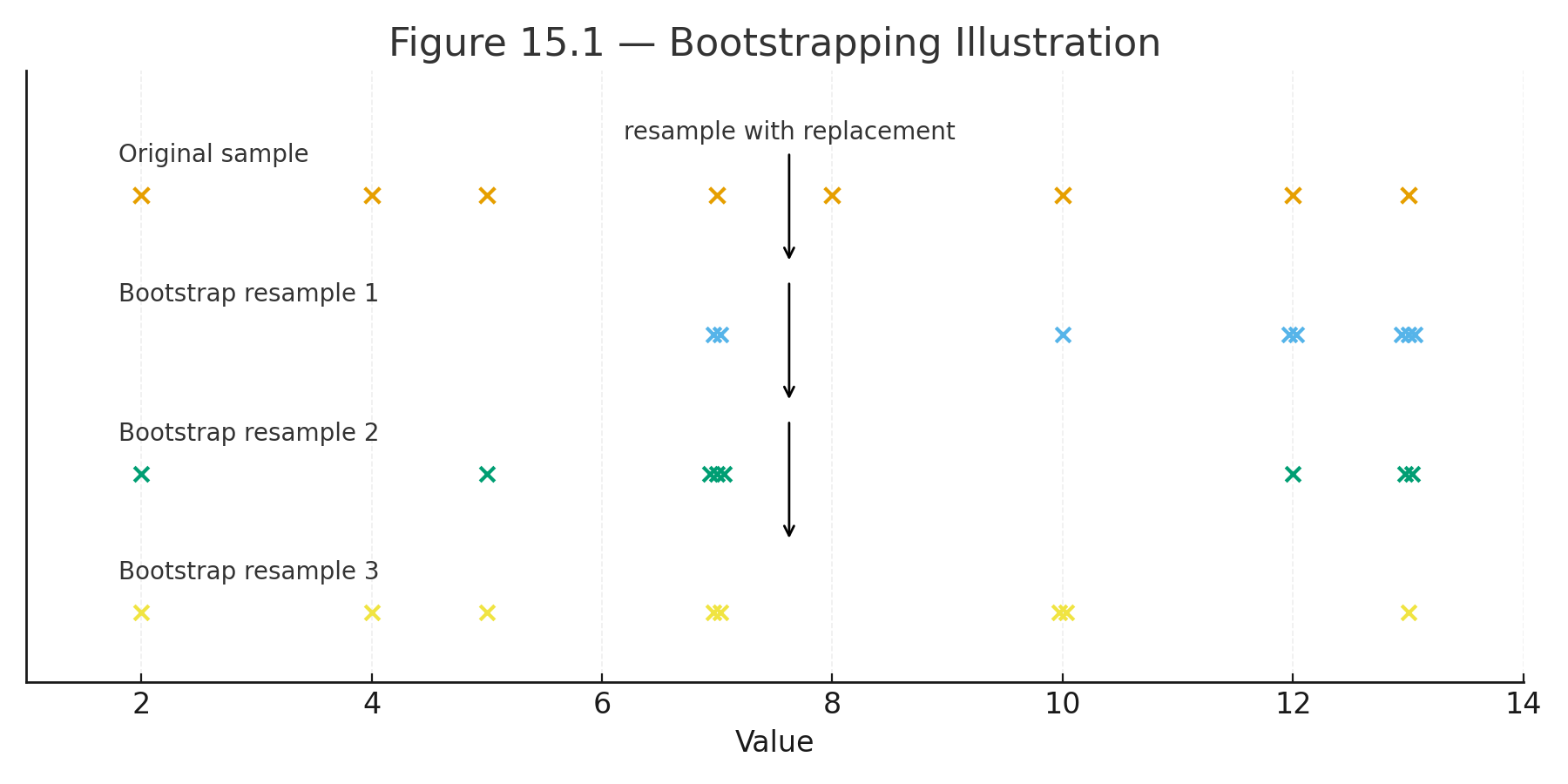
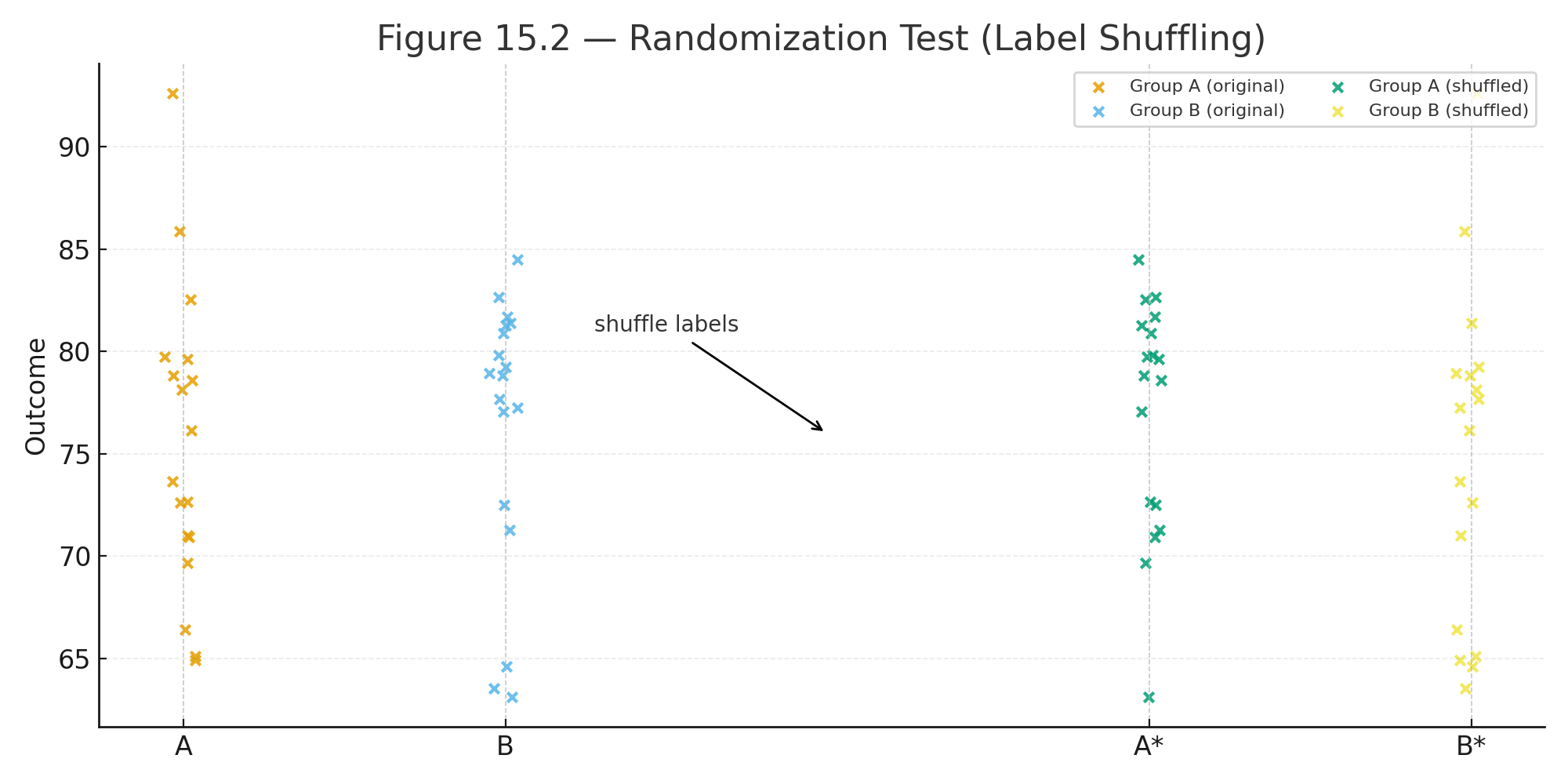
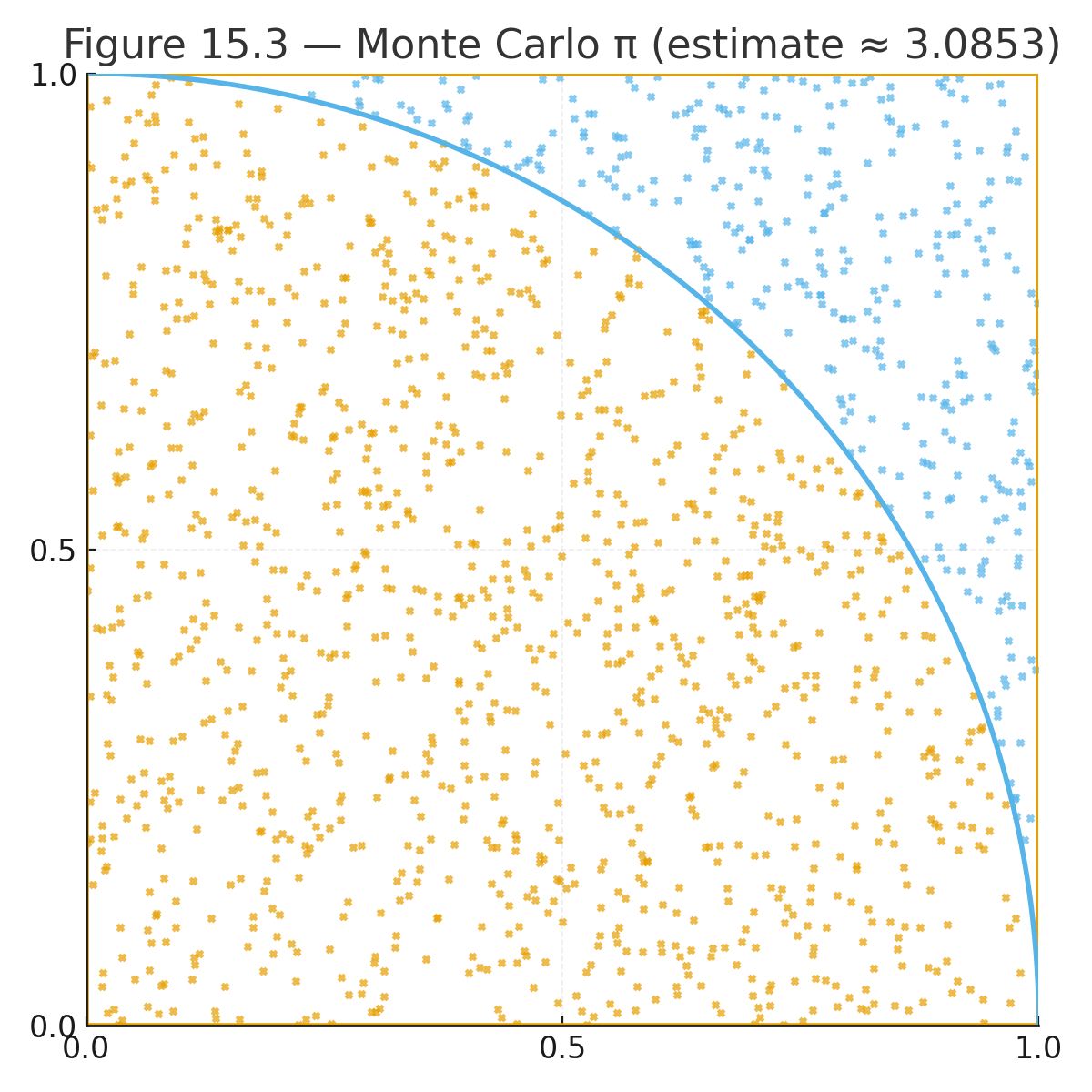
Lesson 18 — AI and Neural Networks (Intro)
Artificial Intelligence (AI) aims to build systems that can learn, adapt, and make decisions.
One powerful tool is the neural network, inspired by the brain.
From Statistics to AI
- Regression predicts Y from X
- Logistic regression predicts probability (0–1)
- Neural networks generalize this idea: many inputs, many layers, nonlinear patterns
The Structure of a Neural Network
- Input layer — variables (X₁, X₂, …)
- Hidden layers — units that transform the input
- Output layer — prediction or classification
Each connection has a weight (like a slope in regression).
Formula for a Neuron
A single unit in the network:
$$z = \sum w_i X_i + b$$
$$y = f(z)$$
Where:
- $$w_i$$ = weights
- $$X_i$$ = inputs
- $$b$$ = bias (like an intercept)
- $$f(z)$$ = activation function (e.g., logistic, ReLU)
Learning in a Network
The network predicts outputs and compares them with the true answers.
The error is sent backward through the network to adjust weights.
This is called backpropagation.
Example
Predicting if a student will pass or fail based on:
- Study hours
- Attendance
- Practice problems completed
Inputs → combined with weights → logistic activation → output: probability of passing.
Visuals
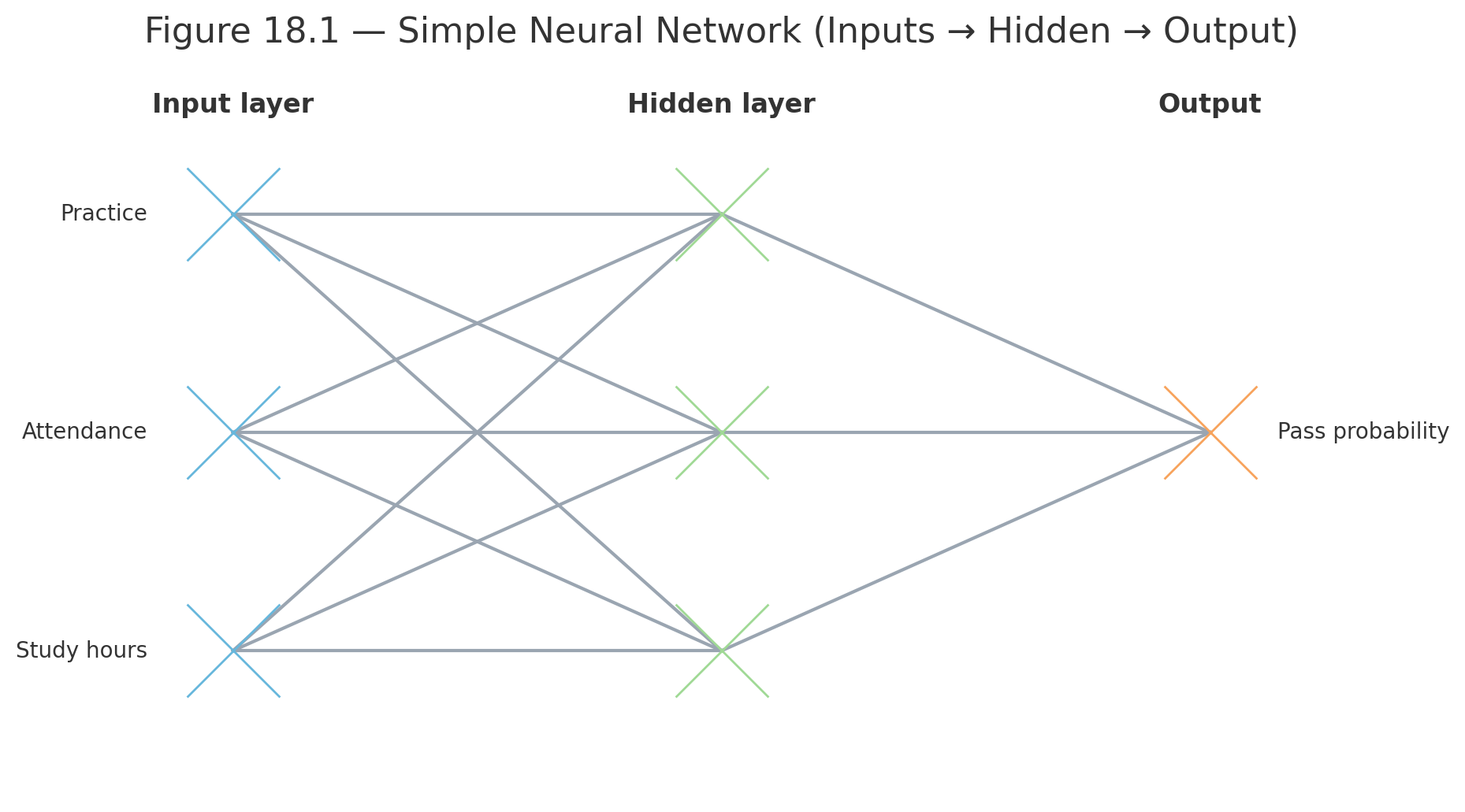
Figure 18.1 — Simple Neural Network (Inputs → Hidden → Output)
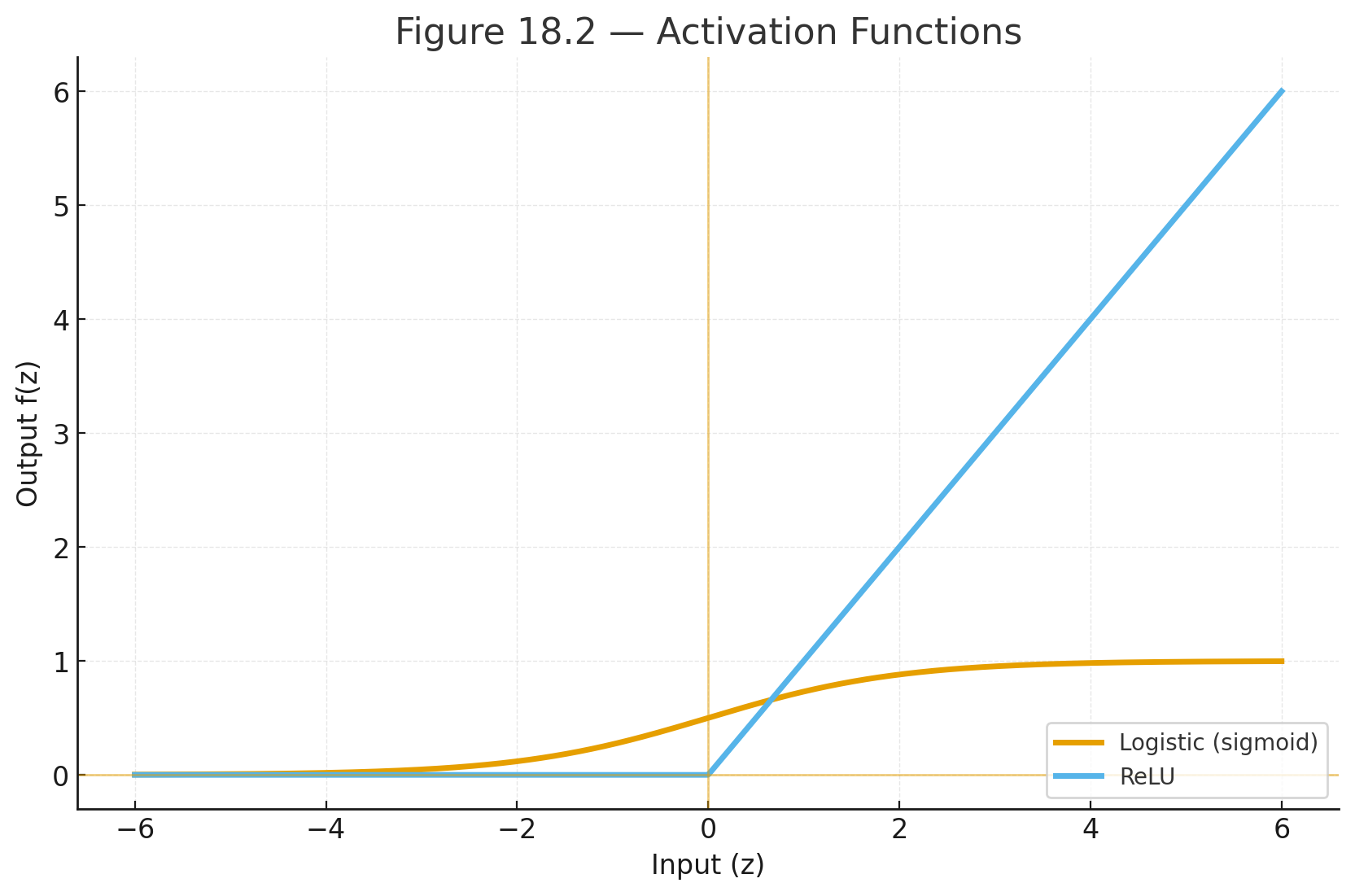
Figure 18.2 — Activation Functions
Why This Matters
- Neural networks extend regression and logistic regression.
- They allow learning from large, complex datasets (images, speech, language).
- Modern AI (translation, recognition, chatbots) is powered by these models.
Practice self-test quiz
In the space below, please find practice problems and self-test quizzes. For full access, please signup free.