Lesson 5 — Standard Error of the Mean (SEM)
When we take a sample from a population, the sample mean is not always equal to the population mean.
If we took many samples, the sample means would vary.
The Standard Error of the Mean (SEM) tells us how much.
It is the standard deviation of the sampling distribution of the mean.
Formula for the SEM
Symbolic formula:
$$\mathrm{SEM} = \frac{s}{\sqrt{n}}$$
Formula in words:
$$\text{SEM} = \frac{\text{standard deviation}}{\sqrt{\text{number of scores}}}$$
Where:
- $$s$$ = standard deviation of the sample
- $$n$$ = number of scores in the sample
Example
A class has test scores with:
- Mean = 80
- Standard deviation = 10
- Sample size = 25
Then:
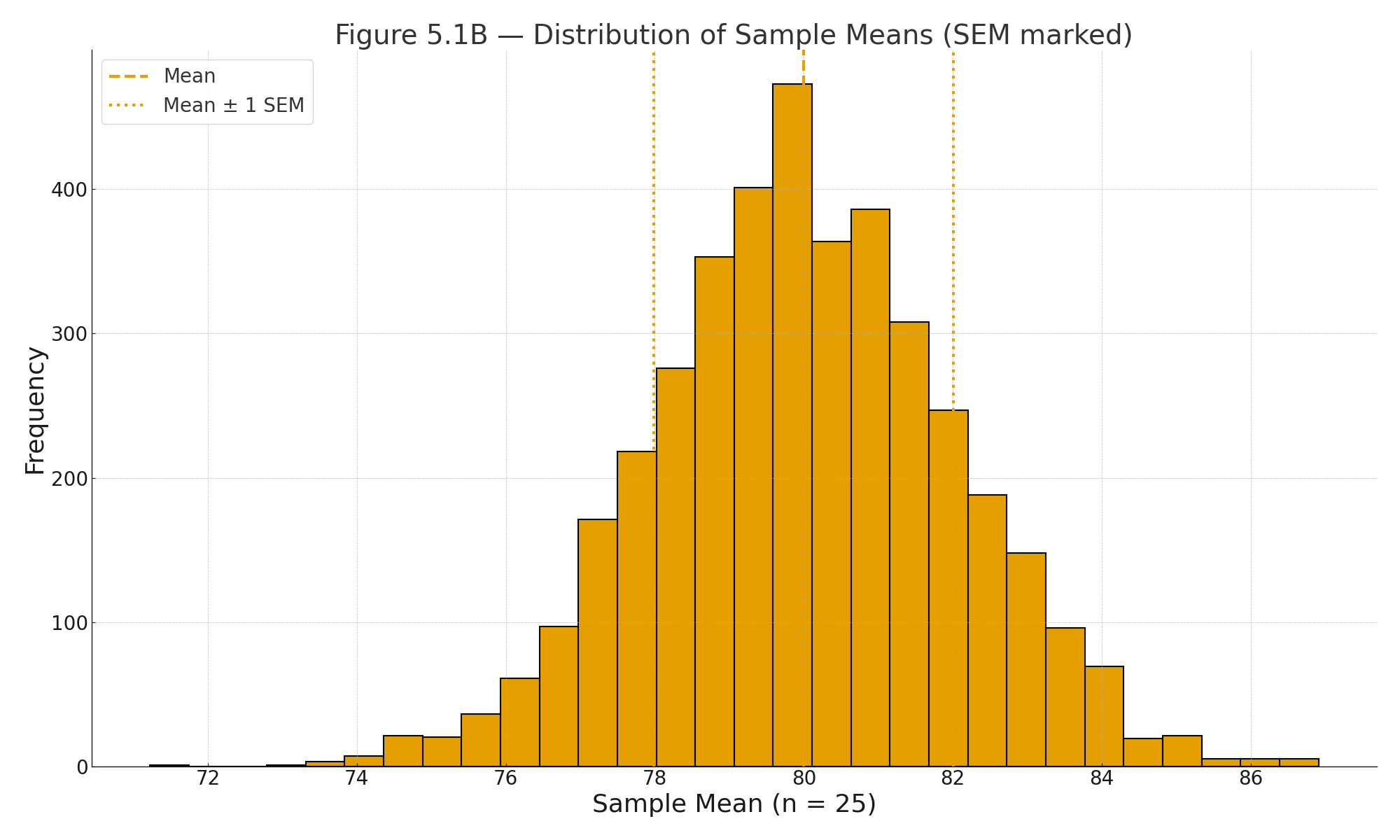
$$\mathrm{SEM} = \frac{10}{\sqrt{25}} = \frac{10}{5} = 2$$
The SEM is 2.
This means that the mean of repeated samples of 25 students would typically vary about 2 points from the population mean.
Definition
- Standard Error of the Mean (SEM): the expected variability of a sample mean compared to the true population mean.
Why This Matters
The SEM is crucial for inference.
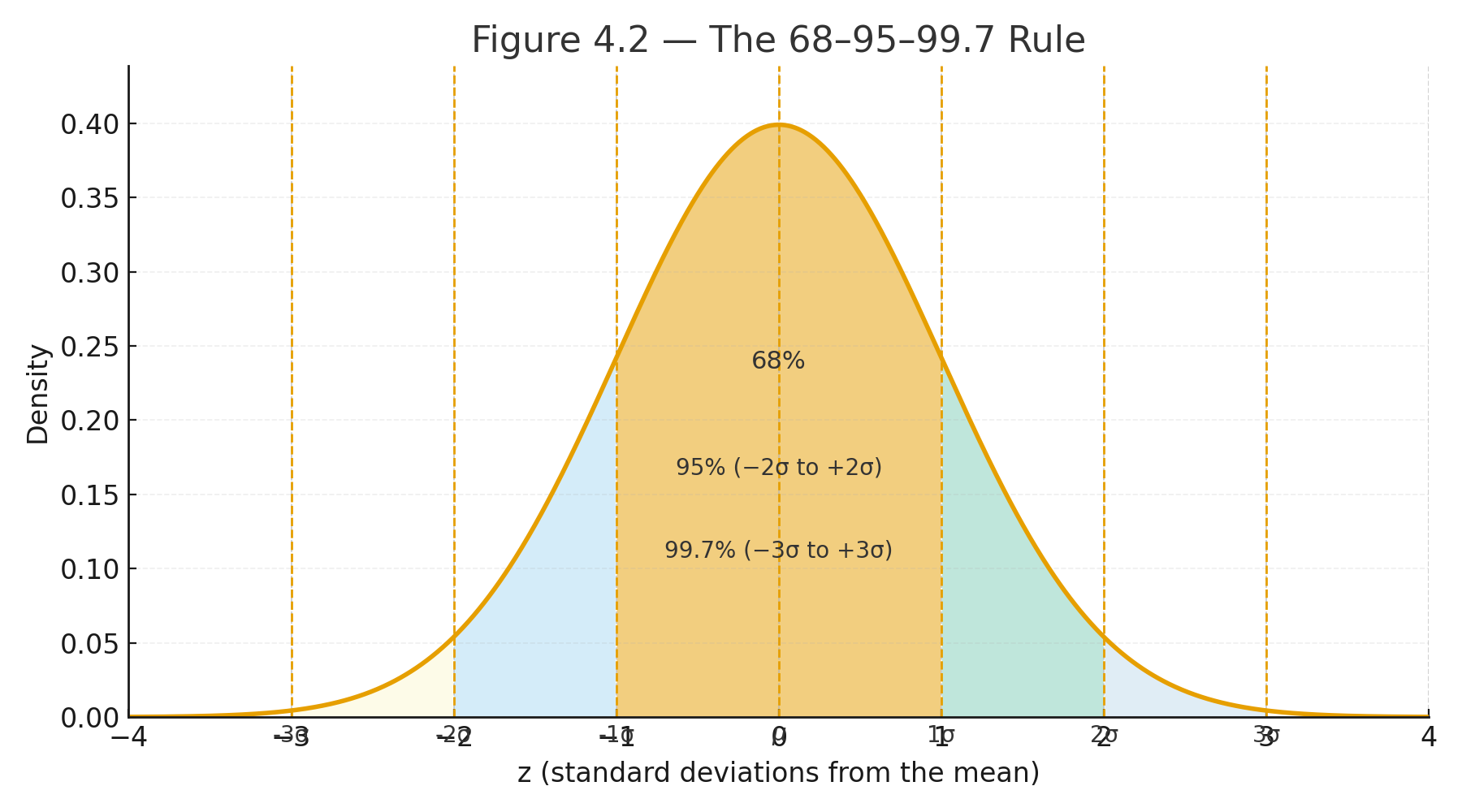
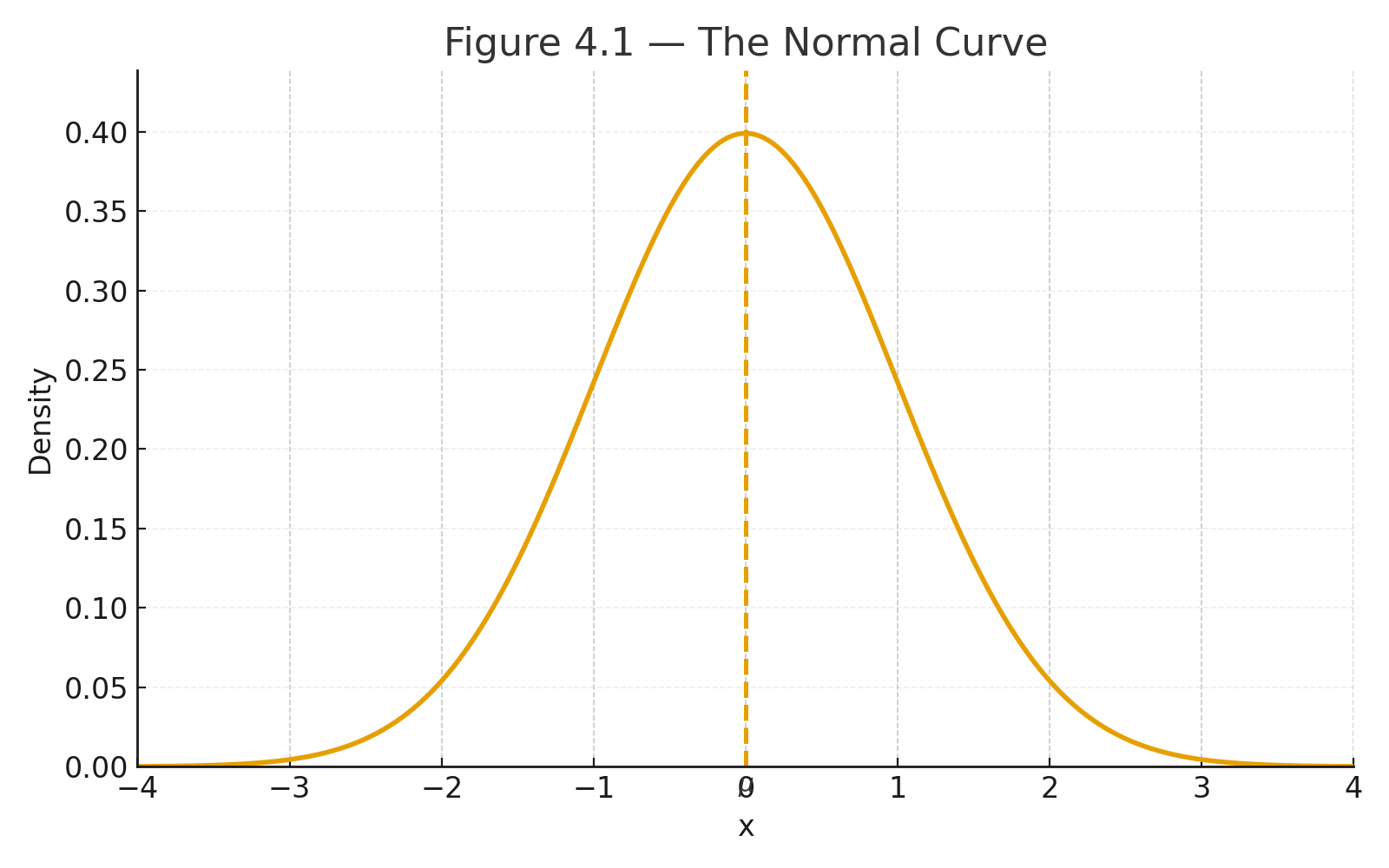
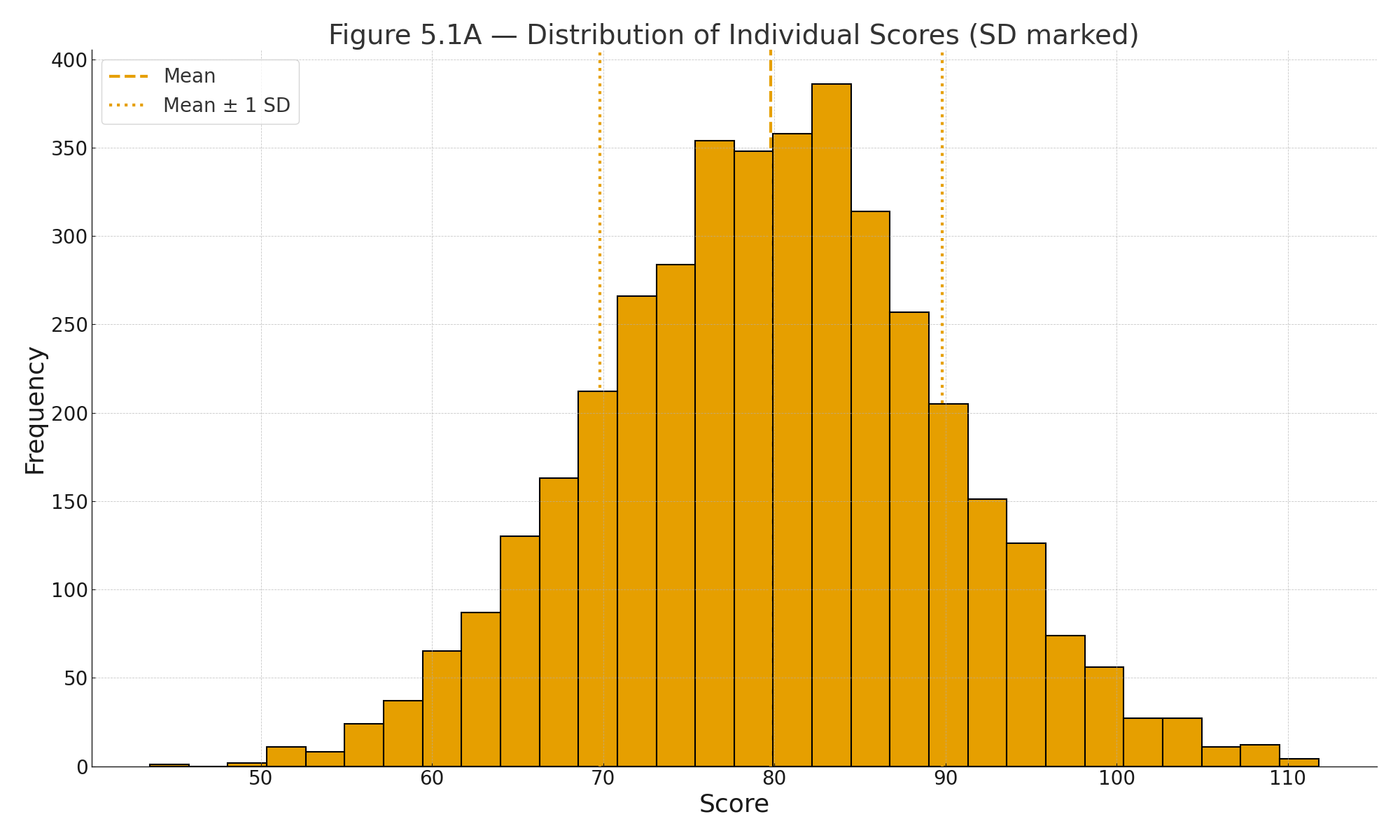
Visuals
Figure 5.1A — Distribution of individual scores with mean and ±1 SD marked.
Figure 5.1B — Distribution of sample means (n = 25) with mean and ±1 SEM marked; note the narrower spread.
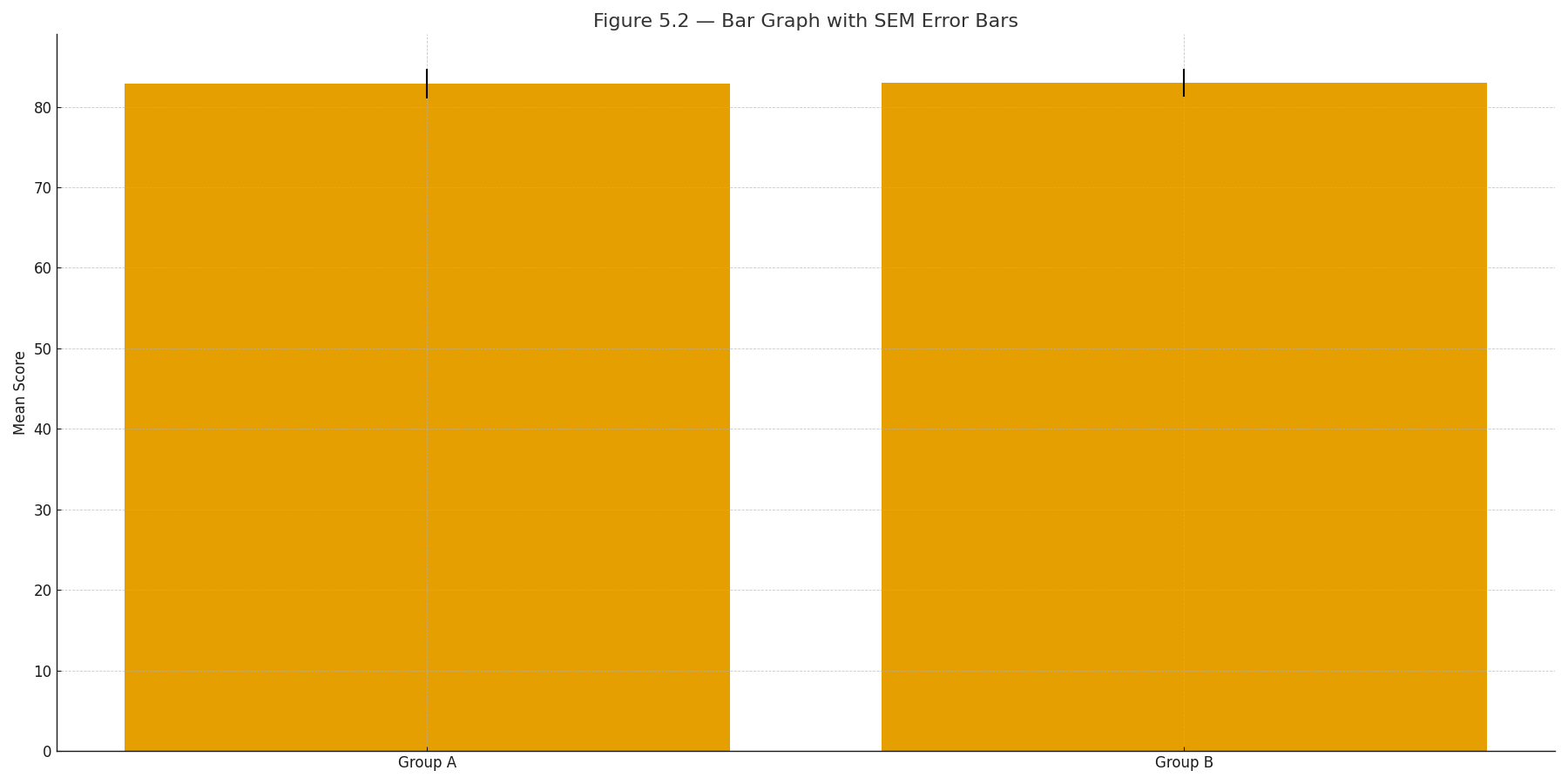
Figure 5.2 — Bar graph of two group means with error bars = SEM.
- It shows how reliable our sample mean is as an estimate of the population mean.
- A smaller SEM means a more precise estimate.
- The SEM appears in formulas for confidence intervals and t-tests.
Practice self-test quiz
In the space below, please find practice problems and self-test quizzes. For full access, please signup free.