

Mixed (Split-Plot) ANOVA
Goal. Test a between-subjects factor (Group: Drug vs. Placebo) and a within-subjects factor (Time: Weeks 1–3), plus their interaction, on exam scores.
Design & Experiment
- Between-subjects factor: Group = {Drug, Placebo}
- Within-subjects factor: Time = {Week 1, Week 2, Week 3}
- Balanced: 8 participants per group (\(s_g=8\)), 3 repeated measures per participant (\(k=3\)).
Participants are randomly assigned to Drug or Placebo. The same exam is given at Week 1, Week 2, and Week 3.
Figure 1: Mixed design layout (Drug vs Placebo × Weeks 1–3).
Data
Group: Drug (8 participants × 3 weeks)
| Subject | W1 | W2 | W3 | Row sum | Row mean |
|---|---|---|---|---|---|
| D1 | 70 | 74 | 78 | 222 | 74.00 |
| D2 | 69 | 73 | 77 | 219 | 73.00 |
| D3 | 71 | 75 | 79 | 225 | 75.00 |
| D4 | 72 | 76 | 80 | 228 | 76.00 |
| D5 | 68 | 72 | 76 | 216 | 72.00 |
| D6 | 70 | 74 | 78 | 222 | 74.00 |
| D7 | 73 | 77 | 81 | 231 | 77.00 |
| D8 | 71 | 76 | 80 | 227 | 75.67 |
| Column sums | 564 | 597 | 629 | Group sum = 1790 | Group mean \( \bar X_{\text{Drug}} = 1790/24 = 74.5833 \) |
Group: Placebo (8 participants × 3 weeks)
| Subject | W1 | W2 | W3 | Row sum | Row mean |
|---|---|---|---|---|---|
| P1 | 70 | 71 | 72 | 213 | 71.00 |
| P2 | 69 | 70 | 71 | 210 | 70.00 |
| P3 | 71 | 72 | 73 | 216 | 72.00 |
| P4 | 72 | 73 | 74 | 219 | 73.00 |
| P5 | 68 | 69 | 70 | 207 | 69.00 |
| P6 | 70 | 71 | 72 | 213 | 71.00 |
| P7 | 69 | 70 | 71 | 210 | 70.00 |
| P8 | 71 | 72 | 73 | 216 | 72.00 |
| Column sums | 560 | 568 | 576 | Group sum = 1704 | Group mean \( \bar X_{\text{Plac}} = 1704/24 = 71.0000 \) |
Totals. Grand sum = 1790 + 1704 = 3494, total observations \(N = 16\times3 = 48\), grand mean \( \bar X = 3494/48 = 72.7917\).
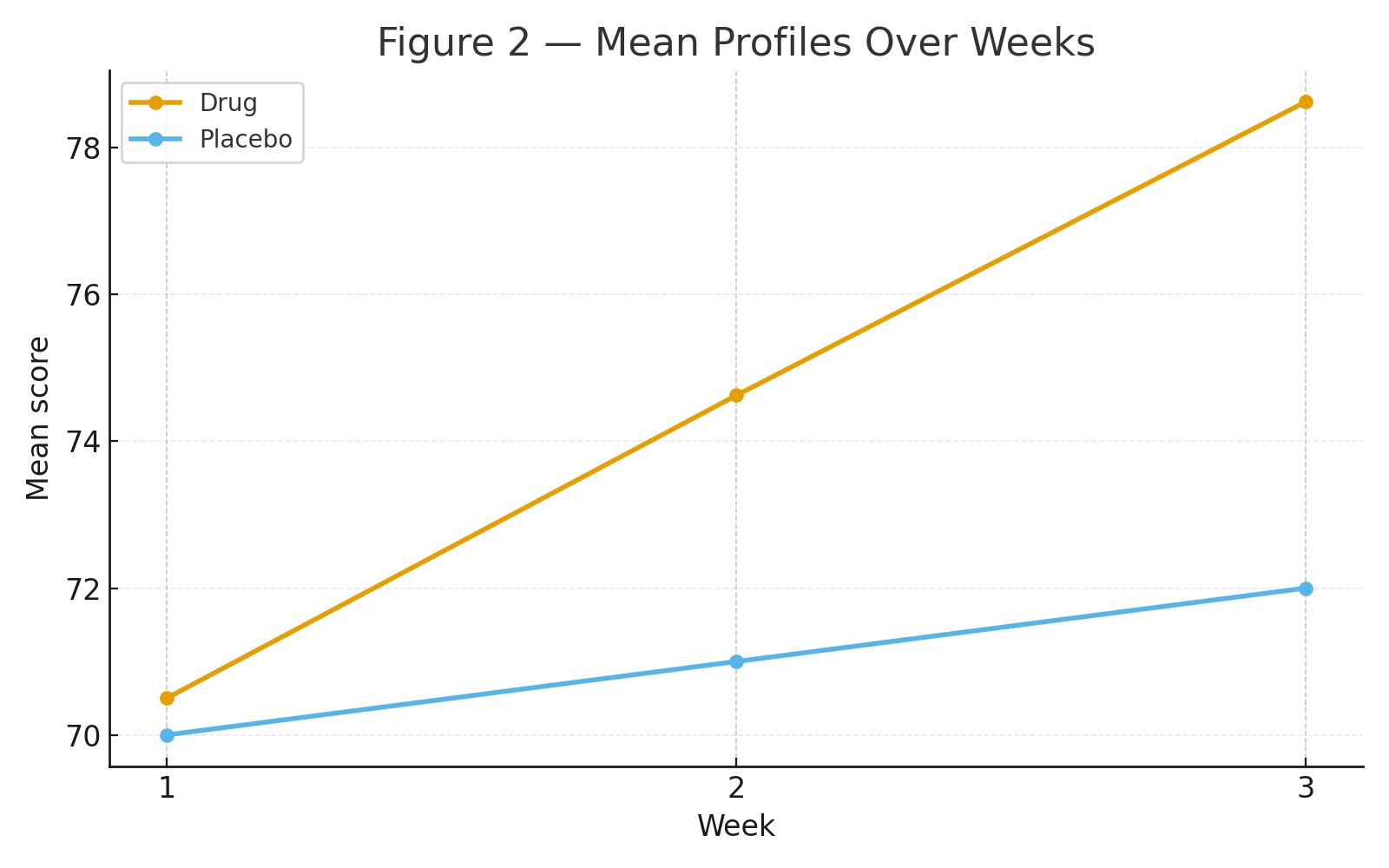
Figure 2: Mean profiles over weeks (Drug rises sharply; Placebo ~ flat).
Step 1 — Marginal Means
By Time (across both groups; 16 participants each week): \[ \bar X_{\text{W1}}=\tfrac{1124}{16}=70.2500,\qquad \bar X_{\text{W2}}=\tfrac{1165}{16}=72.8125,\qquad \bar X_{\text{W3}}=\tfrac{1205}{16}=75.3125, \] where column sums are \(1124, 1165, 1205\).
By Group (across all weeks): \[ \bar X_{\text{Drug}}=74.5833,\qquad \bar X_{\text{Placebo}}=71.0000. \]
Step 2 — Sums of Squares (SS)
Decompose total variability into Between-Subjects and Within-Subjects parts.
2A. Total
\[ SS_{\text{total}}=\sum (X_{igt}-\bar X)^2=\mathbf{527.9167}. \]
2B. Between-Subjects
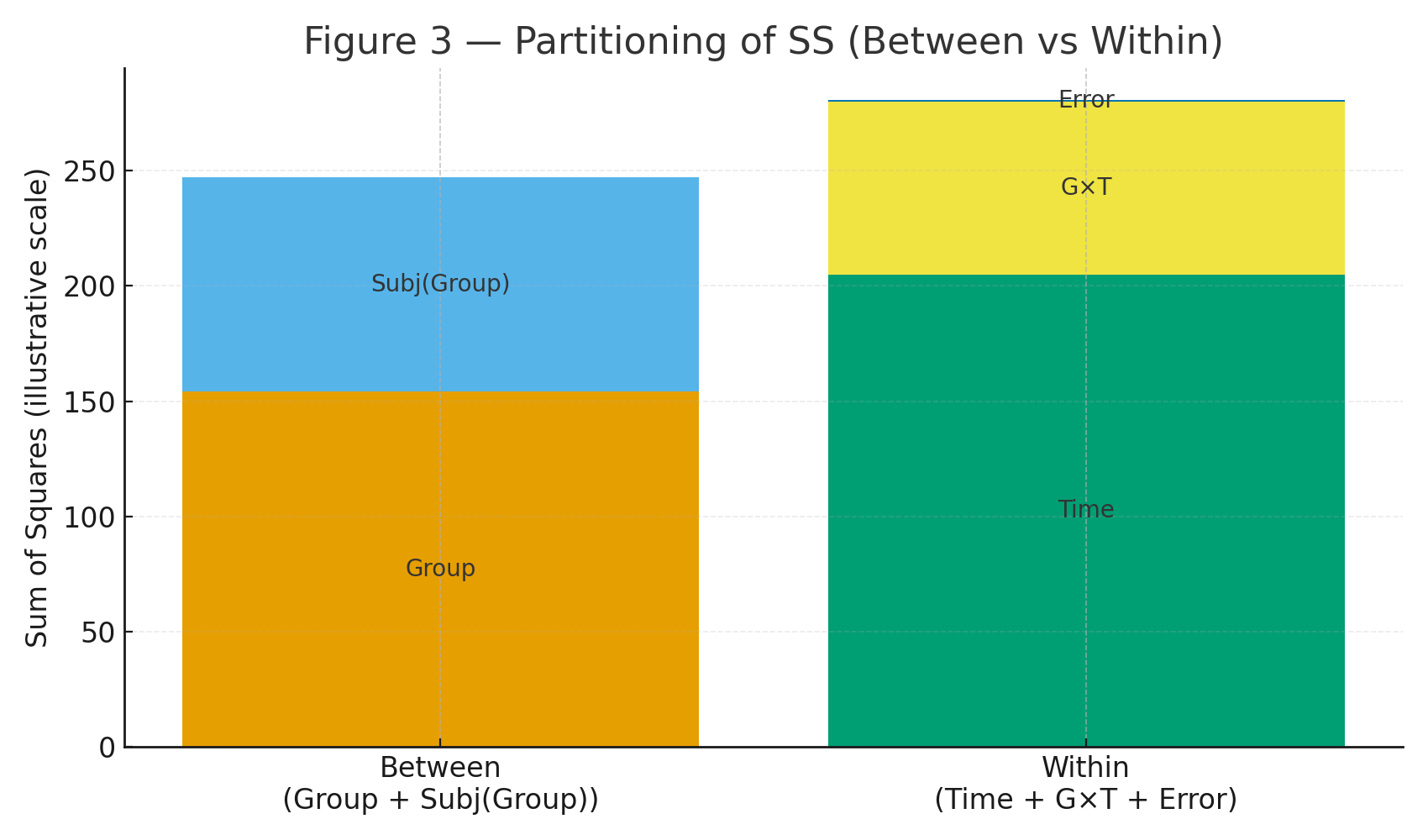
Let each subject’s mean be \(\bar X_{i\cdot}\). Then \[ SS_{\text{BS-total}}=k\sum_{i=1}^{16}(\bar X_{i\cdot}-\bar X)^2=\mathbf{247.2500}. \] Split into Group and Subjects-within-Group: \[ SS_{\text{Group}}=k\sum_{g} n_g(\bar X_{g\cdot\cdot}-\bar X)^2=\mathbf{154.0833}, \] \[ SS_{\text{Subj}(g)}=k\sum_{i\in g}(\bar X_{i\cdot}-\bar X_{g\cdot\cdot})^2=\mathbf{93.1667}. \]
2C. Within-Subjects
\(SS_{\text{WS-total}}=SS_{\text{total}}-SS_{\text{BS-total}}=\mathbf{280.6667}.\)
Decompose into Time, Group×Time, and residual Error: \[ SS_{\text{Time}}=s\sum_{t}(\bar X_{\cdot\cdot t}-\bar X)^2=\mathbf{205.0417}, \] \[ SS_{\text{Group}\times\text{Time}} =\sum_{g,t} n_g\Big(\bar X_{g\cdot t}-\bar X_{g\cdot\cdot}-\bar X_{\cdot\cdot t}+\bar X\Big)^2 =\mathbf{75.0417}, \] \[ SS_{\text{Error(WS)}}=SS_{\text{WS-total}}-SS_{\text{Time}}-SS_{\text{G}\times\text{T}} =\mathbf{0.5833}. \]
Figure 3: Partitioning diagram (Between: Group + Subj(Group); Within: Time + G×T + Error).
Step 3 — Degrees of Freedom (df) & Mean Squares (MS)
\[ \begin{aligned} &df_{\text{Group}}=g-1=1,\qquad df_{\text{Subj}(g)}=N_s-g=16-2=14,\\ &df_{\text{Time}}=k-1=2,\qquad df_{\text{G}\times\text{T}}=(g-1)(k-1)=2,\\ &df_{\text{Error(WS)}}=(N_s-g)(k-1)=(16-2)\times2=28,\\ &df_{\text{Total}}=Nk-1=48-1=47. \end{aligned} \]
\[ \begin{aligned} &MS_{\text{Group}}=\frac{SS_{\text{Group}}}{df_{\text{Group}}}= \frac{154.0833}{1}= \mathbf{154.0833},\qquad MS_{\text{Subj}(g)}=\frac{93.1667}{14}= \mathbf{6.6548},\\ &MS_{\text{Time}}=\frac{205.0417}{2}= \mathbf{102.5208},\qquad MS_{\text{G}\times\text{T}}=\frac{75.0417}{2}= \mathbf{37.5208},\\ &MS_{\text{Error(WS)}}=\frac{0.5833}{28}= \mathbf{0.02083}. \end{aligned} \]
Step 4 — F Tests & p-values
Between-subjects test: \[ F_{\text{Group}}=\frac{MS_{\text{Group}}}{MS_{\text{Subj}(g)}}=\frac{154.0833}{6.6548}= \mathbf{23.1538}, \quad df=(1,14),\quad p\approx \mathbf{0.00028}. \]
Within-subjects tests: \[ F_{\text{Time}}=\frac{MS_{\text{Time}}}{MS_{\text{Error(WS)}}} =\frac{102.5208}{0.02083}= \mathbf{4921.0},\quad df=(2,28),\quad p\ll 10^{-20}. \] \[ F_{\text{G}\times\text{T}}=\frac{MS_{\text{G}\times\text{T}}}{MS_{\text{Error(WS)}}} =\frac{37.5208}{0.02083}= \mathbf{1801.0},\quad df=(2,28),\quad p\ll 10^{-20}. \]
Figure 4: F distributions with observed statistics marked.
Mixed ANOVA Summary Table
| Source | SS | df | MS | F | p |
|---|---|---|---|---|---|
| Between: Group | 154.0833 | 1 | 154.0833 | 23.1538 | 0.00028 |
| Between: Subjects within Group | 93.1667 | 14 | 6.6548 | — | — |
| Within: Time | 205.0417 | 2 | 102.5208 | 4921.0 | < 1e-20 |
| Within: Group × Time | 75.0417 | 2 | 37.5208 | 1801.0 | < 1e-20 |
| Within: Error (Subj×Time within Group) | 0.5833 | 28 | 0.02083 | — | — |
| Total | 527.9167 | 47 | — | — | — |
Interpretation
Group: Drug > Placebo overall (significant between-subjects effect).
Time: Scores increase across weeks (strong within-subjects effect).
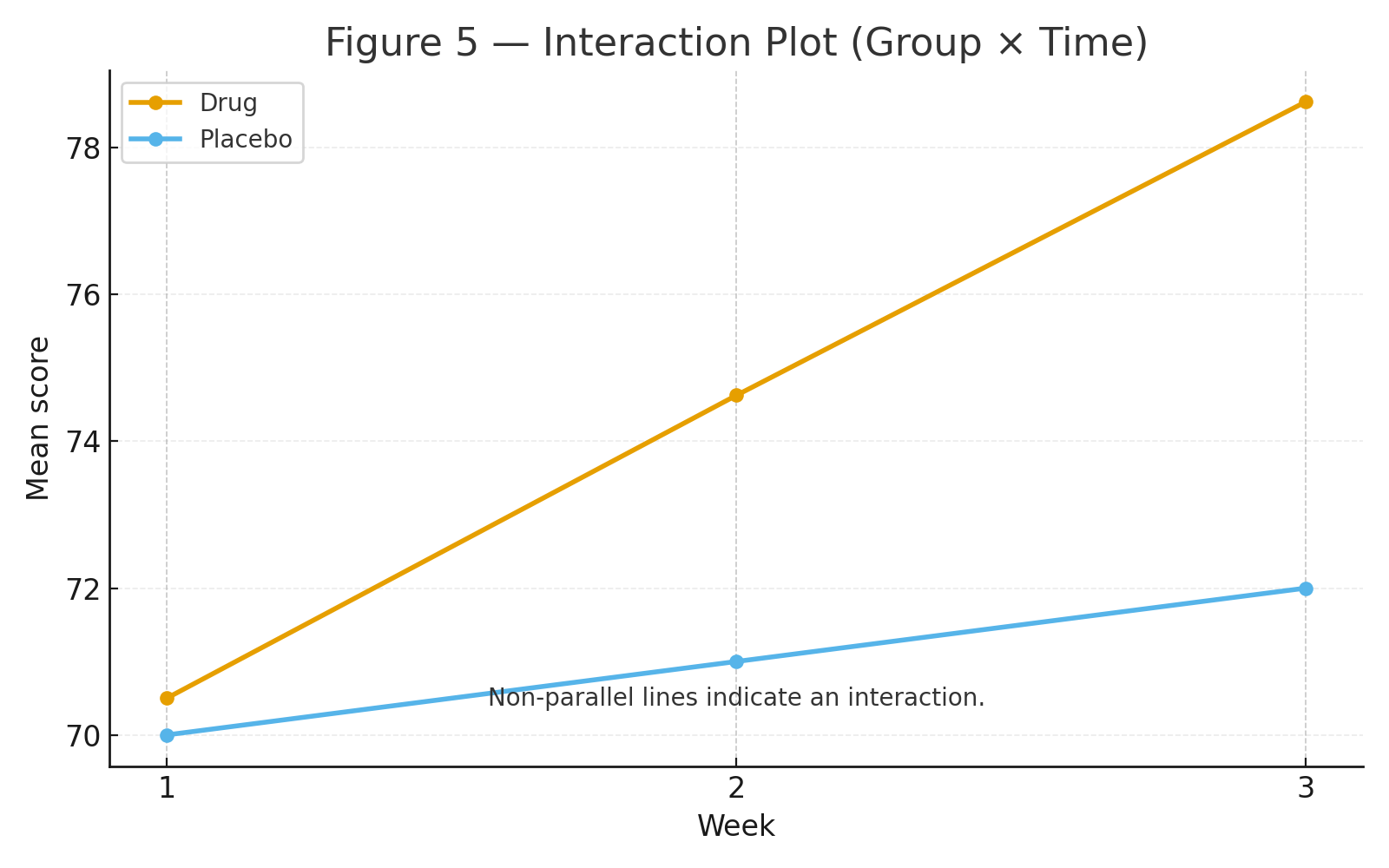
Group × Time: The Drug group improves sharply week-to-week while the Placebo group changes little (significant interaction).
Figure 5: Interaction plot showing non-parallel lines (Drug rising; Placebo flat).
Assumptions (checklist)
- Independence between subjects; correct grouping.
- Approximate normality within each Group×Time cell.
- Homogeneity of variance across groups (between-subjects).
- Sphericity for the within-subject factor Time (apply Greenhouse–Geisser/Huynh–Feldt corrections if violated).
Note: The residual within-subject error is intentionally small in this teaching dataset, so the Time and G×T F values are very large. Real data typically have larger residual variability.
Practice self-test quiz
In the space below, please find practice problems and self-test quizzes. For full access, please signup free.