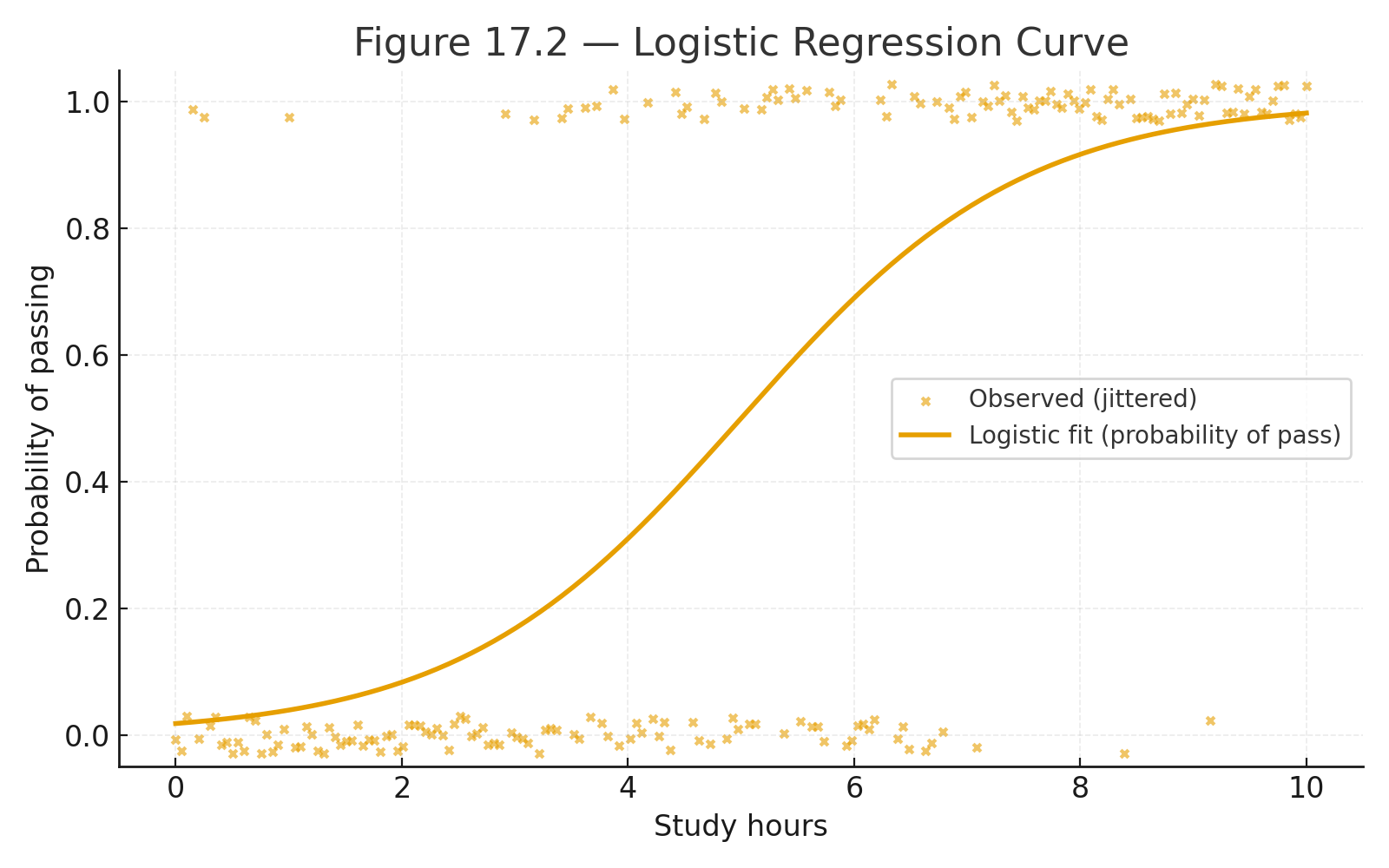
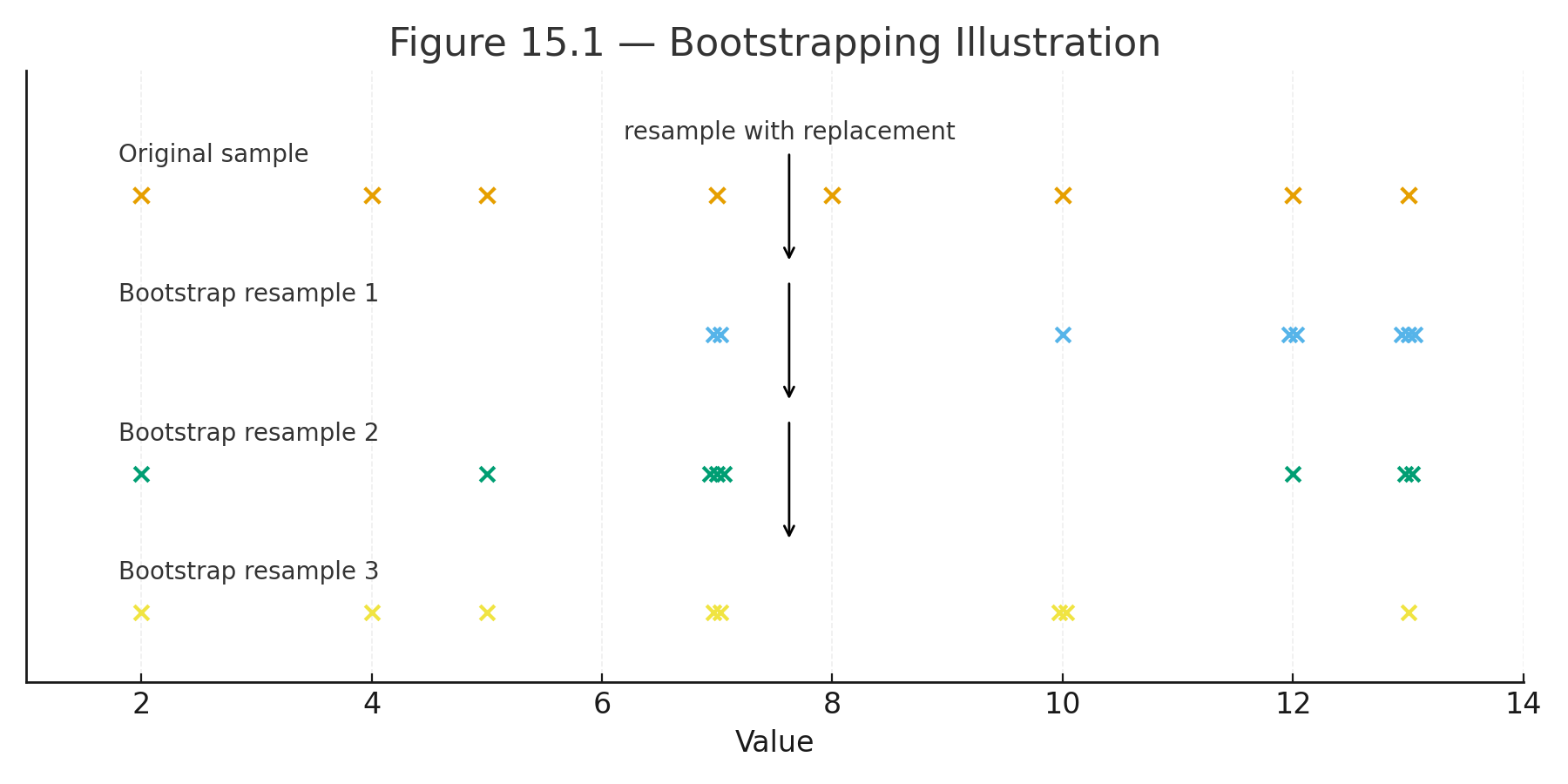
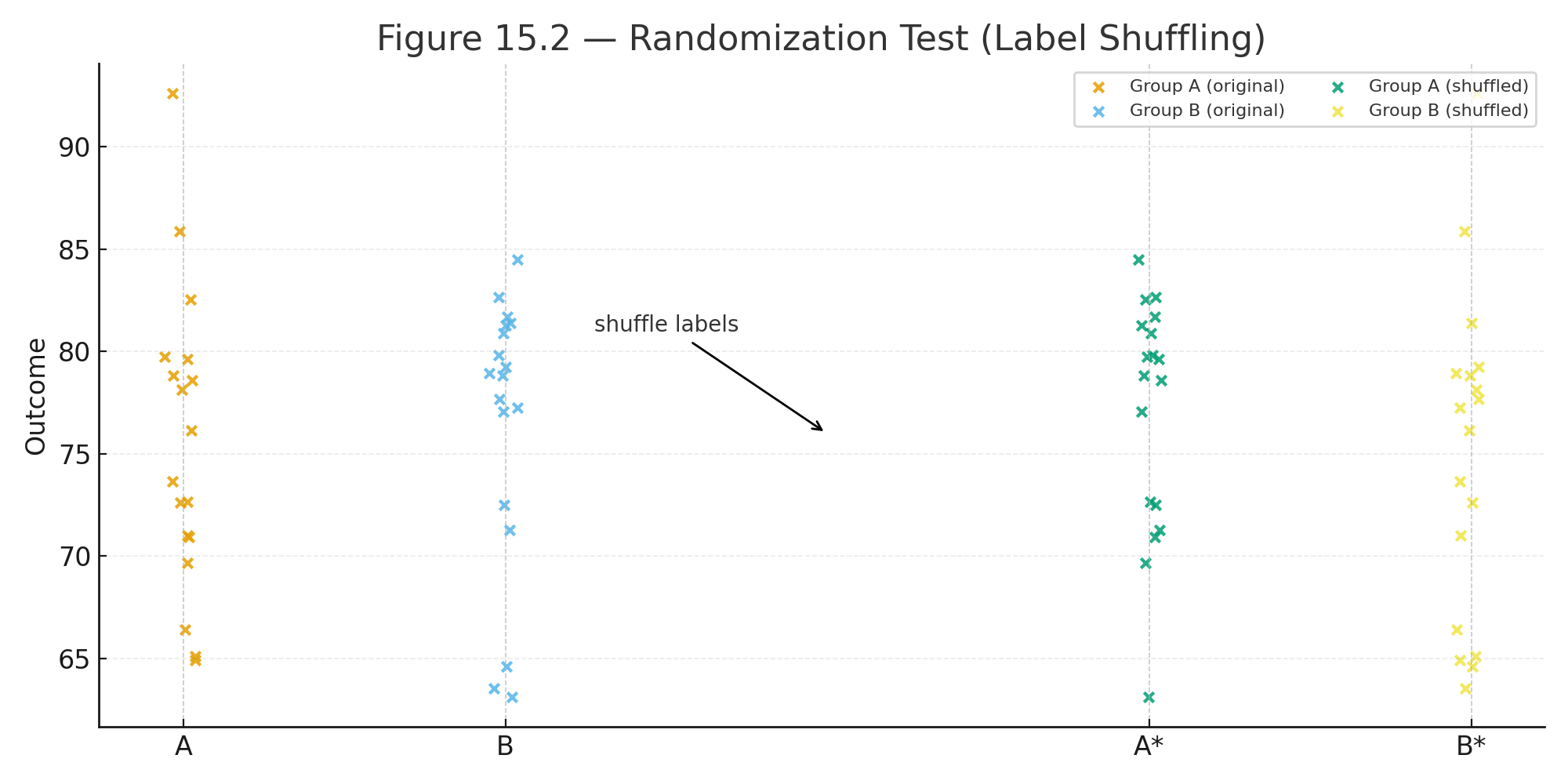
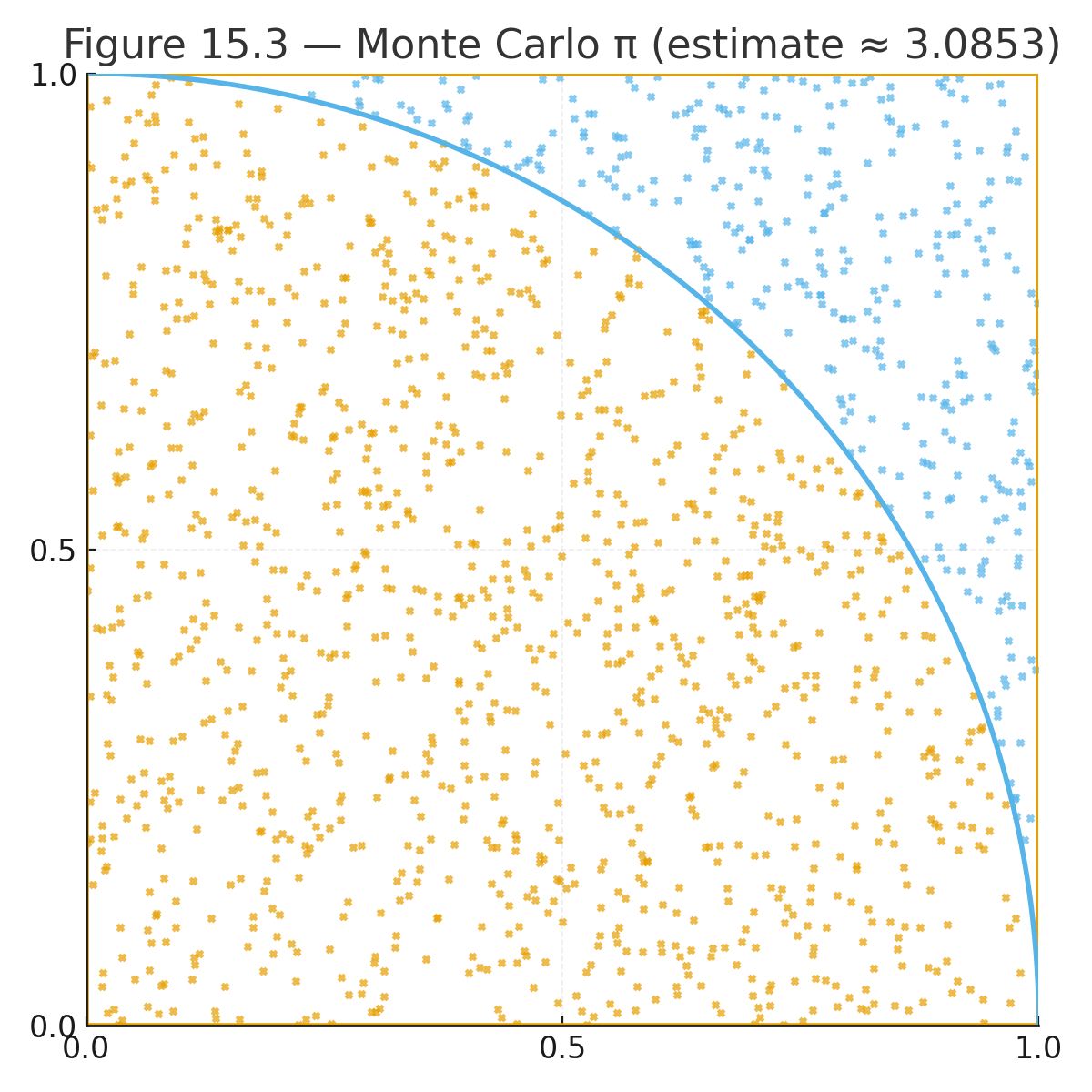
Appendix 6 — Data Sets for Practice

```html
Appendix 6 — Data Sets for Practice
Working with real numbers is the best way to learn statistics. This appendix provides small “mini datasets” you can analyze by hand (or with a calculator), plus larger files for practice with spreadsheets.
Dataset Provenance (Read This First)
- Pedagogical = small, simplified numbers chosen to make learning and checking easier.
- Simulated = computer-generated numbers designed to resemble real data (not collected from real people).
- Empirical = collected from real observations (only used if explicitly stated).
Note: Unless a dataset is explicitly labeled Empirical, you should treat it as Pedagogical or Simulated practice data.
Mini Datasets (In-Page)
1) Quiz Scores
Provenance: Pedagogical
n: 10
Scale: Ratio (points)
Data: 6, 7, 8, 9, 10, 7, 8, 6, 9, 10
- Suggested Lessons:
- Lesson 2 — The Averages: mean, median, mode
- Lesson 3 — Variance & Standard Deviation: variance, SD, z-scores
- Lesson 4 — The Standard Normal Curve: interpret z-scores (as a bridge)
- Check values (optional): Mean = 8.0; SD ≈ 1.41
2) Reaction Times (ms)
Provenance: Pedagogical (human-like values)
n: 8
Scale: Ratio (milliseconds)
Units: ms
Data: 220, 250, 270, 230, 260, 280, 240, 300
- Suggested Lessons:
- Lesson 3 — Variance & Standard Deviation: spread, outliers, SD
- Lesson 6 — The t-test: use as a template dataset (e.g., compare two conditions by splitting into two groups)
- Lesson 7 — ANOVA: extend to 3+ groups by creating conditions
- Instructor tip: reaction time data often show mild skew in real life. If you want skew, see the larger practice files below.
3) Stress Reduction Scores (Three Groups)
Provenance: Pedagogical (grouped scores)
Scale: Interval/Ratio (score units; treat as interval for ANOVA practice)
Groups:
- Meditation (n = 3): 65, 70, 72
- Exercise (n = 3): 68, 71, 75
- Music (n = 3): 75, 78, 82
- Suggested Lessons:
- Lesson 7 — ANOVA: one-way ANOVA (three independent groups)
- Lesson 8 — Post Hoc Tests: follow-up comparisons after ANOVA (conceptual)
- Lesson 13 — Degrees of Freedom Cookbook: df for one-way ANOVA
- Important note: The sample sizes are intentionally small for learning mechanics. In real studies, groups are usually larger.
Larger Practice Datasets (Download Files)
These datasets are designed for spreadsheet work, graphing, and full problem sets.
- Exam Scores (n = 100)
Provenance: Simulated
Suggested Lessons: Lesson 4 (normal curve), Lesson 5 (SEM), Lesson 6 (t-test foundations) - Survey Data (preferences by gender/age)
Provenance: Simulated (categorical practice)
Suggested Lessons: Lesson 12 (chi-square), Lesson 1 (why statistics matters in decisions) - Simulated Medical Trial (treatment vs. control, repeated measures)
Provenance: Simulated (instructional “trial-style” dataset; not clinical research)
Suggested Lessons: Lesson 6 (t-test concepts), Lesson 7 (variance partitioning concepts), and for advanced learners: repeated-measures ideas (optional)
Downloads: CSV and Excel files are provided via the QR code(s) on this page (and/or direct links, if enabled on your device).
Reproducibility note (simulated files): If you revise these datasets in future editions, consider generating them with a fixed random seed so instructors and students can reproduce results across versions.
Trusted External Sources (Optional)
If you want additional datasets beyond the practice files above, the following repositories are widely used for learning and benchmarking:
- NIST Statistical Reference Datasets (SRD)
High-quality benchmark datasets for practice and verification (excellent for checking calculations and software). - UCI Machine Learning Repository
Larger, more complex datasets. Recommended only for advanced students or enrichment projects.
Visual Reference
Figure F.1 — Example spreadsheet view of a dataset (columns such as ID, Score, Group). Use this as a template for organizing your own data before running calculations.
Self-Test Quiz Access
Practice problems and self-test quizzes may appear below. If full access is restricted, please sign up (free) to unlock the quiz section.
```