73.25)^2 + (72.5-73.25)^2\Big]\\ &= 10\big[0.75^2 + (-0.75)^2\big] = 10(0.5625+0.5625)=\mathbf{11.25}. \end{aligned} \]
Factor B (Time): \[ \begin{aligned} SS_B &= 10\Big[(71-73.25)^2 + (75.5-73.25)^2\Big]\\ &= 10\big[(-2.25)^2 + (2.25)^2\big] = 10(5.0625+5.0625)=\mathbf{101.25}. \end{aligned} \]
Interaction \(A\times B\): For each cell compute \(d_{ab}=\bar X_{ab}-\bar X_{a\cdot}-\bar X_{\cdot b}+\bar X\). Here each \(d_{ab}=\pm1.75\) so \(d_{ab}^2=3.0625\) and there are four cells: \[ SS_{AB}=5\times(4\times3.0625)=\mathbf{61.25}. \]
Step 3 — Within-Group (Error) and Total SS
Within each cell, \((n-1)s^2=16\). With 4 cells: \[ SS_{\text{within}}=\mathbf{64.00}. \]
Total: \[ SS_{\text{total}}=SS_A+SS_B+SS_{AB}+SS_{\text{within}} =11.25+101.25+61.25+64.00=\mathbf{238.75}. \]
Step 4 — Degrees of Freedom & Mean Squares
\[ \begin{aligned} &df_A=a-1=1,\quad df_B=b-1=1,\quad df_{AB}=(a-1)(b-1)=1,\\ &df_{\text{within}}=N-ab=20-4=\mathbf{16},\quad df_{\text{total}}=N-1=19. \end{aligned} \] \[ MS_A=\frac{11.25}{1}=11.25,\quad MS_B=\frac{101.25}{1}=101.25,\quad MS_{AB}=\frac{61.25}{1}=61.25,\quad MS_{\text{within}}=\frac{64.00}{16}=\mathbf{4.00}. \]
Step 5 — F Tests & p-values
\[ F_A=\frac{MS_A}{MS_{\text{within}}}=\frac{11.25}{4}= \mathbf{2.8125},\qquad F_B=\frac{MS_B}{MS_{\text{within}}}=\frac{101.25}{4}= \mathbf{25.3125},\qquad F_{AB}=\frac{MS_{AB}}{MS_{\text{within}}}=\frac{61.25}{4}= \mathbf{15.3125}. \] With \(df_1=1\), \(df_2=16\): \[ p_A \approx 0.11\;(\text{n.s.}),\quad p_B < 0.001,\quad p_{AB} \approx 0.001. \]
ANOVA Summary Table
| Source | SS | df | MS | F | p |
|---|---|---|---|---|---|
| Method (A) | 11.25 | 1 | 11.25 | 2.8125 | ≈ 0.11 |
| Time (B) | 101.25 | 1 | 101.25 | 25.3125 | < 0.001 |
| A × B | 61.25 | 1 | 61.25 | 15.3125 | ≈ 0.001 |
| Within (Error) | 64.00 | 16 | 4.00 | — | — |
| Total | 238.75 | 19 | — | — | — |
Interpretation
Main effect of Time (B) is significant: Late > Early on average. Main effect of Method (A) is not significant at conventional levels. The interaction (A × B) is significant: Lecture improves markedly from Early→Late, while Online changes little—non-parallel lines in the interaction plot.
Figure 4: Interaction plot highlighting non-parallel lines.
Assumptions (checklist)
- Independence of observations within and across cells.
- Approximately normal scores within each cell.
- Homogeneity of variances across cells (here, each cell variance ≈ 4).
Practice self-test quiz
In the space below, please find practice problems and self-test quizzes. For full access, please signup free.