Students
For Students: How to Use statisticstextbook.com
A simple guide for starting, studying in order, and reviewing.
Audience: Pre-college and high school students
1. What This Site Is
statisticstextbook.com is a free, page-by-page statistics textbook. You can read it in order like a print book, or use it as a reference when you need help with a topic.
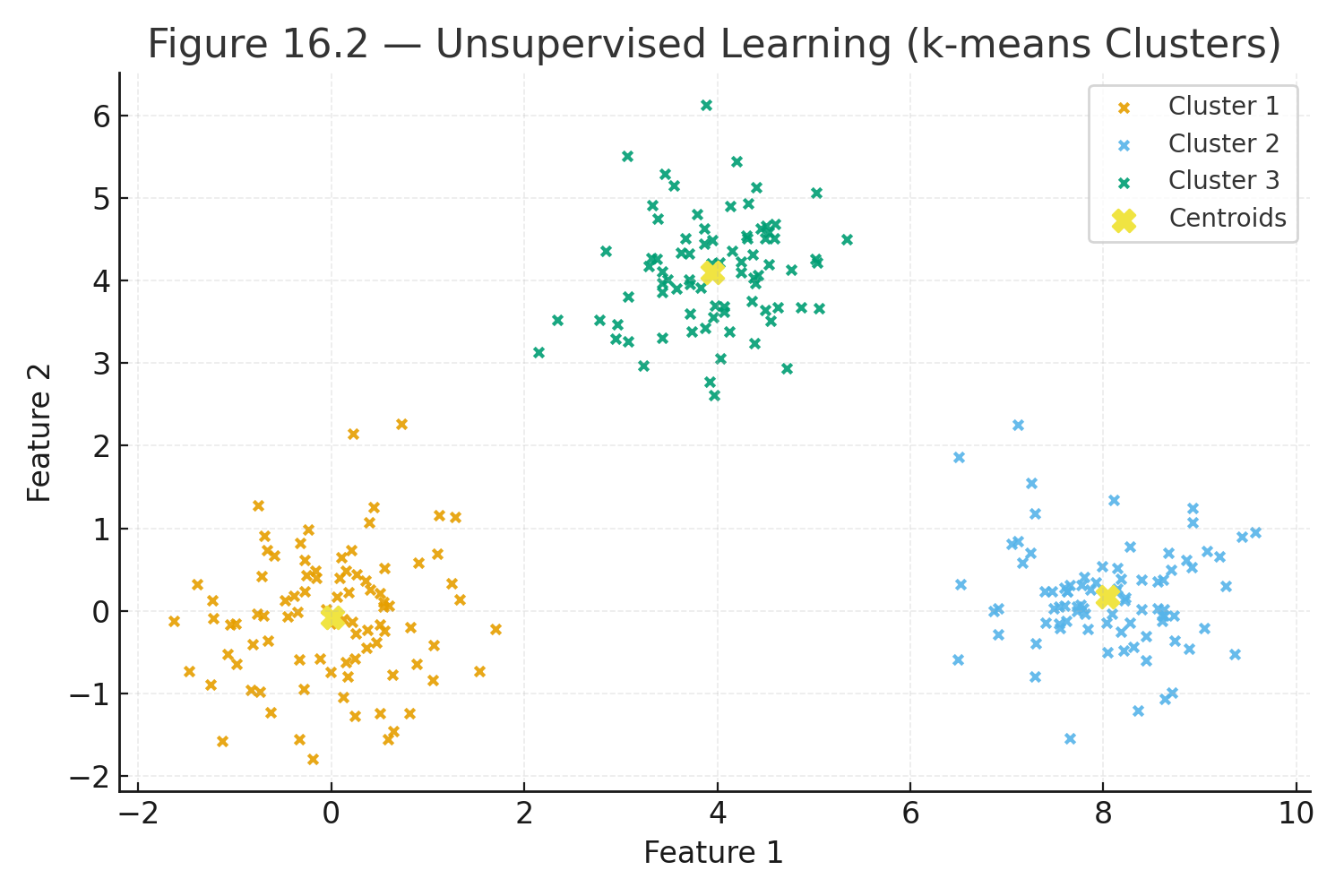
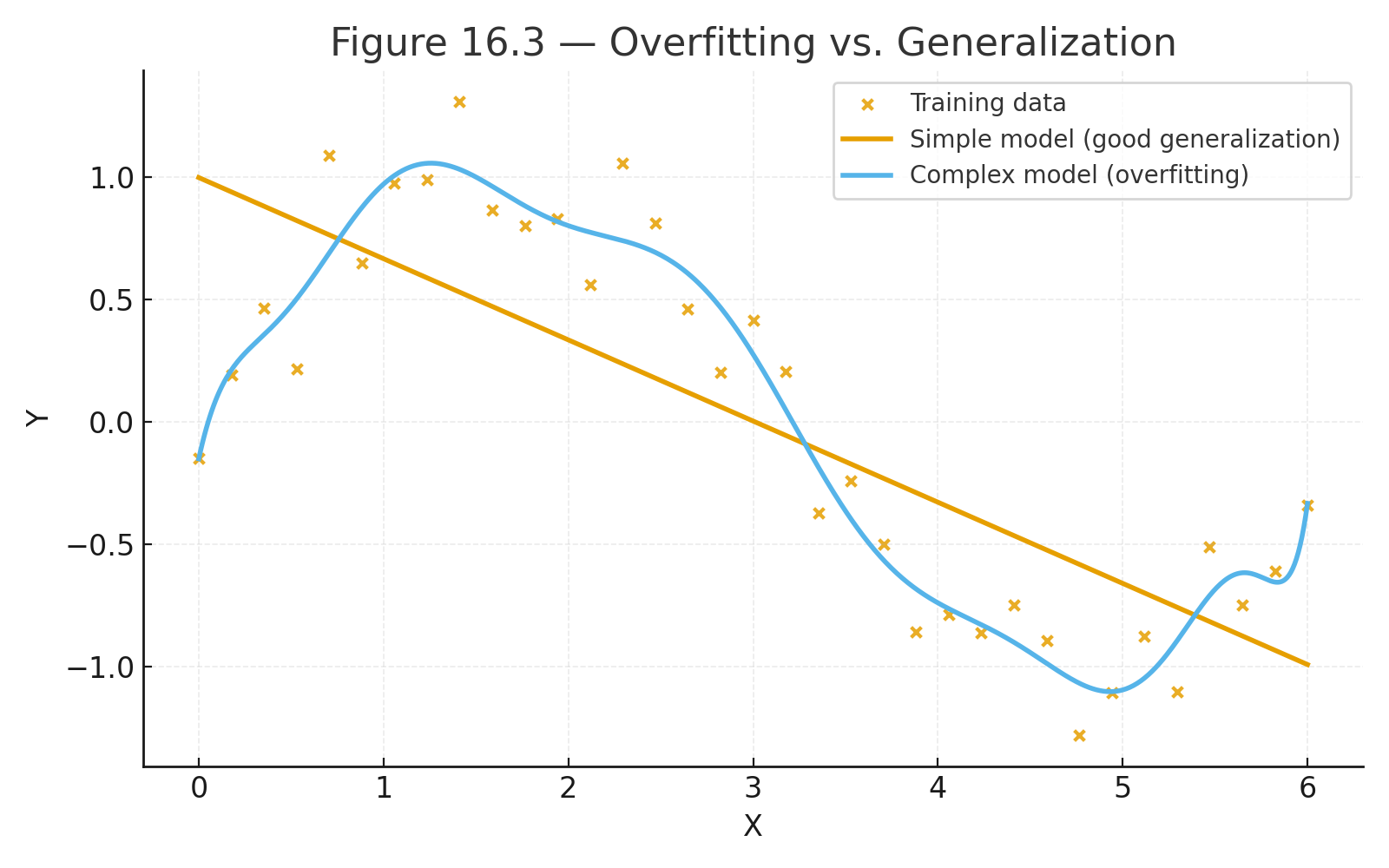
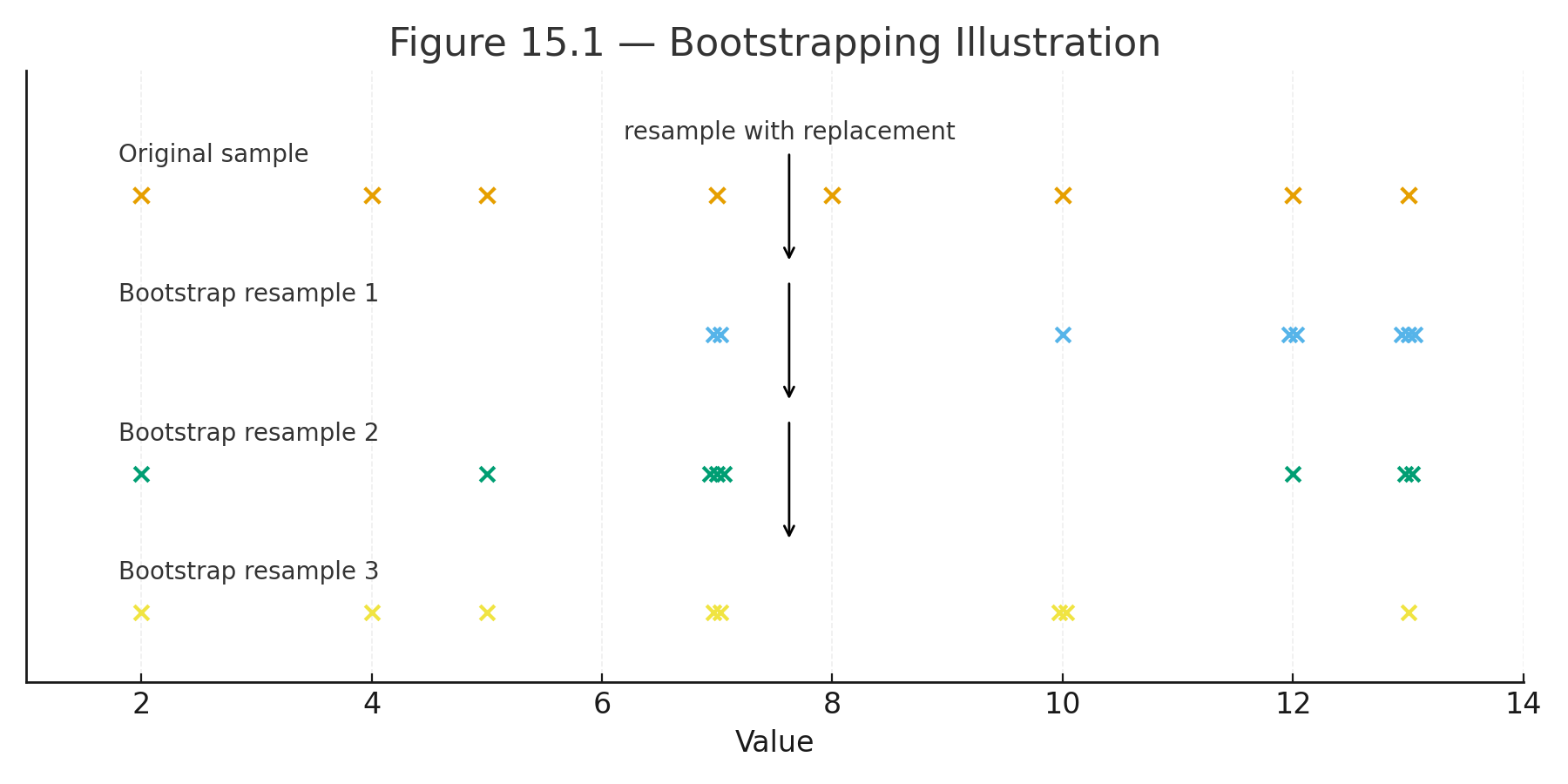
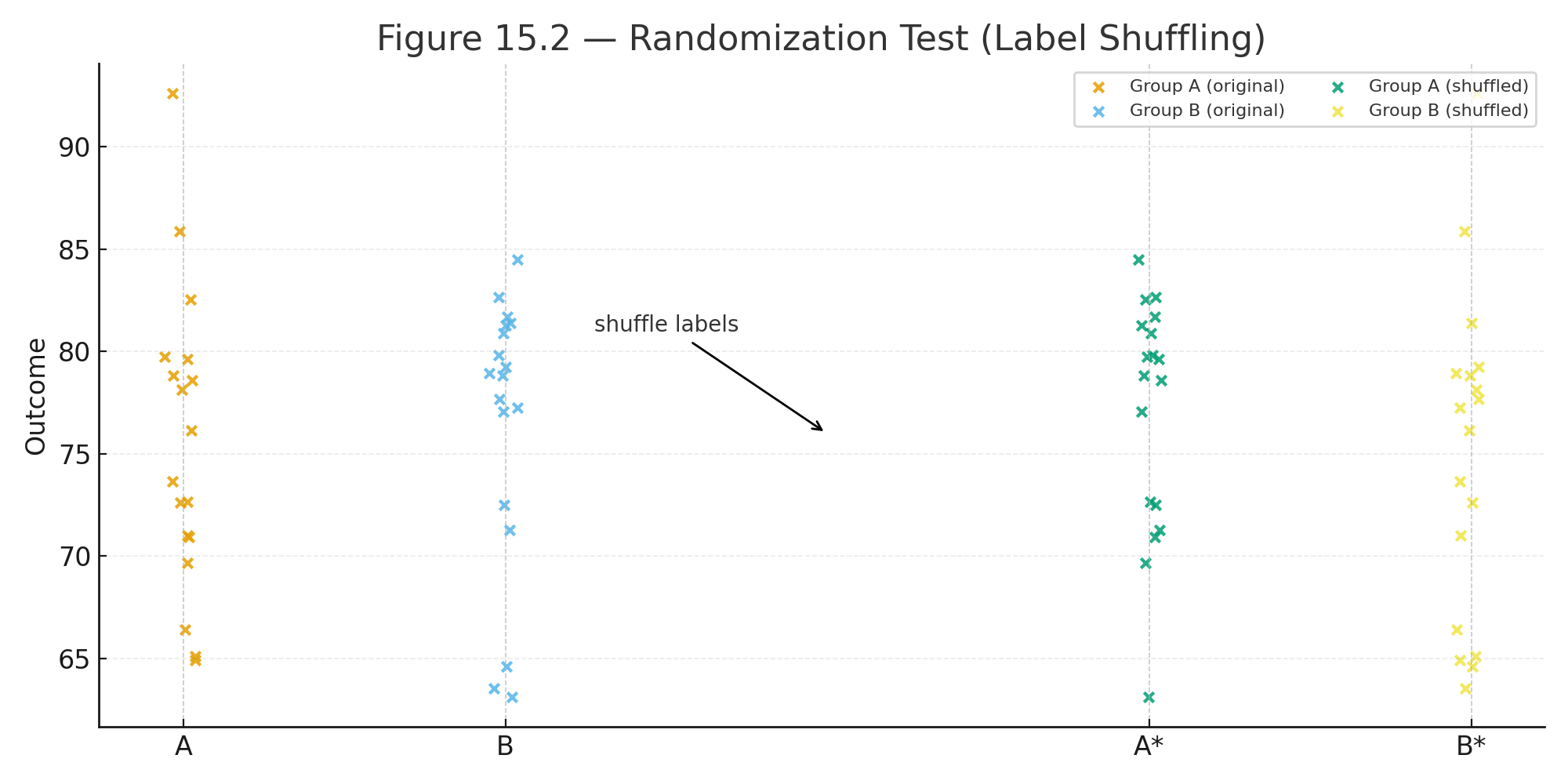
Most students do best by moving from the foundations (data, variability, probability) into core tests (t-tests and ANOVA), and then into modern topics (resampling, big data, and an introduction to machine learning).
2. How to Use This Textbook
- Start with the first lesson.
- Follow the Next / Previous links. Each lesson ends with navigation links so you can keep the correct order without guessing what comes next.
- Keep a small “definitions” page in your notes. Write down the meaning of key terms (mean, variance, standard deviation, probability, distribution) as you encounter them.
- For each test, practice three skills. (1) what the question is, (2) the computation, (3) the interpretation in words.
- Use the review pages when you get stuck.
3. Reading the Math
Formulas are displayed with MathJax so they stay clear on different screens. If a formula looks unfamiliar, read it slowly and connect each symbol to a meaning in words.
4. Why This Format Helps
- Clear sequence: lessons build from basic ideas to core tests.
- Readable math: formulas render cleanly across devices.
- Study-friendly: minimal distractions and no sign-in required.
- Open access: free to use for learning and review.
5. Summary
Use the textbook in order if you are learning statistics for the first time, and use it as a reference when you need a quick explanation or a worked example. If you study steadily and keep your own notes of definitions and interpretations, the material becomes much easier over time.