Appendix 10 — The t-table
Appendix 10: The t-Table (Critical Values for Student's t Distribution)
This appendix provides critical t-values for hypothesis testing (e.g., one-sample or independent t-tests) at common significance levels. Use it to determine if your calculated t-statistic indicates a significant difference (reject null hypothesis when |t| > critical value).
How to Use the t-Table
- Left column: Degrees of freedom (df) — usually n-1 for one-sample or n₁ + n₂ - 2 for two independent samples.
- Top row: Significance level (p, one-tailed or two-tailed depending on test).
- Find the intersection value = critical t.
- If your |calculated t| > critical t → reject null hypothesis (significant at that p level).
- For two-tailed tests, use p/2 values (e.g., for α=0.05 two-tailed, use 0.025 column).
Example 1 (from page content)
Two independent groups, 10 subjects each → df = 18.
Calculated t = 4.51.
Look up df = 18, p = 0.05 → critical t = 1.734.
4.51 > 1.734 → significant difference (p < 0.05). Reject null hypothesis: means differ.
Example 2
One-sample t-test, n = 25 → df = 24.
Calculated t = 2.15.
Look up df = 24, p = 0.05 → critical t = 1.711 (one-tailed) or use 0.025 column = 2.064 (two-tailed).
If one-tailed: 2.15 > 1.711 → significant. If two-tailed: 2.15 > 2.064 → significant.
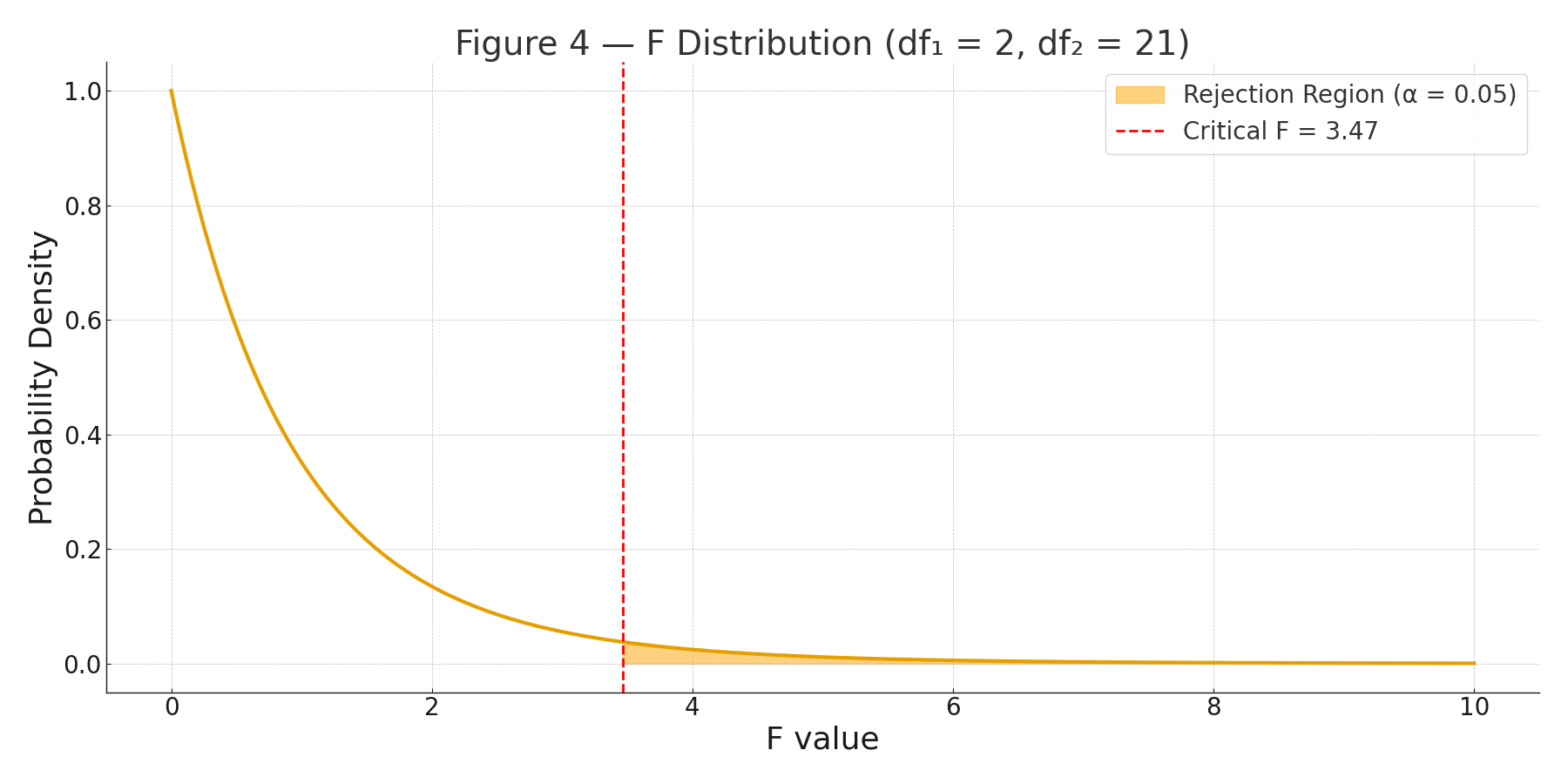
t Critical Values Table
| df | 0.10 | 0.05 | 0.025 | 0.01 | 0.005 | 0.001 |
|---|---|---|---|---|---|---|
| 1 | 3.078 | 6.314 | 12.706 | 31.821 | 63.657 | 318.31 |
| 2 | 1.886 | 2.920 | 4.303 | 6.965 | 9.925 | 22.326 |
| 3 | 1.638 | 2.353 | 3.182 | 4.541 | 5.841 | 10.215 |
| 4 | 1.533 | 2.132 | 2.776 | 3.747 | 4.604 | 7.173 |
| 5 | 1.476 | 2.015 | 2.571 | 3.365 | 4.032 | 5.893 |
| 6 | 1.440 | 1.943 | 2.447 | 3.143 | 3.707 | 5.208 |
| 7 | 1.415 | 1.895 | 2.365 | 2.998 | 3.499 | 4.782 |
| 8 | 1.397 | 1.860 | 2.306 | 2.896 | 3.355 | 4.499 |
| 9 | 1.383 | 1.833 | 2.262 | 2.821 | 3.250 | 4.296 |
| 10 | 1.372 | 1.812 | 2.228 | 2.764 | 3.169 | 4.143 |
| 11 | 1.363 | 1.796 | 2.201 | 2.718 | 3.106 | 4.024 |
| 12 | 1.356 | 1.782 | 2.179 | 2.681 | 3.055 | 3.929 |
| 13 | 1.350 | 1.771 | 2.160 | 2.650 | 3.012 | 3.852 |
| 14 | 1.345 | 1.761 | 2.145 | 2.624 | 2.977 | 3.787 |
| 15 | 1.341 | 1.753 | 2.131 | 2.602 | 2.947 | 3.733 |
| 16 | 1.337 | 1.746 | 2.120 | 2.583 | 2.921 | 3.686 |
| 17 | 1.333 | 1.740 | 2.110 | 2.567 | 2.898 | 3.646 |
| 18 | 1.330 | 1.734 | 2.101 | 2.552 | 2.878 | 3.610 |
| 19 | 1.328 | 1.729 | 2.093 | 2.539 | 2.861 | 3.579 |
| 20 | 1.325 | 1.725 | 2.086 | 2.528 | 2.845 | 3.552 |
| 21 | 1.323 | 1.721 | 2.080 | 2.518 | 2.831 | 3.527 |
| 22 | 1.321 | 1.717 | 2.074 | 2.508 | 2.819 | 3.505 |
| 23 | 1.319 | 1.714 | 2.069 | 2.500 | 2.807 | 3.485 |
| 24 | 1.318 | 1.711 | 2.064 | 2.492 | 2.797 | 3.467 |
| 25 | 1.316 | 1.708 | 2.060 | 2.485 | 2.787 | 3.450 |
| 26 | 1.315 | 1.706 | 2.056 | 2.479 | 2.779 | 3.435 |
| 27 | 1.314 | 1.703 | 2.052 | 2.473 | 2.771 | 3.421 |
| 28 | 1.313 | 1.701 | 2.048 | 2.467 | 2.763 | 3.408 |
| 29 | 1.311 | 1.699 | 2.045 | 2.462 | 2.756 | 3.396 |
| 30 | 1.310 | 1.697 | 2.042 | 2.457 | 2.750 | 3.385 |
| 40 | 1.303 | 1.684 | 2.021 | 2.423 | 2.704 | 3.307 |
| 60 | 1.296 | 1.671 | 2.000 | 2.390 | 2.660 | 3.232 |
| ∞ | 1.282 | 1.645 | 1.960 | 2.326 | 2.576 | 3.090 |
Tip: For exact p-values or larger df, use software (Excel: T.INV.2T, Google Sheets, R: qt()). See Appendix 5 for technology tips.
Related: Lesson 6 — The t-test • Lesson 7 — Analysis of Variance (ANOVA)
Add new comment