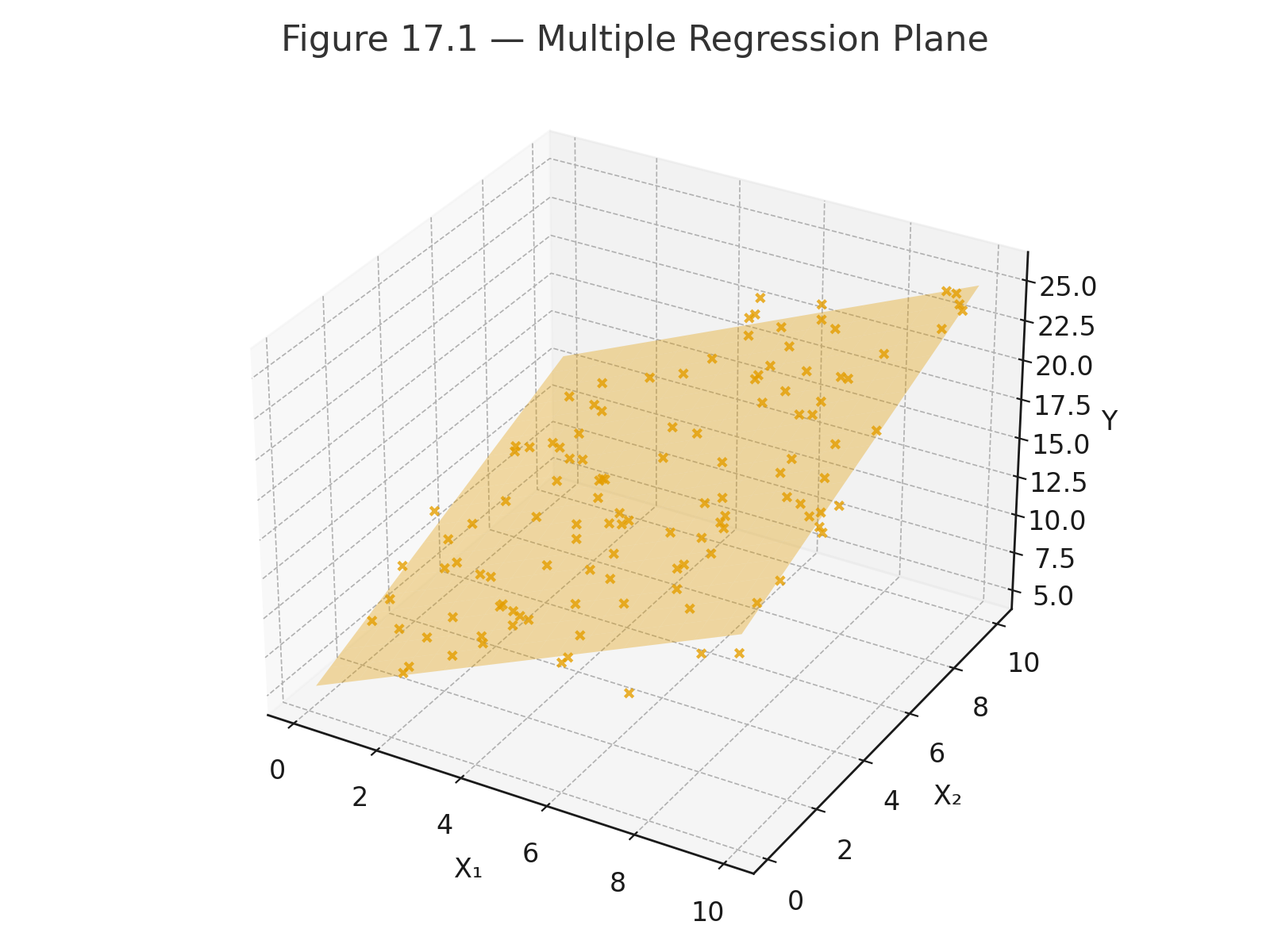
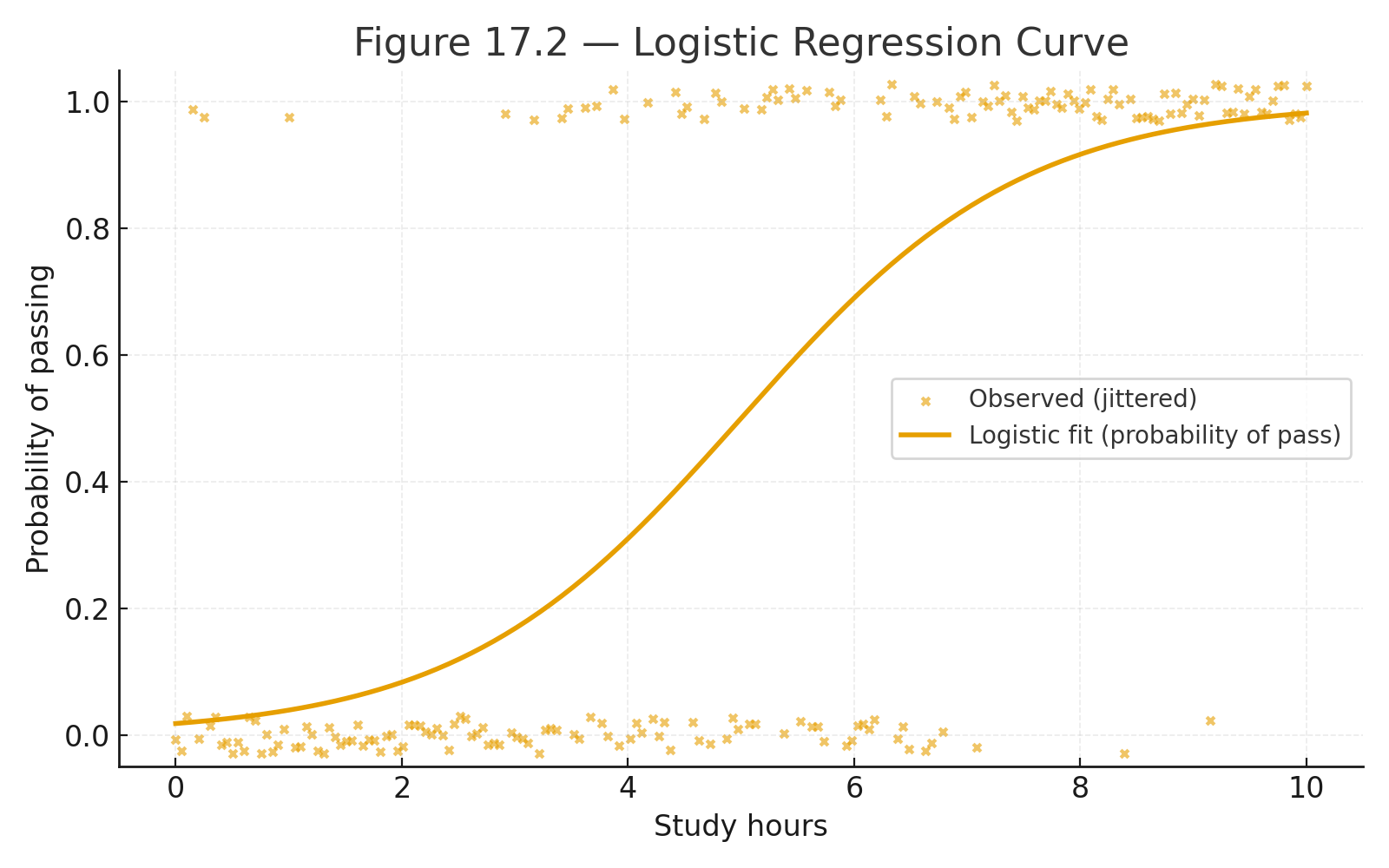
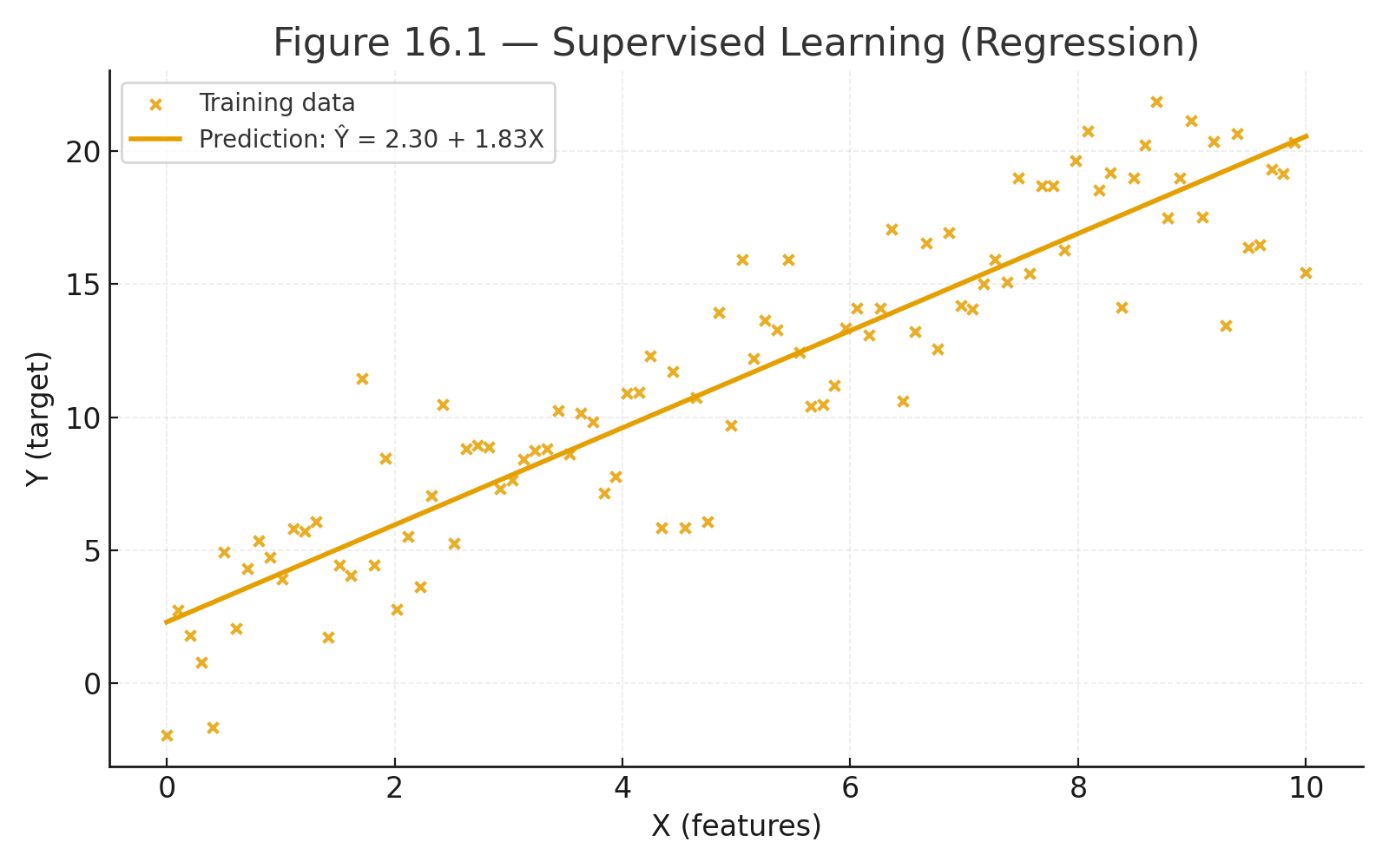
Appendix 4 — Using the z-table

The z-table gives areas (probabilities) under the standard normal curve (mean $$\mu=0$$, SD $$\sigma=1$$).
Use it after you standardize a score:
Standardization (z-score):
$$z=\frac{x-\mu}{\sigma}$$
In words: $$z=\frac{\text{score} - \text{mean}}{\text{standard deviation}}$$
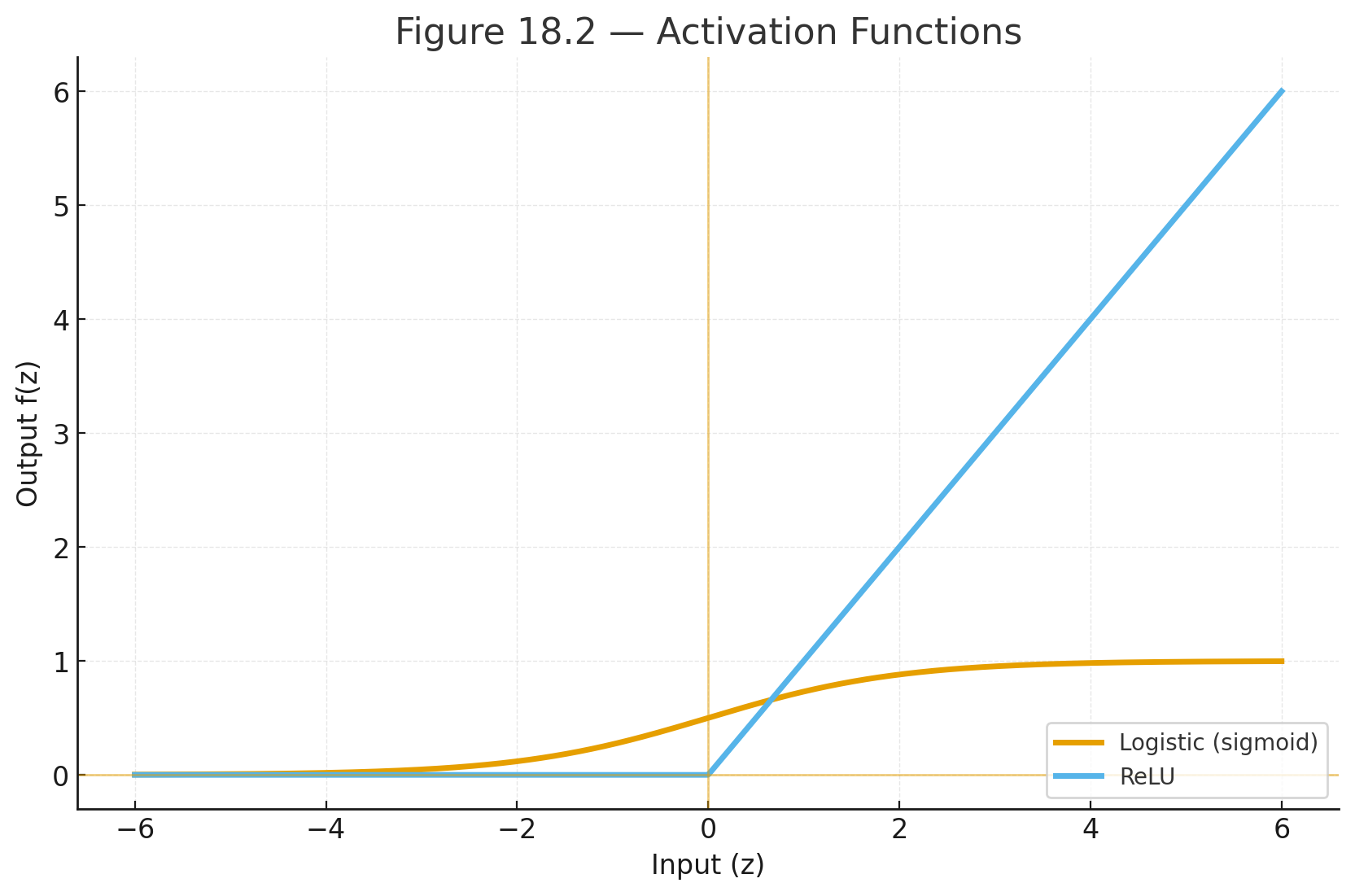
What the z-table shows
Most tables list the area to the left of a z value (cumulative probability).
- Left area at $$z=0$$ is 0.5000 (half the curve).
- Far left (negative big z) approaches 0; far right (positive big z) approaches 1.
Quick recipes
1) Probability below a score (left tail)
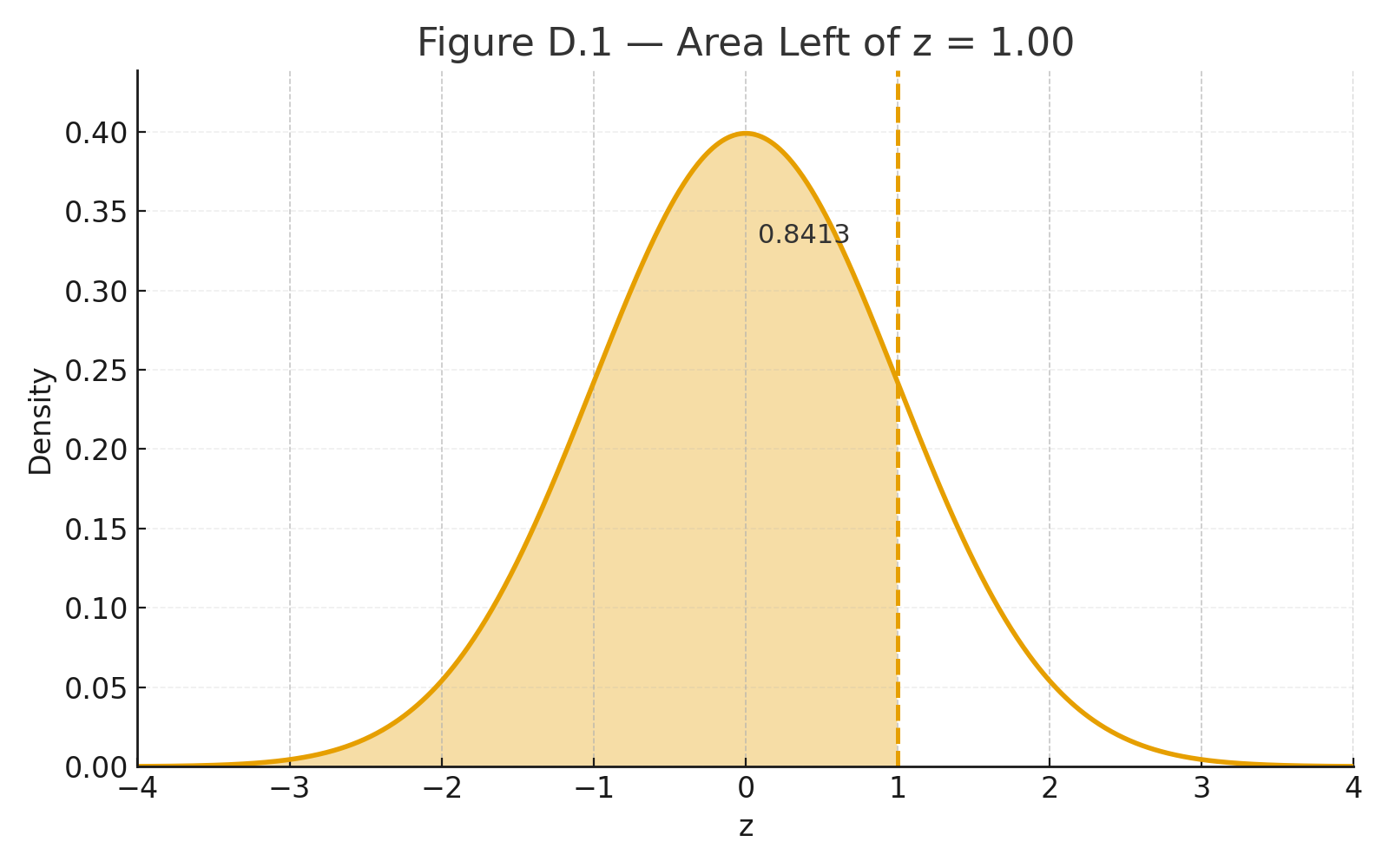
Example: $$z=1.00$$ → table gives 0.8413.
Interpretation: $$P(Z \le 1.00)=0.8413$$ (84.13% below).
2) Probability above a score (right tail)
Use complement: $$P(Z \ge z)=1-\text{left area}$$.
Example: $$z=1.00 \Rightarrow P(Z \ge 1.00)=1-0.8413=0.1587.$$
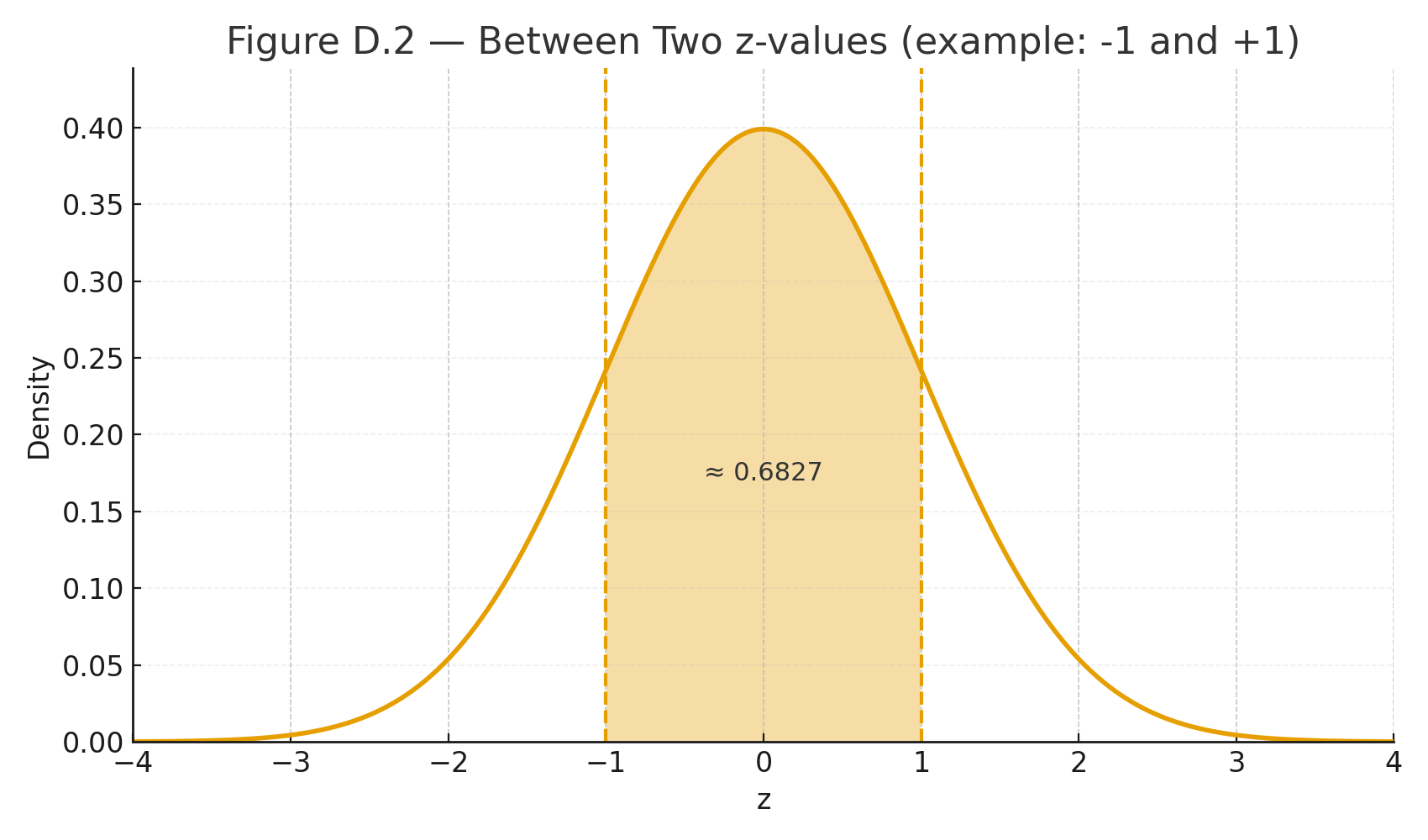
3) Probability between two scores
Subtract left areas.
Example: between $$z= -0.50$$ (left area 0.3085) and $$z=1.20$$ (0.8849):
$$P(-0.50 \le Z \le 1.20)=0.8849-0.3085=0.5764.$$
4) From a raw score to probability
Test scores: $$\mu=100, \ \sigma=15$$. What % are below 115?
Standardize: $$z=\frac{115-100}{15}=1.00 \Rightarrow 0.8413 \ (\text{84.13%}).$$
5) From probability to raw score (percentile)
What score is the 90th percentile?
Find z with left area ≈ 0.9000 → $$z \approx 1.2816$$.
Convert back: $$x=\mu+z\sigma=100+(1.2816)(15)=119.22.$$
Tips
- For negative z, use the table’s symmetry: left area at $$-z$$ equals 1 − left area at $$+z$$.
- Rounding: two decimals is common (e.g., 1.23).
- Modern tools (calculator/Sheets/Python) can give exact p-values directly.
Visuals
Figure D.1 — Normal curve with area left of z = 1.00 shaded (0.8413).
Figure D.2 — Two-z shaded band for “between” probability.
📱 QR: Online z-calculator (type z or x, get areas instantly)
Practice self-test quiz
In the space below, please find practice problems and self-test quizzes. For full access, please signup free.