Lesson 15 — Resampling and Simulation
Classical statistics uses formulas and tables.
Modern computing gives us another way: resampling and simulation.
Instead of relying only on theory, we let the computer generate thousands of samples and see what happens.
Bootstrapping
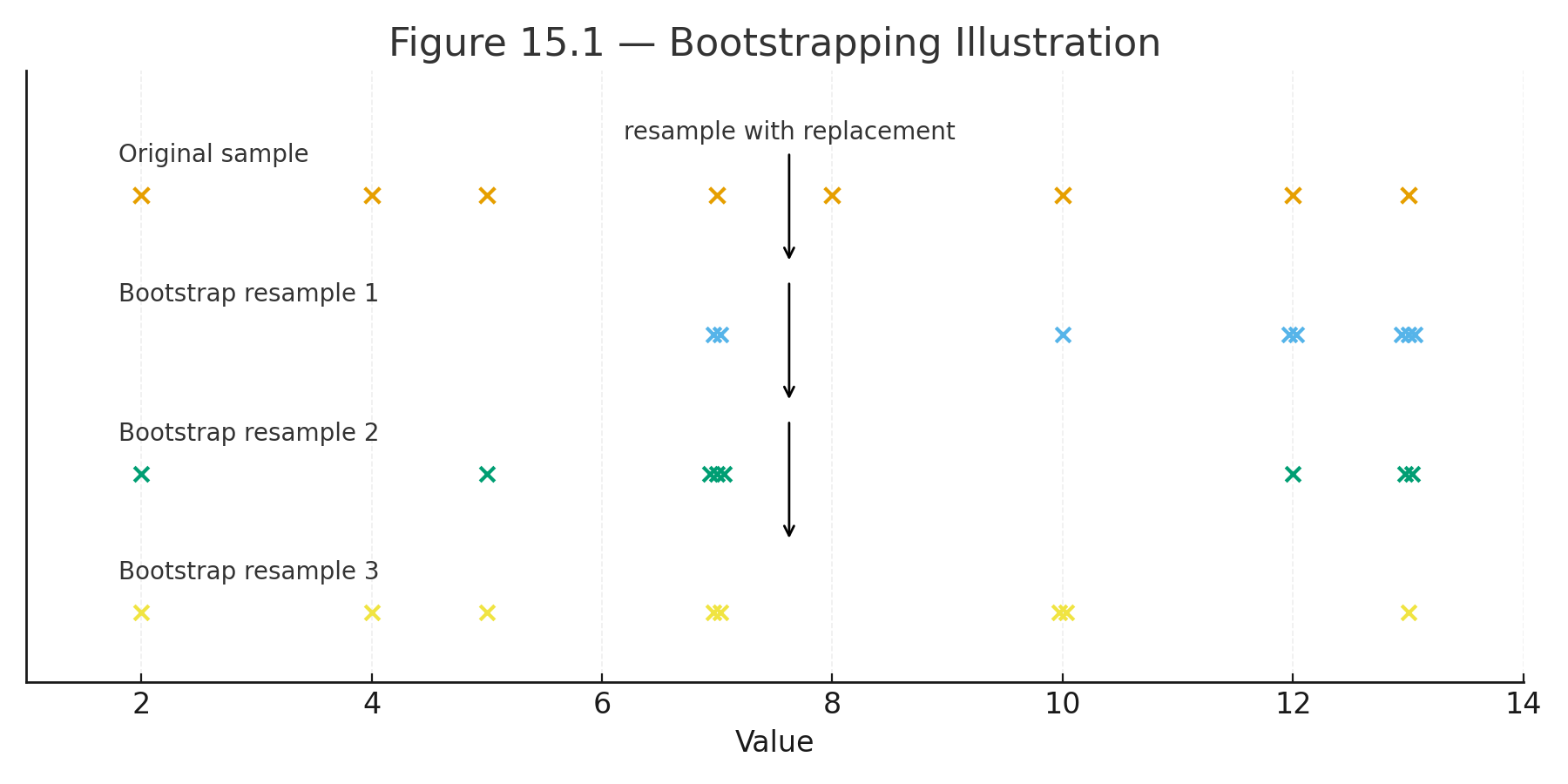
Bootstrapping means resampling with replacement from the original data.
Steps:
- Take a sample of size $$n$$ from the data (with replacement).
- Compute the statistic (mean, median, correlation).
- Repeat thousands of times.
- Use the distribution of resampled statistics to estimate confidence intervals.
Example:
Data = [5, 6, 7, 9].
Resample 1000 times, compute mean each time.
The distribution of means gives an estimate of the true mean’s variability.
Randomization (Permutation) Tests
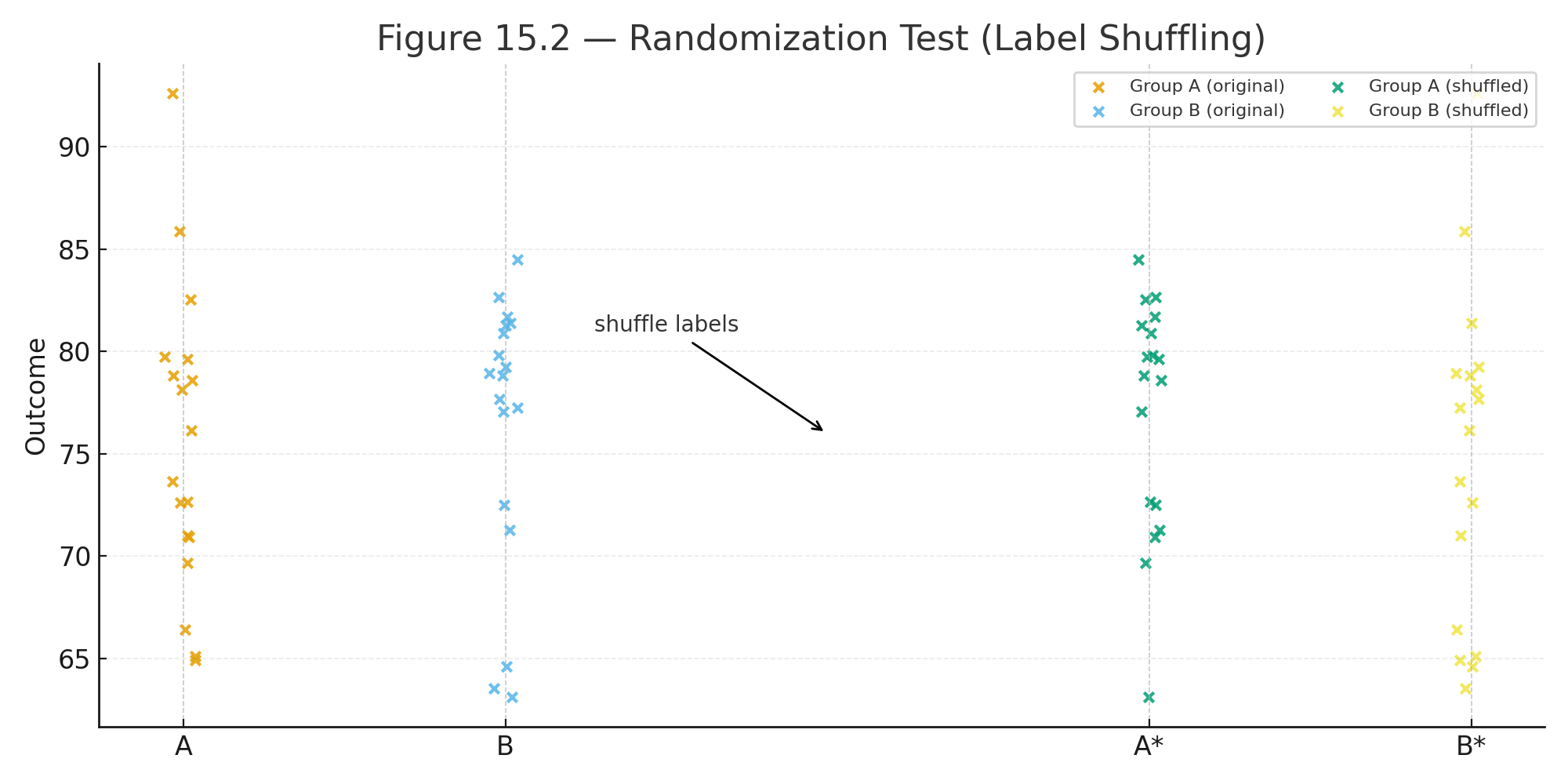
Used to test hypotheses by shuffling labels.
Steps:
- Combine all data.
- Randomly assign to groups.
- Compute the difference in means.
- Repeat thousands of times.
- Compare the observed difference to this distribution.
This shows whether the observed effect could be due to chance.
Monte Carlo Simulation
Monte Carlo methods use random numbers to model complex processes.
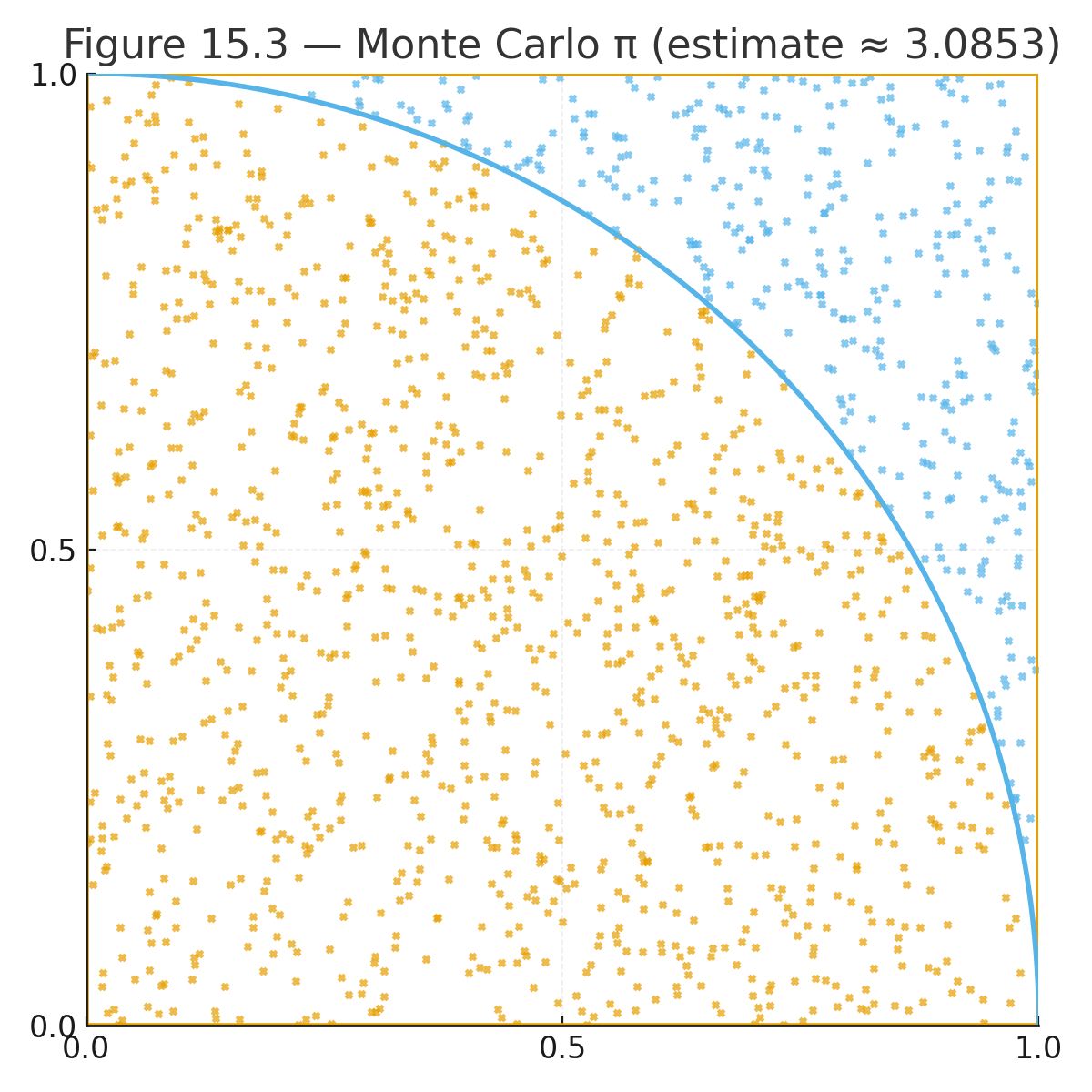
Example: Estimating $$\pi$$.
- Randomly throw points into a square.
- Count how many fall inside the circle quarter.
- $$\pi \approx 4 \times \tfrac{\text{inside circle}}{\text{total points}}$$.
Why Resampling Works
Resampling uses the data itself as a model of the population.
It avoids assumptions (like normality) and adapts to modern computing power.
Visuals
Figure 15.1 — Bootstrapping illustration: resampling from a small dataset with replacement.
Figure 15.2 — Randomization test: labels shuffled between groups.
Figure 15.3 — Monte Carlo: random points filling a square and a quarter circle.
Why This Matters
Resampling and simulation show students that statistics is not only about formulas.
Computers allow us to see probability in action.
This approach prepares students for data science, where simulation is as important as theory.
Practice self-test quiz
In the space below, please find practice problems and self-test quizzes. For full access, please signup free.