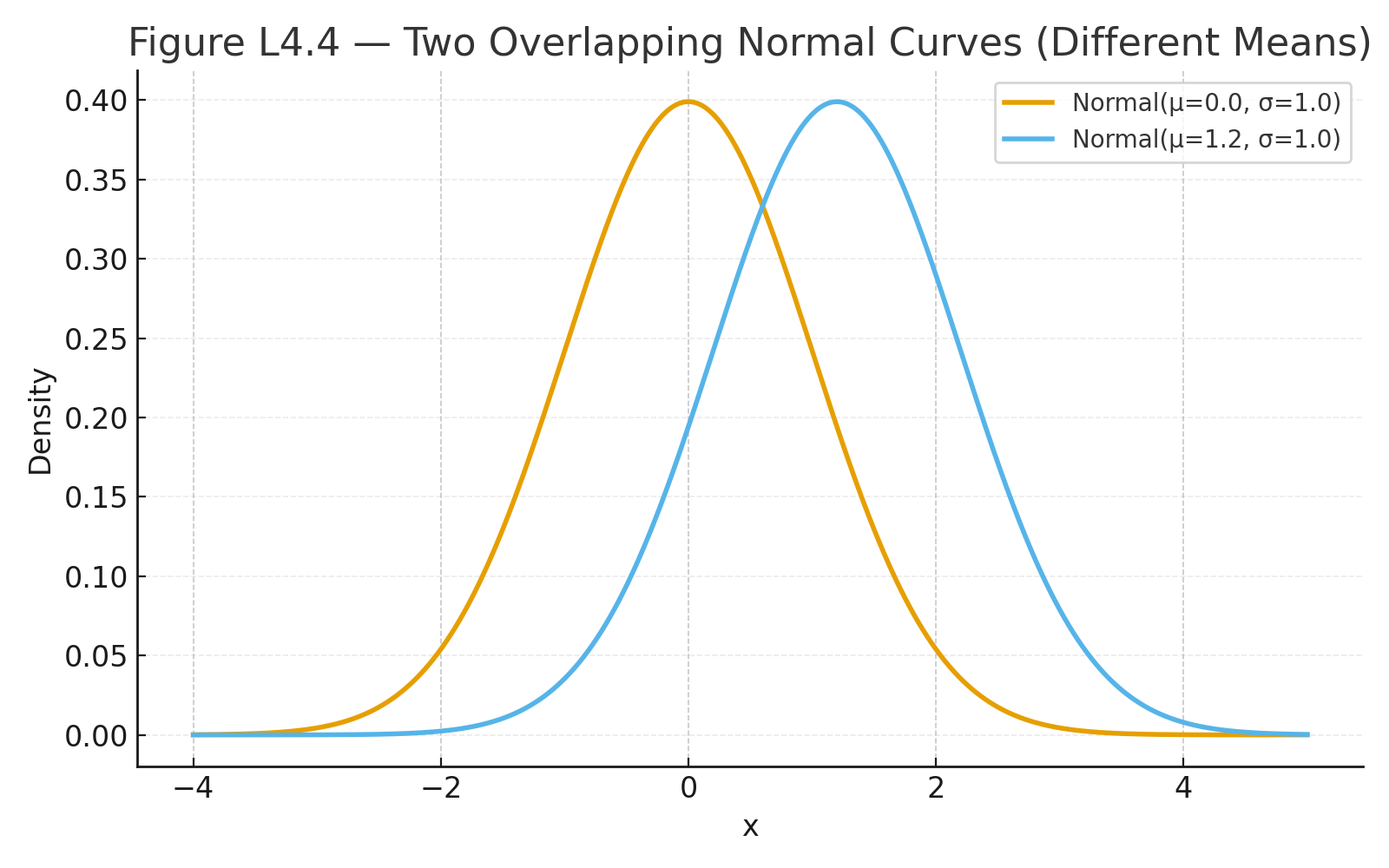
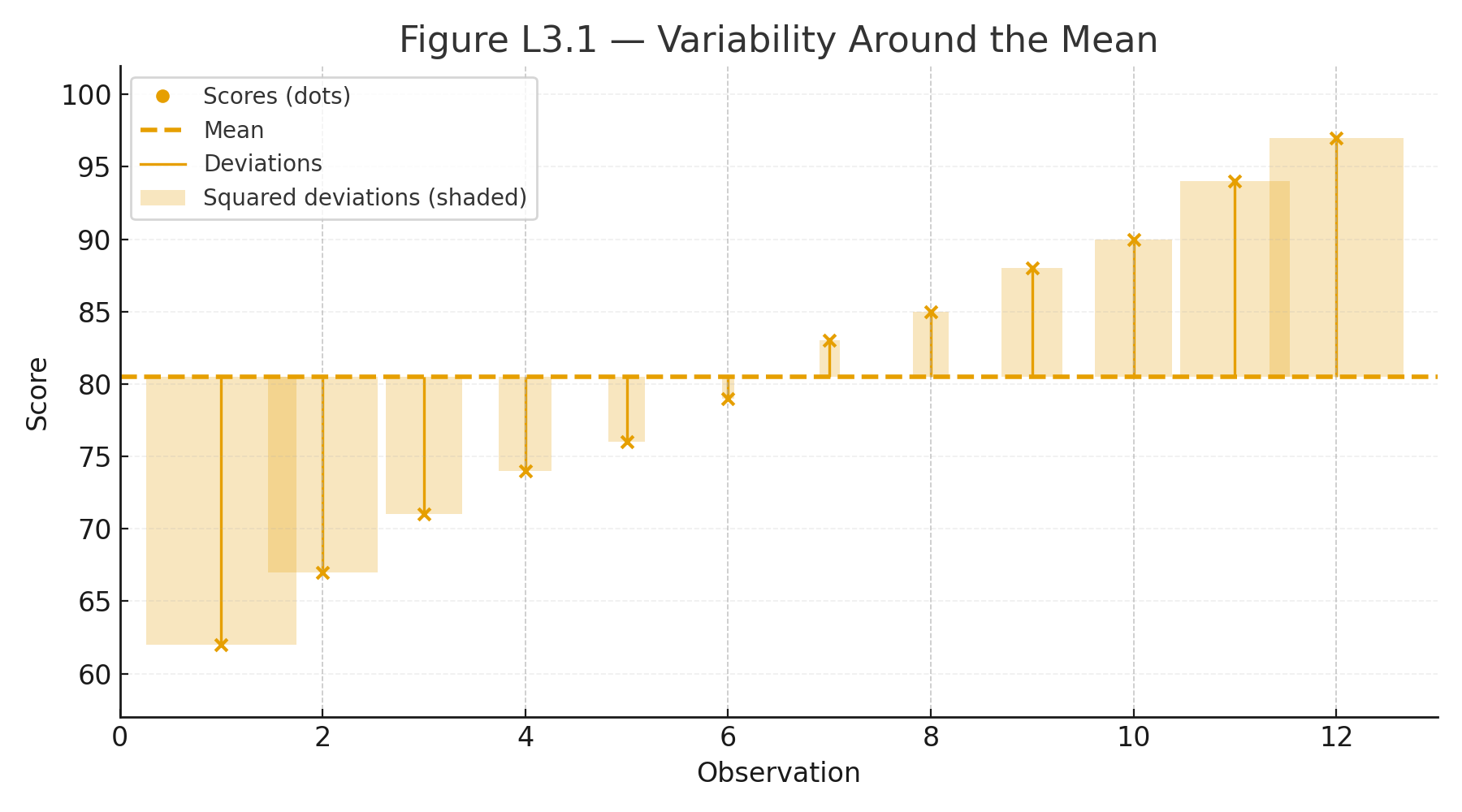
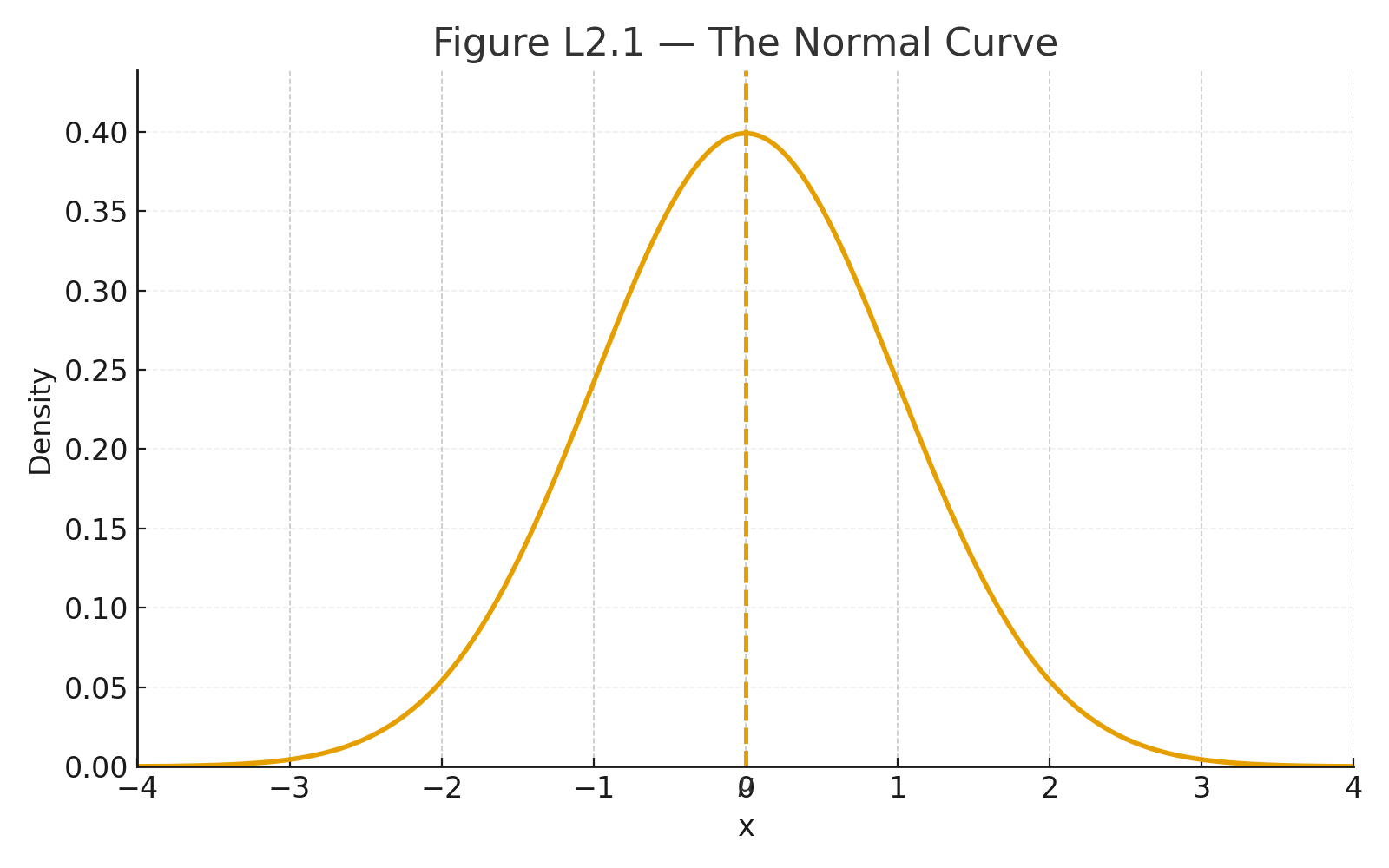
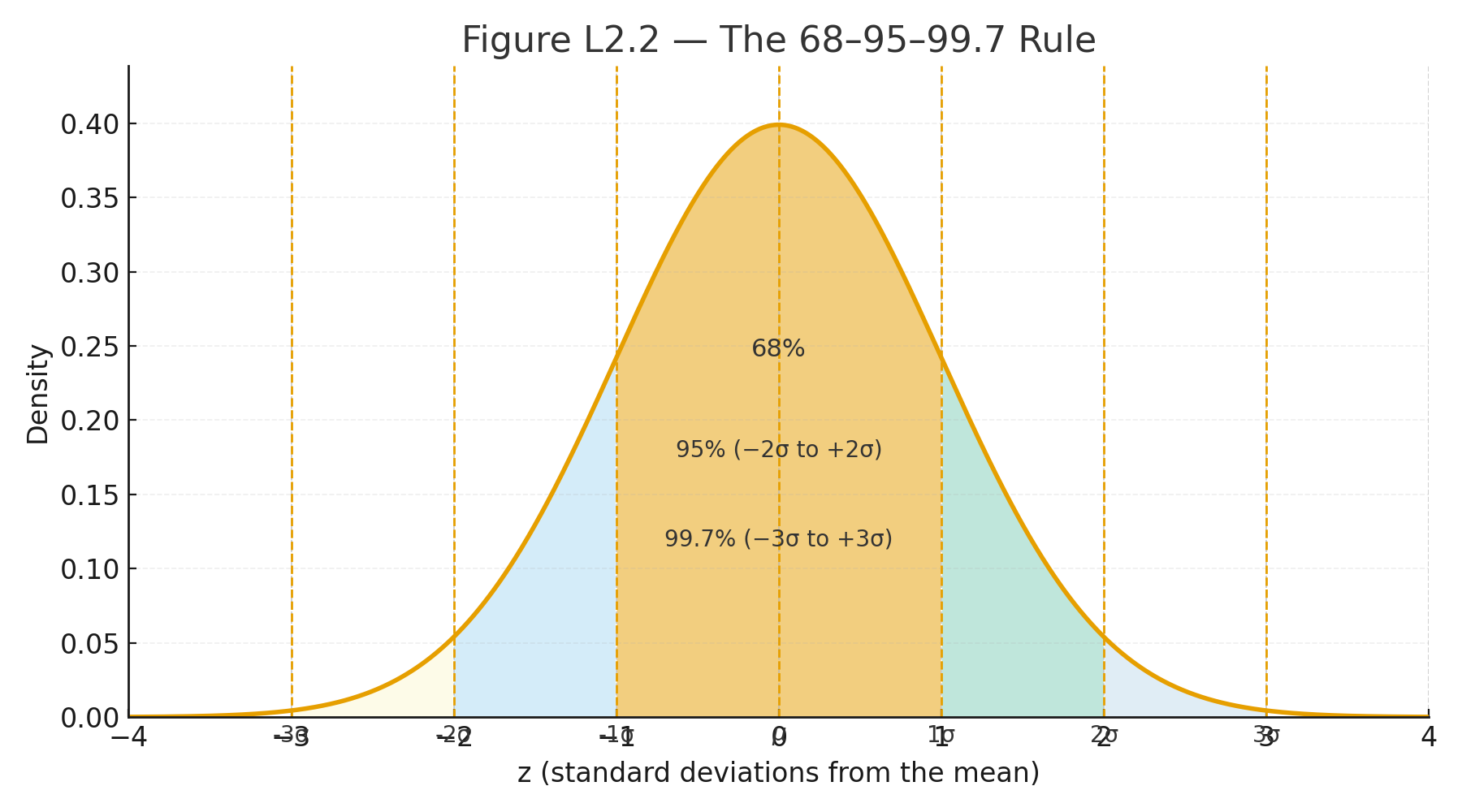
Identify the Design
Case 1
Scenario: A teacher compares test scores of students in two different classrooms (Class A vs. Class B).
Question: Are the two groups significantly different in mean score?
Answer: Independent-samples t-test.
Case 2
Scenario: A researcher tests the same group of students before and after tutoring.
Question: Did their scores improve after the program?
Answer: Paired-samples t-test (dependent t-test).
Case 3
Scenario: Three groups of students use different study methods: flashcards, highlighting, and practice tests.
Question: Do the study methods lead to different mean scores?
Answer: One-way ANOVA.
Case 4
Scenario: A psychologist measures anxiety scores in patients given three different drugs.
Question: Do the drugs produce different mean anxiety scores?
Answer: One-way ANOVA.
Case 5
Scenario: A study compares two groups of athletes: runners vs. swimmers, on reaction time.
Question: Are the two sports groups different in mean reaction time?
Answer: Independent-samples t-test.
Case 6
Scenario: Students are tested at three times: beginning, middle, and end of the semester.
Question: Did their scores change over time?
Answer: Repeated-measures ANOVA.
Case 7
Scenario: Two teaching methods (Lecture, Online) are tested across two times of day (Morning, Afternoon).
Question: What are the effects of method, time, and their interaction?
Answer: Two-way (factorial) ANOVA.
Case 8
Scenario: A company compares productivity of three work shifts (Day, Evening, Night) across two departments (Sales, Service).
Question: Are there main effects of shift and department, and is there an interaction?
Answer: Two-way (factorial) ANOVA.
Case 9
Scenario: Students are randomly assigned to a control or experimental group, and both groups are measured three times (Weeks 1, 2, 3).
Question: Is there an effect of group, time, and interaction?
Answer: Mixed (split-plot) ANOVA.
Case 10
Scenario: A survey asks students to choose their favorite subject: Math, Science, or English.
Question: Is the distribution of responses different from chance?
Answer: Chi-square goodness-of-fit test.
Case 11
Scenario: A researcher studies whether gender (Male, Female) is related to preference for sports (Soccer, Basketball, Tennis).
Question: Is there an association between gender and sport preference?
Answer: Chi-square test of independence.
Case 12
Scenario: Students are ranked by teacher ratings: 1st, 2nd, 3rd, etc. Two different teaching methods are compared on these ranks.
Question: Do the groups differ in median ranks?
Answer: Mann–Whitney U test (non-parametric).
Case 13
Scenario: The same students are ranked before and after a training program.
Question: Did the ranks change after training?
Answer: Wilcoxon signed-rank test (non-parametric).
Practice self-test quiz
In the space below, please find practice problems and self-test quizzes. For full access, please signup free.