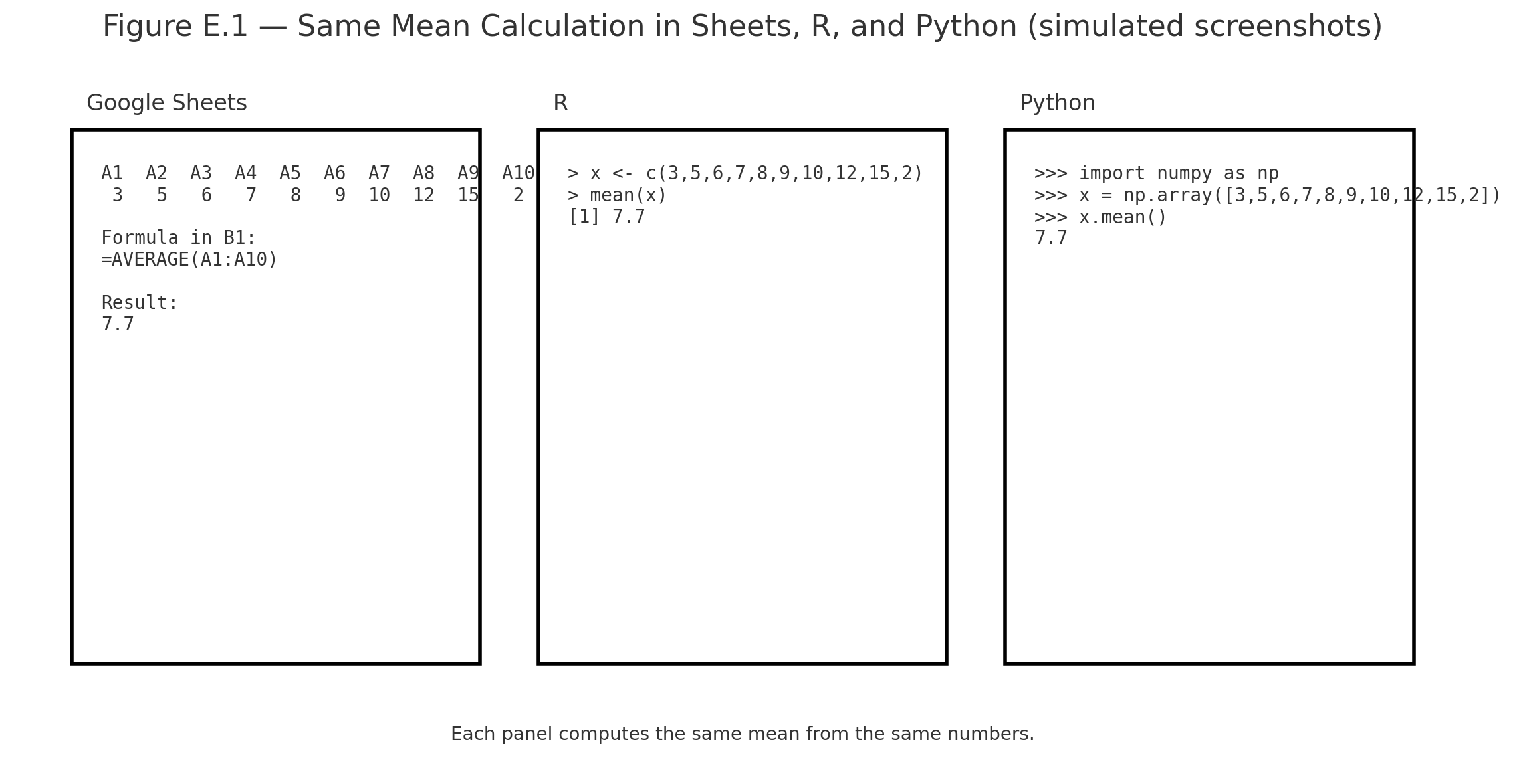
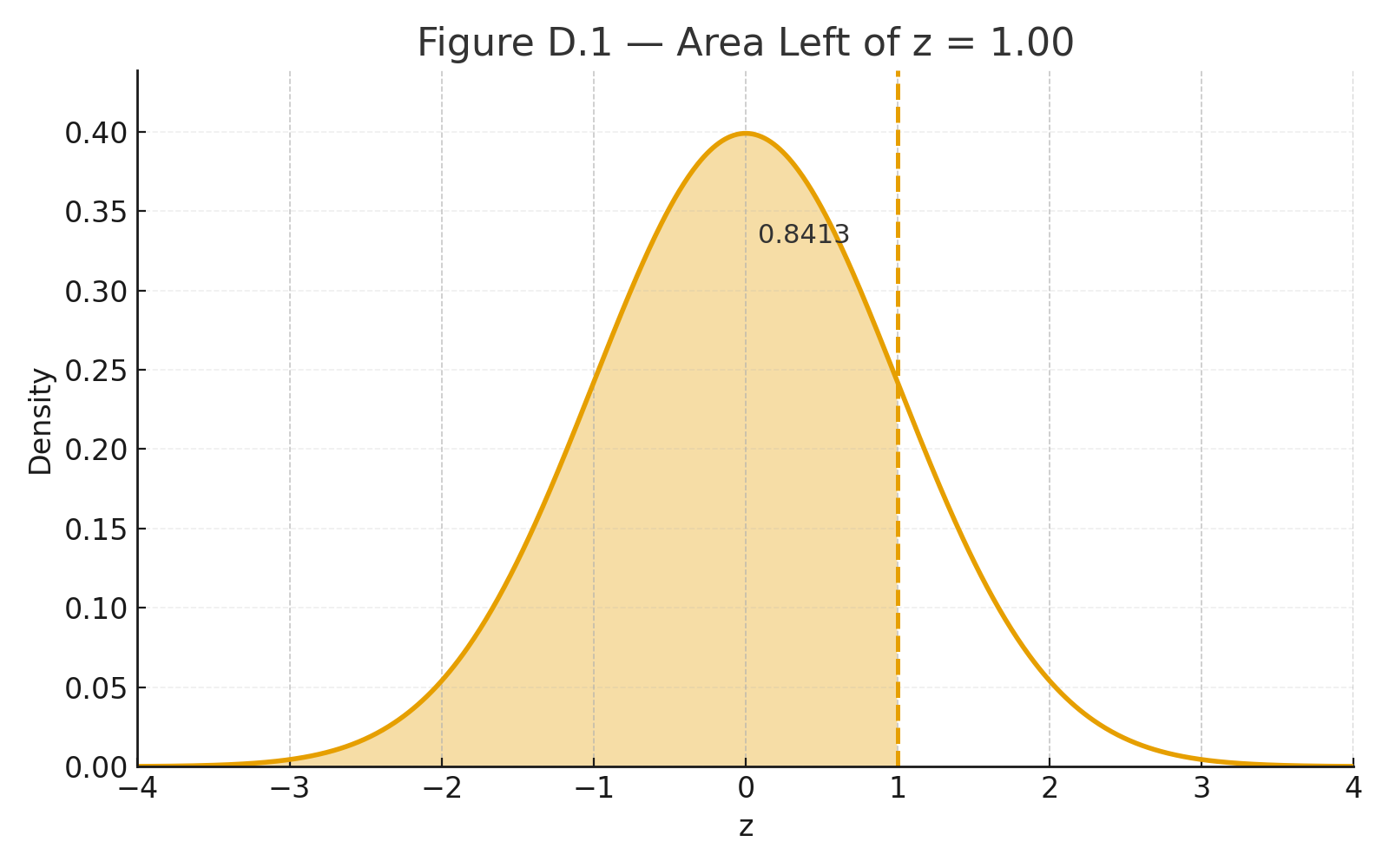
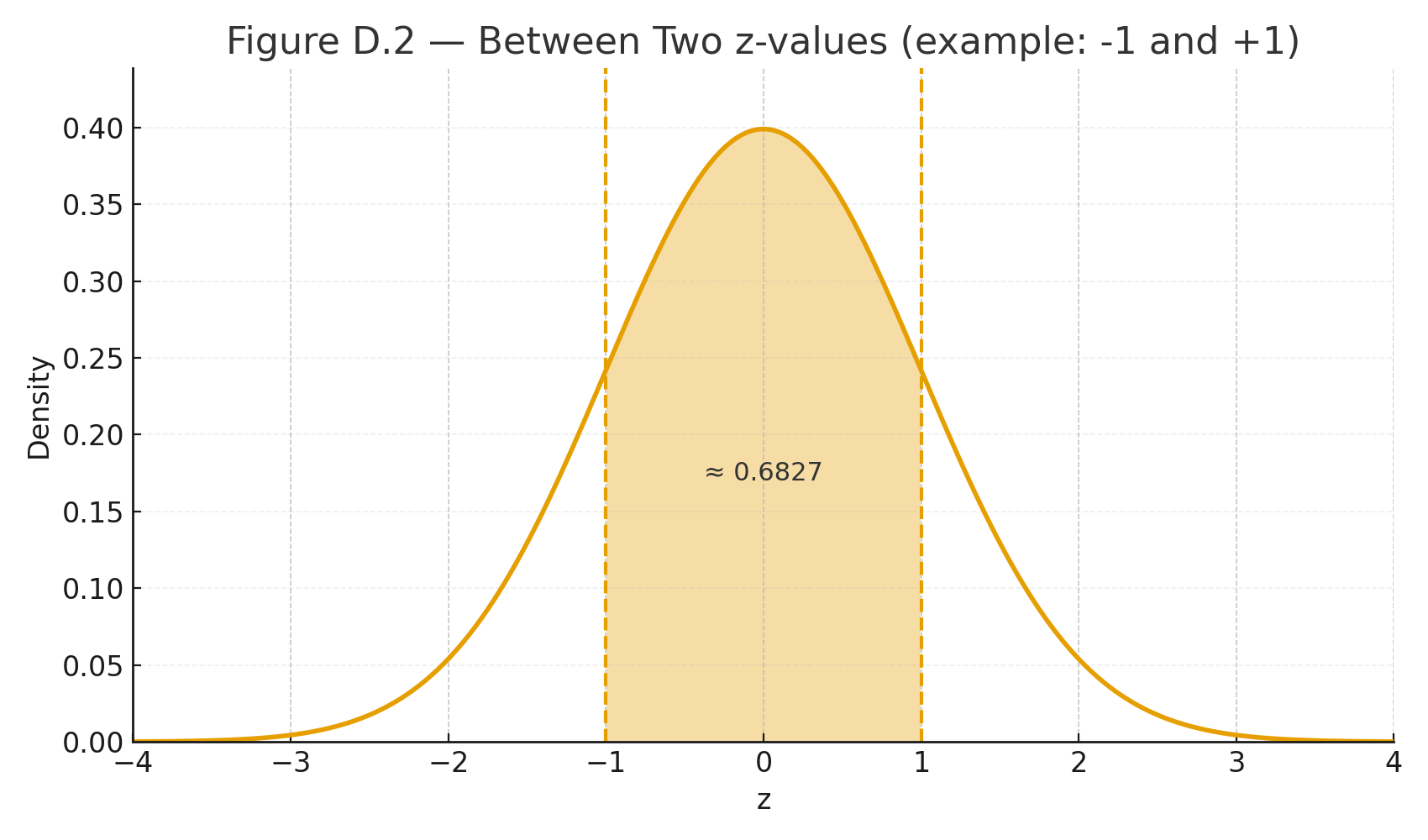
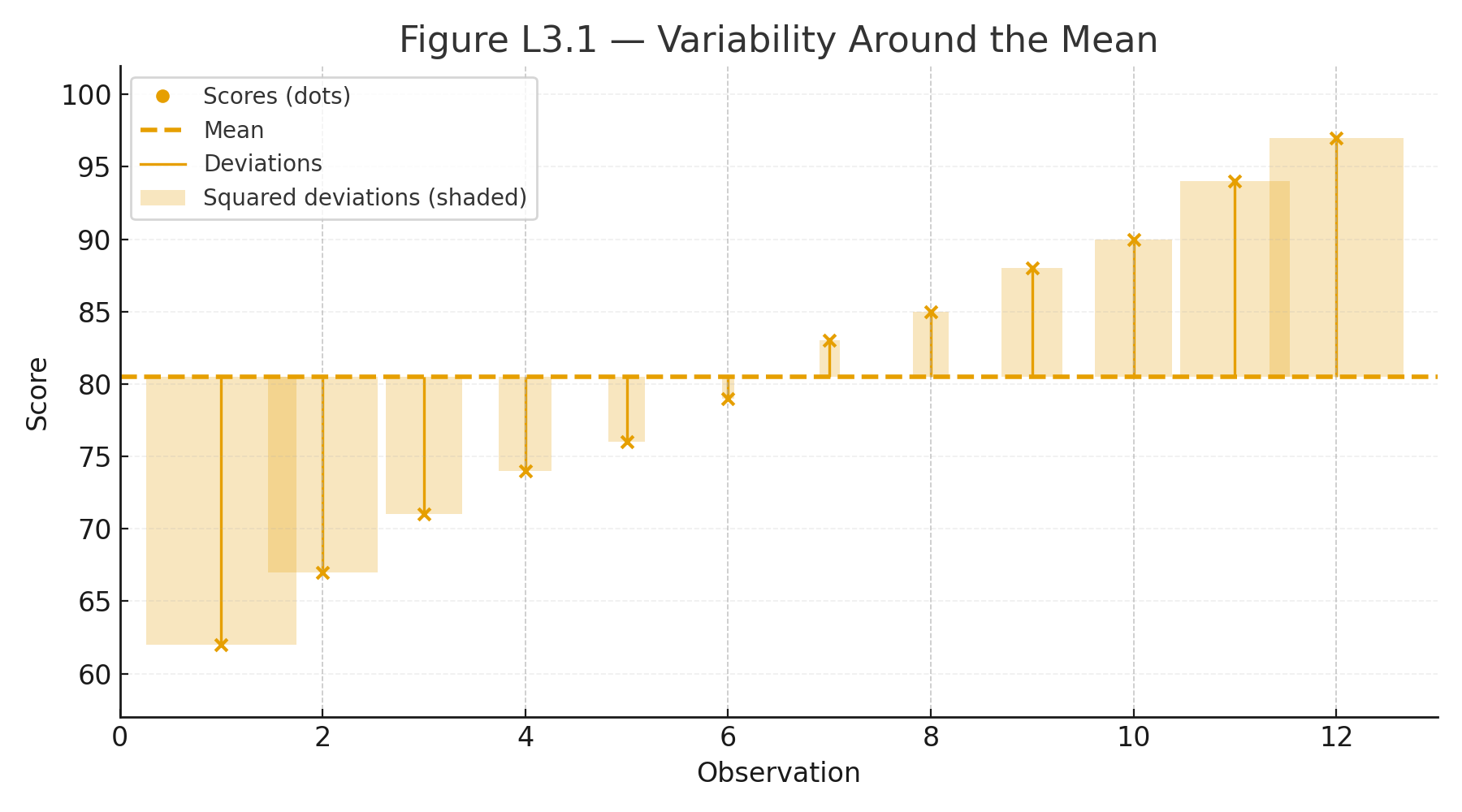
Appendix 8 — Glossary of Key Terms
Mean (average)
Sum of all scores divided by number of scores.
Example: (6 + 8 + 10) / 3 = 8.
Median
Middle score when data are ordered.
Example: For [5, 7, 8], median = 7.
Mode
Most frequent score.
Example: For [2, 3, 3, 5], mode = 3.
Variance (s²)
Average squared deviation from the mean.
Standard Deviation (s)
Square root of variance. Spread of scores around the mean.
Standard Error of the Mean (SEM)
How much sample means vary.
Formula: $$SEM = \frac{s}{\sqrt{n}}$$
t-test
Compares two means.
ANOVA (F-test)
Compares three or more means.
Post Hoc Test
Used after ANOVA to find which groups differ.
Correlation (r)
Strength and direction of a linear relationship. Range: –1 to +1.
Regression
Equation that predicts Y from X.
Example: $$\hat{Y} = a + bX$$
Chi-square (χ²)
Test for categorical data (counts).
Degrees of Freedom (df)
Independent pieces of information in a test.
p-value
Probability of getting the observed result (or more extreme) if the null hypothesis is true.
📱 QR: Interactive glossary (search symbols, formulas, definitions)
Practice self-test quiz
In the space below, please find practice problems and self-test quizzes. For full access, please signup free.