Introduction. This lesson is hands-on, data-driven, and calculation-oriented. It prepares students to do t-tests with data. The t-test compares means when the population standard deviation is unknown and is estimated from the sample, so the standardized statistic follows Student’s t distribution with appropriate degrees of freedom (df). The three common variants are: (a) one-sample (compare a sample mean to a reference value \( \mu_0 \)); (b) independent-samples (compare means of two unrelated groups); and (c) paired-samples (compare repeated measures on the same units by testing the mean of the differences). All t-tests assume independent observations and approximately normal residuals; only the pooled independent-samples test assumes equal variances.
A) One-Sample t-Test
Goal. Test whether a sample mean differs from a known/reference mean \( \mu_0 \).
Design & Experiment
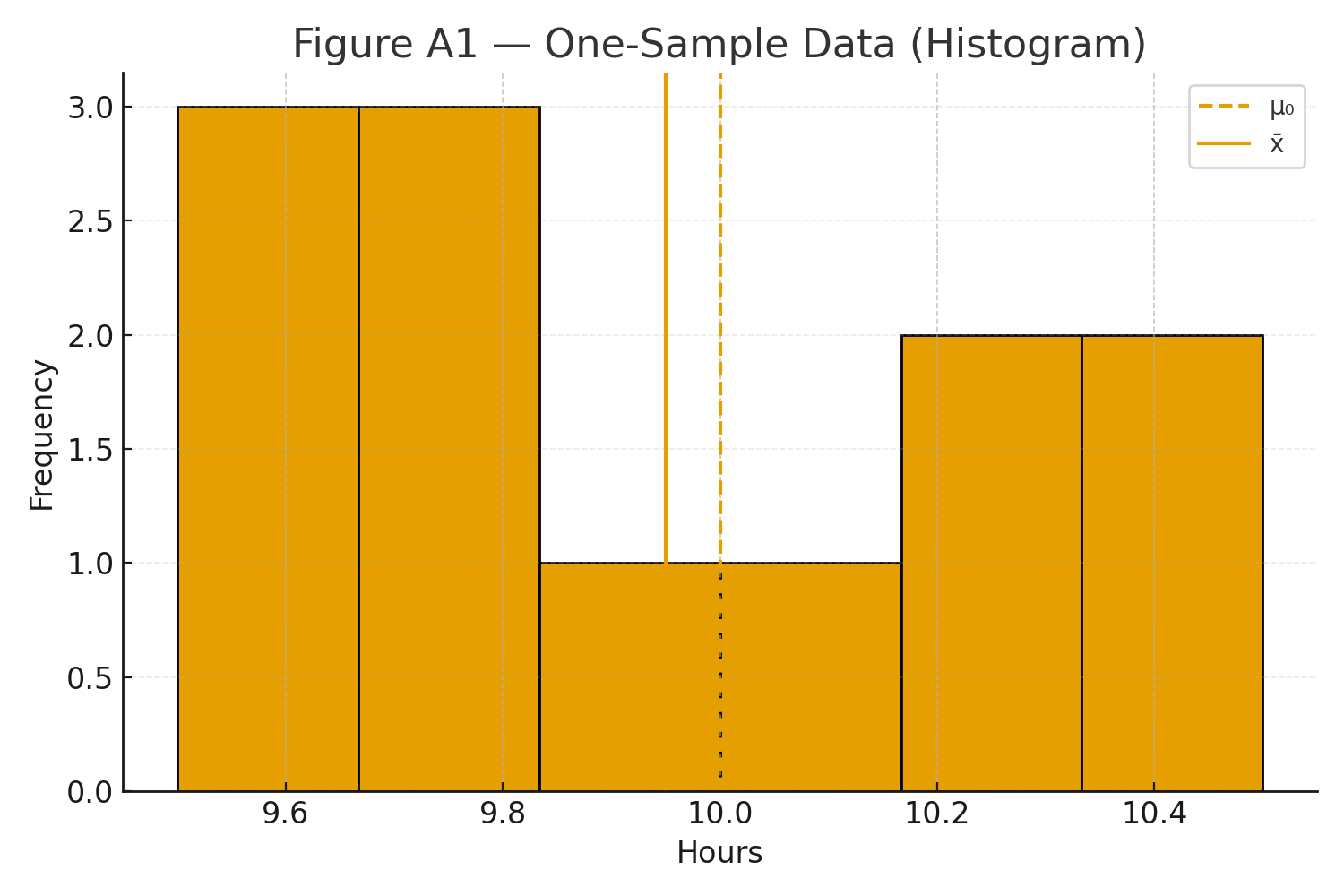
A company claims average battery life is \( \mu_0 = 10 \) hours. We test \( n=12 \) units.
Data
| Hours (n = 12) |
|---|
| 9.6, 10.1, 10.5, 9.9, 9.7, 10.4, 9.8, 9.6, 10.2, 9.5, 10.3, 9.8 |
Figure A1: Histogram/QQ plot for one-sample data.
Step 1 — Sum, Mean, Variance
\(\sum x = 119.4 \Rightarrow \bar X = 9.95.\) Using \( \sum (x-\bar X)^2 = 1.086 \Rightarrow s^2 = 1.086/11 = 0.0987,\; s = 0.314.\)
Step 2 — Test Statistic & p-value
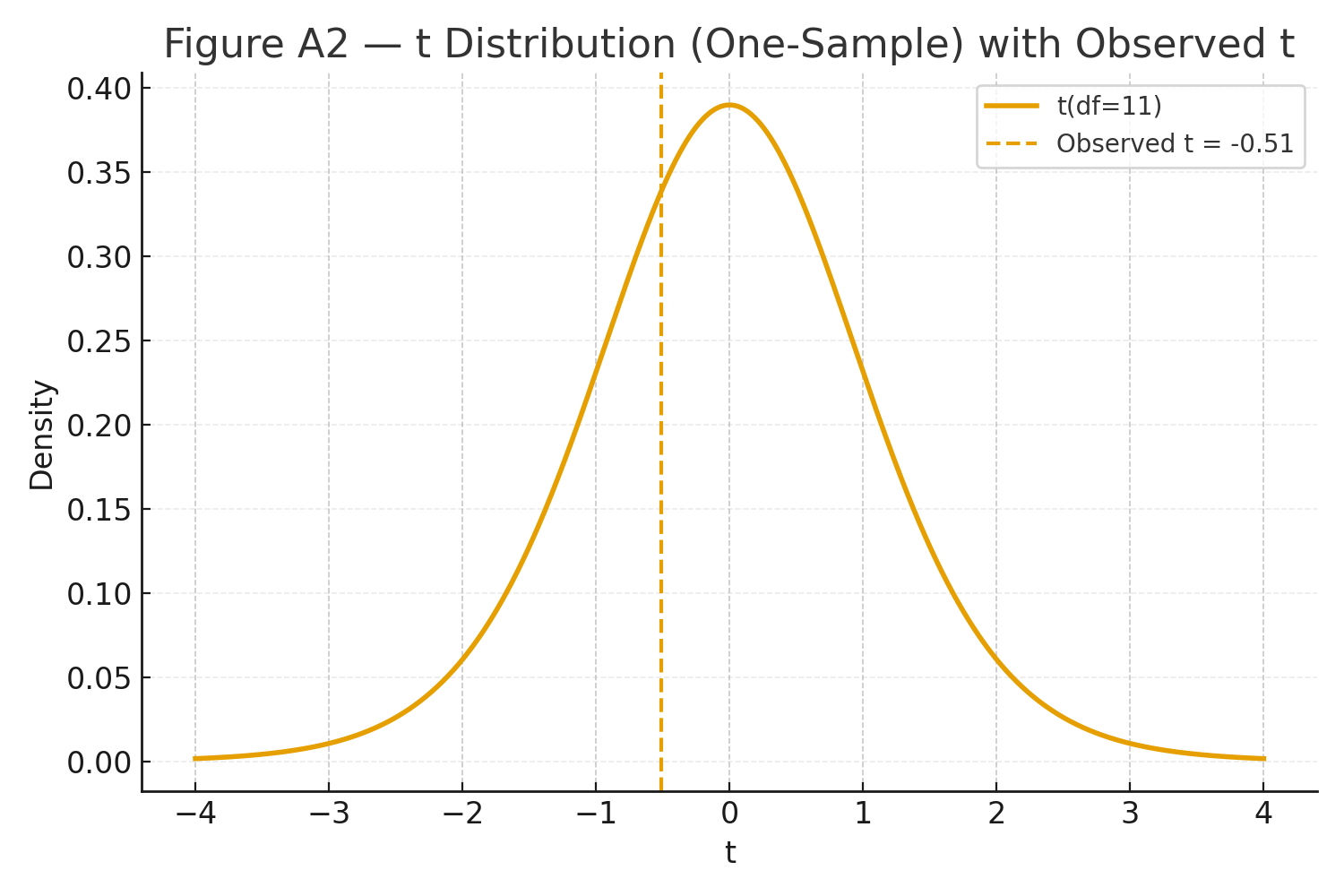
\(\displaystyle SE = \frac{s}{\sqrt{n}} = \frac{0.314}{\sqrt{12}} = 0.0906,\quad t = \frac{\bar X - \mu_0}{SE} = \frac{9.95 - 10}{0.0906} = -0.552,\quad df = n-1 = 11. \)
Two-tailed \(p \approx 0.59\) → fail to reject \(H_0\).
Figure A2: t curve (df=11) with observed \(t\) marked.
Conclusion (One-Sample)
No evidence the true mean differs from 10 hours (\(t(11)=-0.55,\; p=.59\)).
B) Independent-Samples t-Test
Goal. Test whether two teaching methods lead to different average exam scores.
Design & Experiment
Twenty students are randomly assigned to one of two methods (n = 10 per group).
- Method A: Active discussion
- Method B: Structured lecture
After a 2-week module, everyone takes the same 100-point exam.
Data
| Method A | Method B |
|---|
| 72 | 78 |
| 68 | 82 |
| 75 | 80 |
| 70 | 77 |
| 69 | 79 |
| 73 | 81 |
| 71 | 83 |
| 74 | 76 |
| 76 | 78 |
| 72 | 80 |
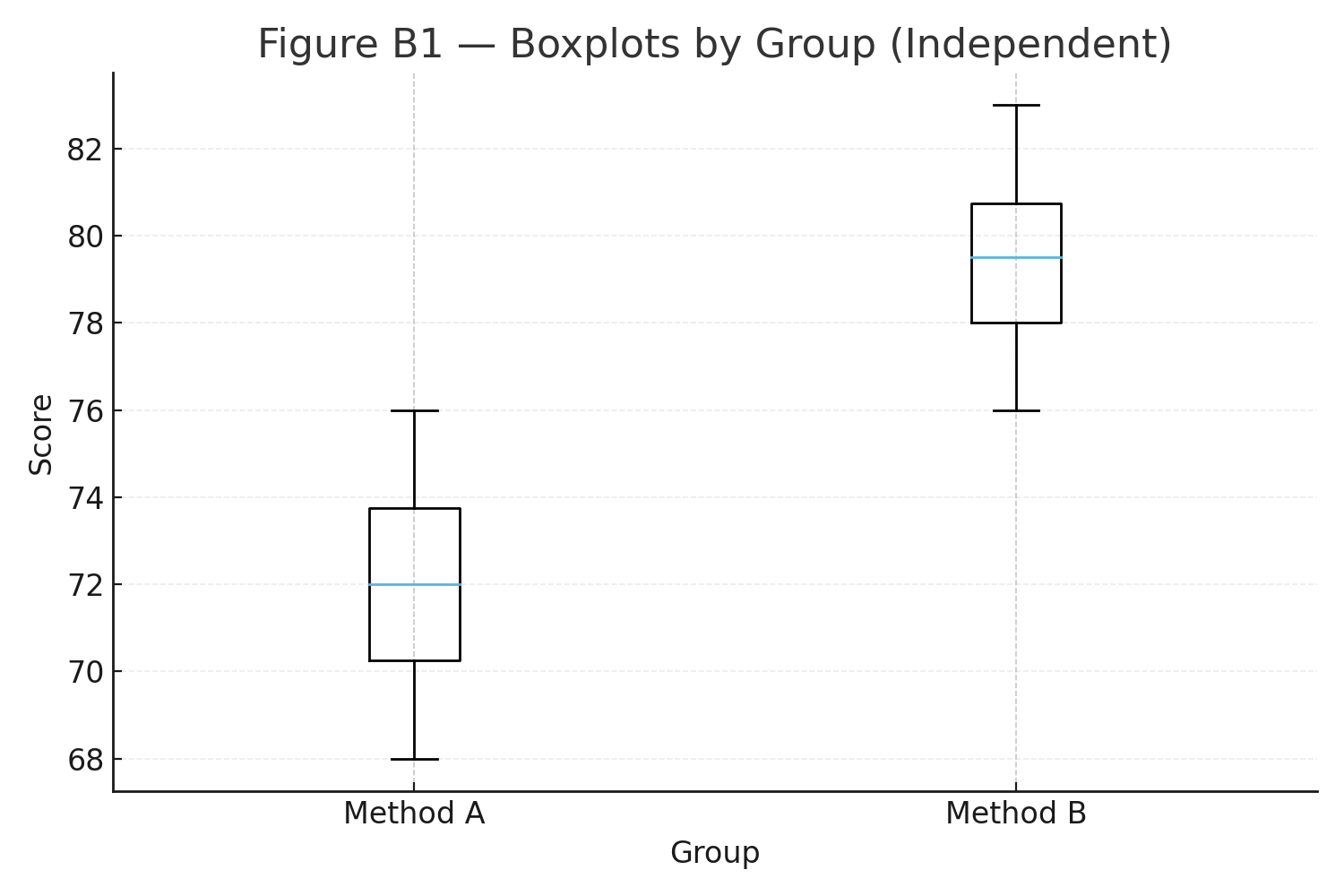
Figure B1: Boxplots of scores by group.
Step 1 — Sums & Means
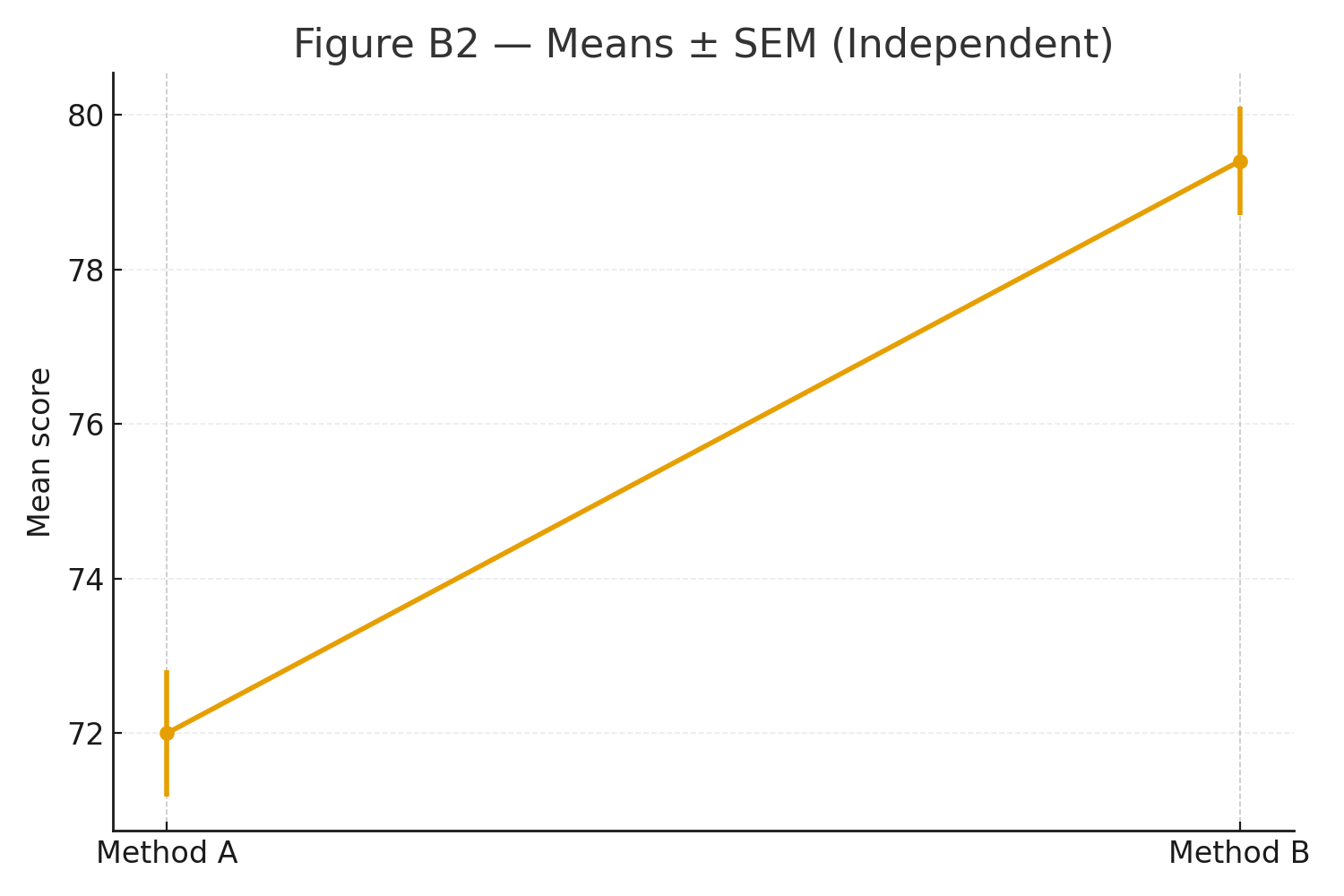
\(\displaystyle \sum A=720 \Rightarrow \bar A=72.0,\qquad \sum B=794 \Rightarrow \bar B=79.4,\qquad \bar A-\bar B=-7.4. \)
Step 2 — Within-Group Variability (sample variances)
- \(SS_A=60.0 \Rightarrow s_A^2=60/9=6.6667.\)
- \(SS_B=44.40 \Rightarrow s_B^2=44.40/9=4.9333.\)
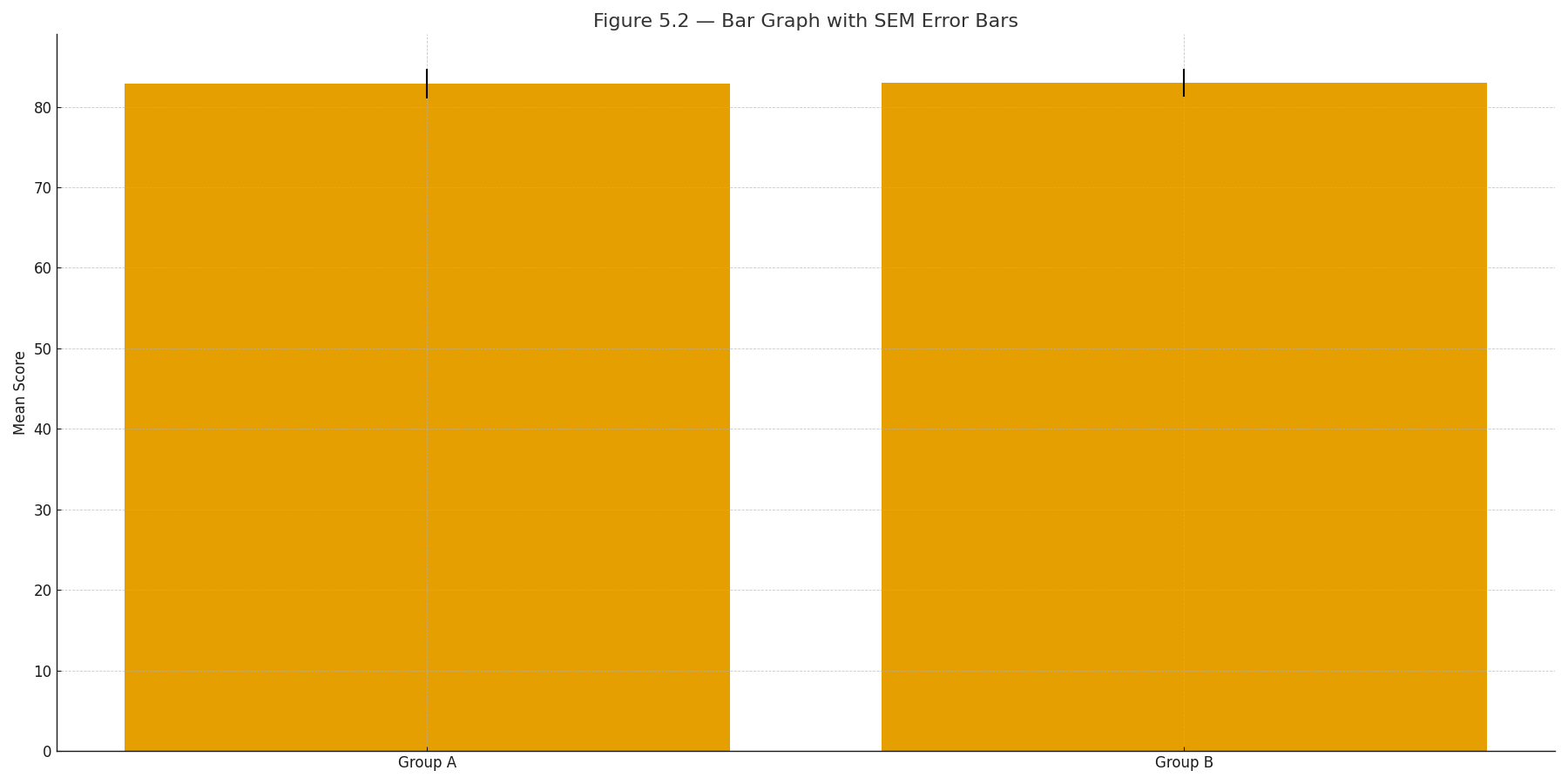
Figure B2: Group means with SEM error bars.
Step 3 — Pooled Variance & Standard Error (Student’s t)
\(\displaystyle s_p^2=\frac{9(6.6667)+9(4.9333)}{18}=5.8000,\qquad SE=\sqrt{5.8\,(0.1+0.1)}=\sqrt{1.16}=1.0770. \)
Step 4 — Test Statistic, df, p
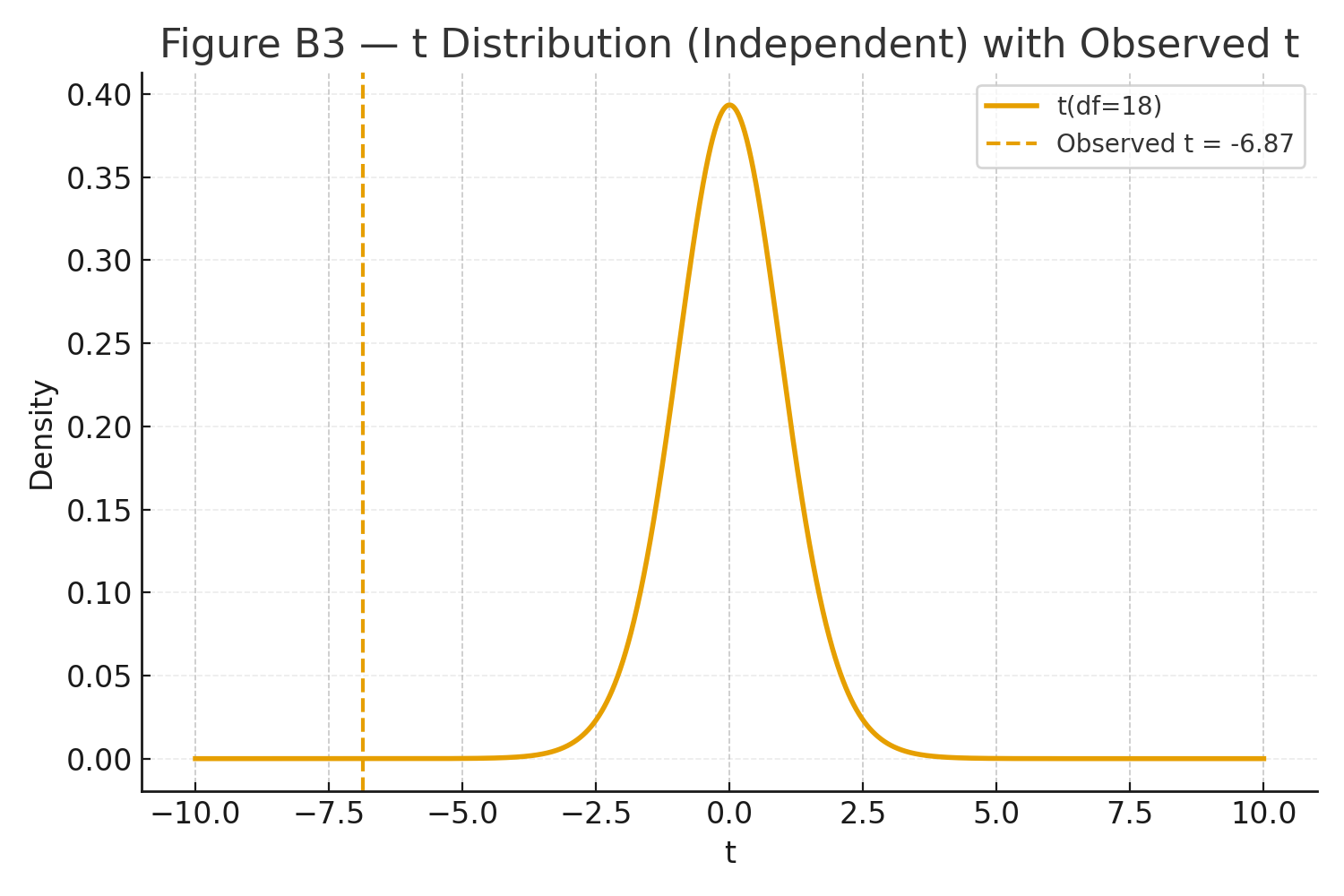
\(\displaystyle t=\frac{-7.4}{1.0770}=-6.872,\qquad df=18,\qquad p\ (\text{two-tailed}) \ll .001. \)
Figure B3: t distribution with observed \(t\) marked (two-tailed).
t-Test Summary Table (Independent)
| Group | n | Mean | SD | SE(mean) |
|---|
| Method A | 10 | 72.00 | 2.582 | 0.816 |
| Method B | 10 | 79.40 | 2.222 | 0.703 |
| \(\bar A-\bar B\) | SE (pooled) | t | df | p (2-tailed) |
|---|
| -7.40 | 1.0770 | -6.872 | 18 | < .001 |
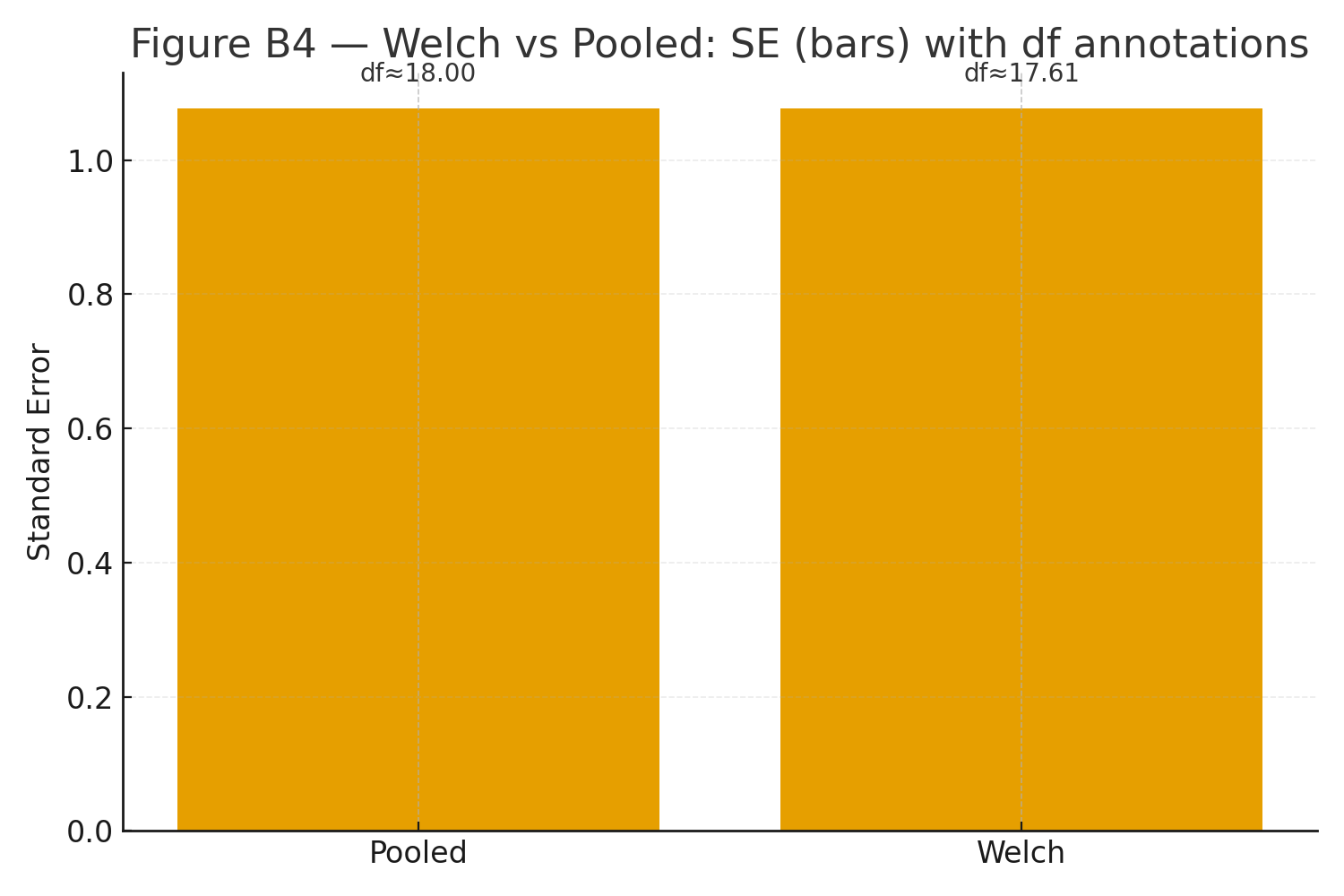
Optional Welch: \(SE_W=\sqrt{0.6667+0.4933}=1.0770,\; df_W\approx 17.61,\; t=-6.872,\; p\ll .001.\; Figure B4: Welch vs pooled comparison sketch.
Conclusion (Independent)
Method B yields higher mean scores than Method A (\(t(18)=-6.87,\; p\ll .001\)).
C) Paired-Samples (Dependent) t-Test
Goal. Test whether the mean change (After − Before) differs from zero for the same participants.
Design & Experiment
Eight students take an exam before and after a study-skills workshop.
Data
| Before | After | Difference \(d\) (After − Before) |
|---|
| 70 | 74 | 4 |
| 73 | 75 | 2 |
| 68 | 73 | 5 |
| 74 | 79 | 5 |
| 71 | 74 | 3 |
| 70 | 72 | 2 |
| 73 | 77 | 4 |
| 74 | 77 | 3 |
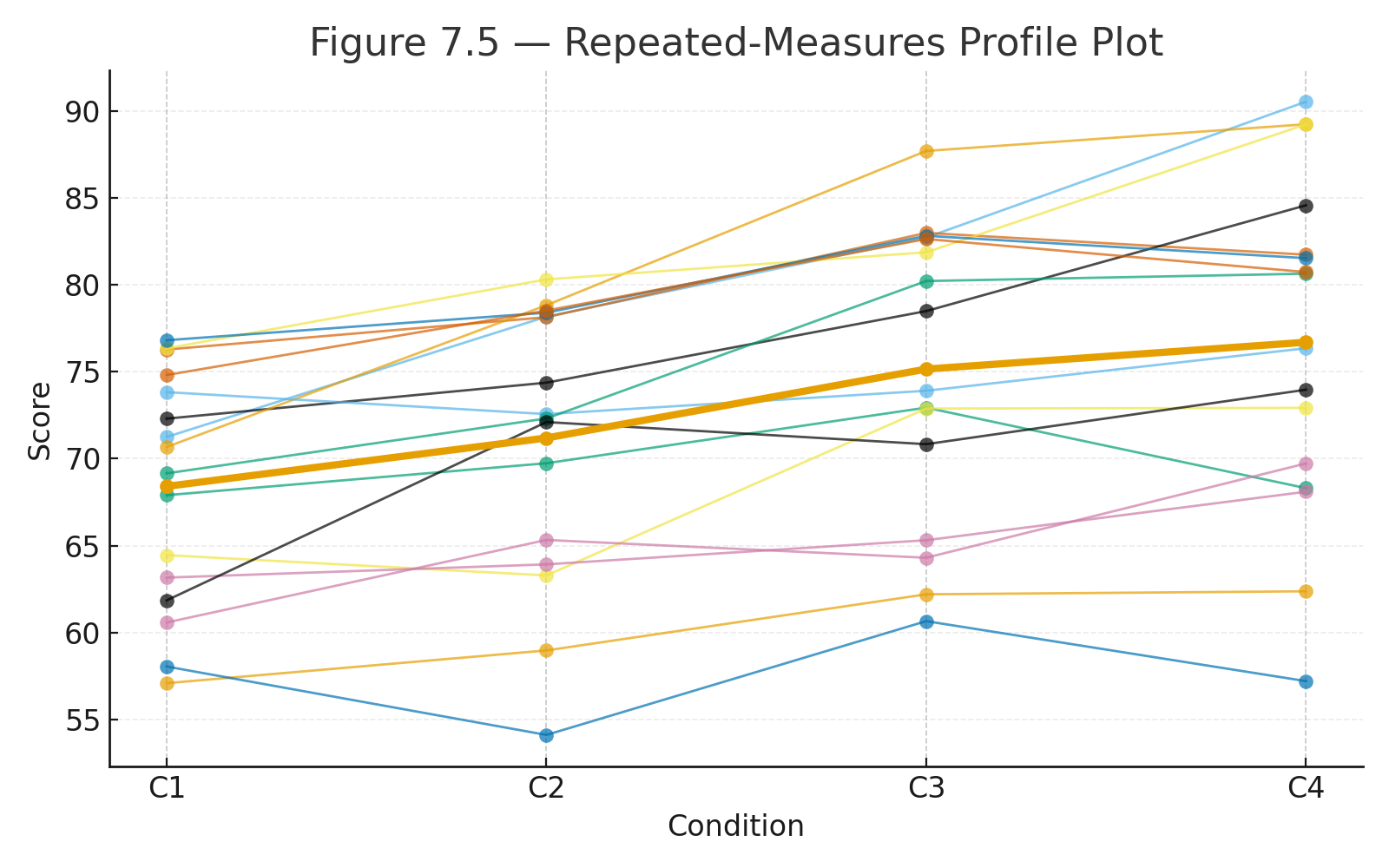
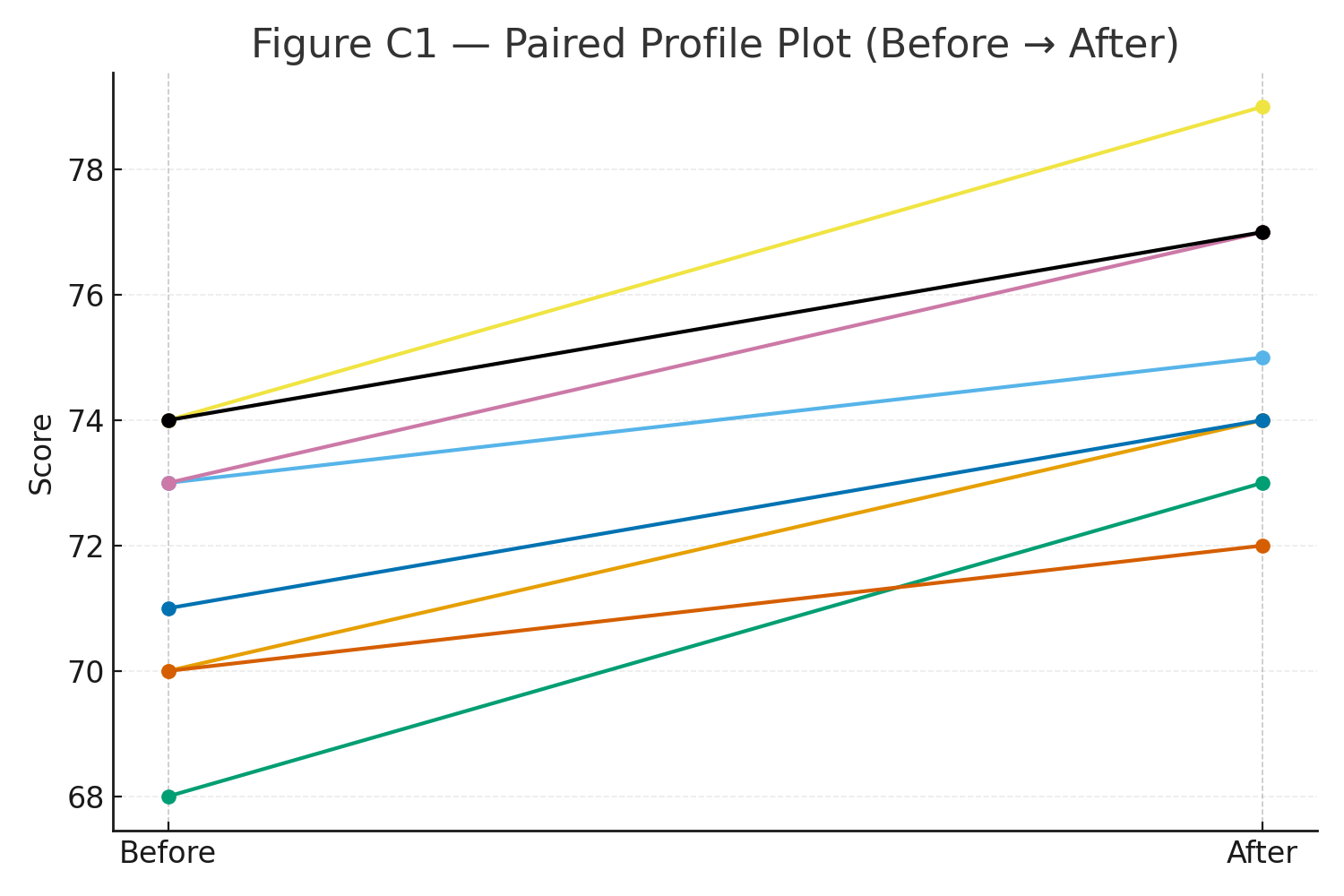
Figure C1: Paired profile plot (lines per subject) + histogram of differences.
Step 1 — Mean Difference & Variability
\(\sum d = 28 \Rightarrow \bar d = 3.5.\) \(\sum (d-\bar d)^2 = 10 \Rightarrow s_d^2 = 10/7 = 1.4286,\; s_d=1.196.\)
Step 2 — Test Statistic & p-value
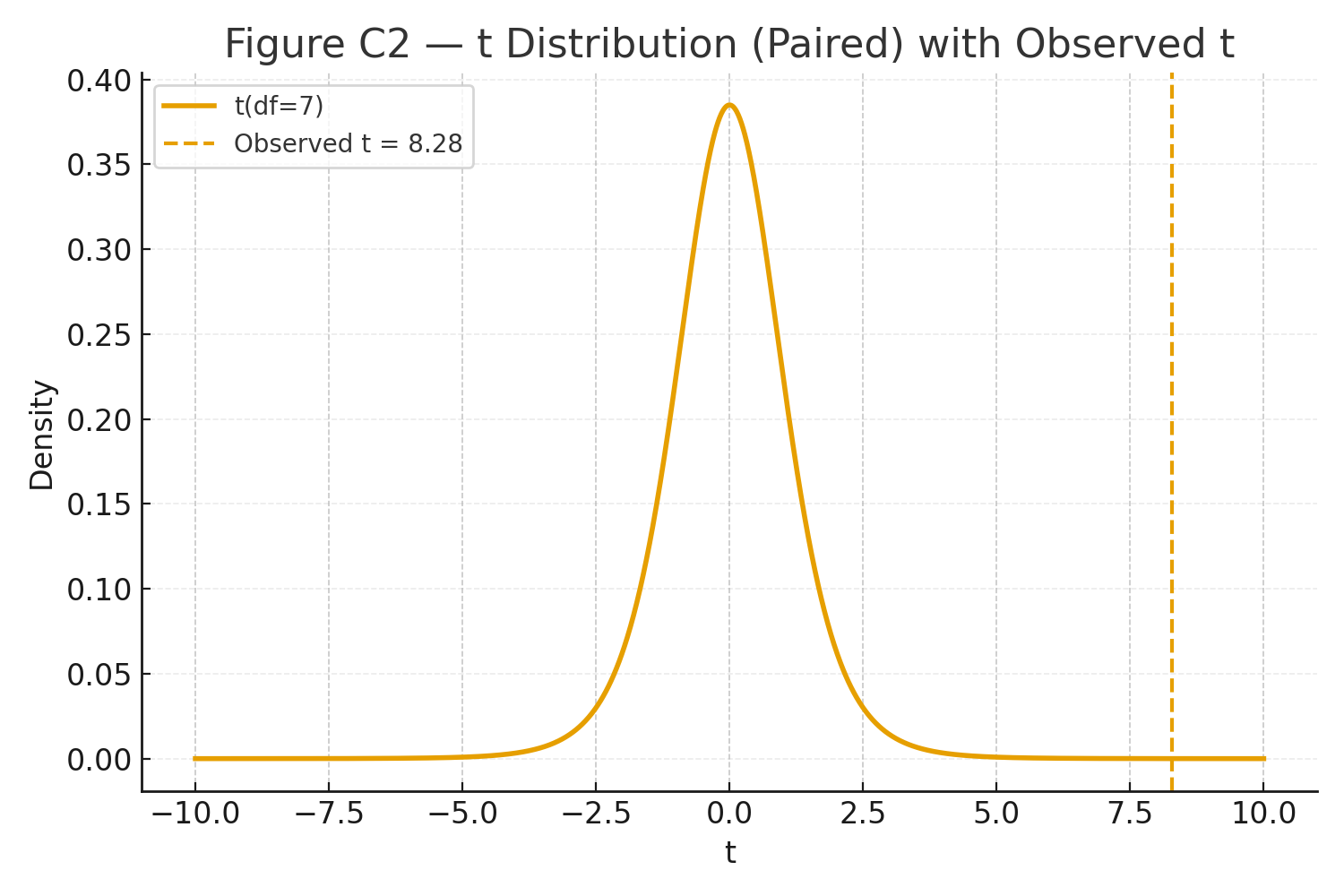
\(\displaystyle SE_{\bar d} = \frac{s_d}{\sqrt{n}}=\frac{1.196}{\sqrt{8}}=0.423,\quad t=\frac{\bar d}{SE_{\bar d}}=\frac{3.5}{0.423}=8.28,\quad df=n-1=7,\quad p\ll .001. \)
Figure C2: t curve (df=7) with observed \(t\) marked.
Conclusion (Paired)
Scores improve after the workshop (\(t(7)=8.28,\; p\ll .001\)).
Assumptions (checklist)
- Independent observations (between units; pairing respected for the paired test).
- Approximately normal residuals (or differences for the paired test).
- Equal variances only for the pooled independent-samples test; if doubtful, report Welch’s t.
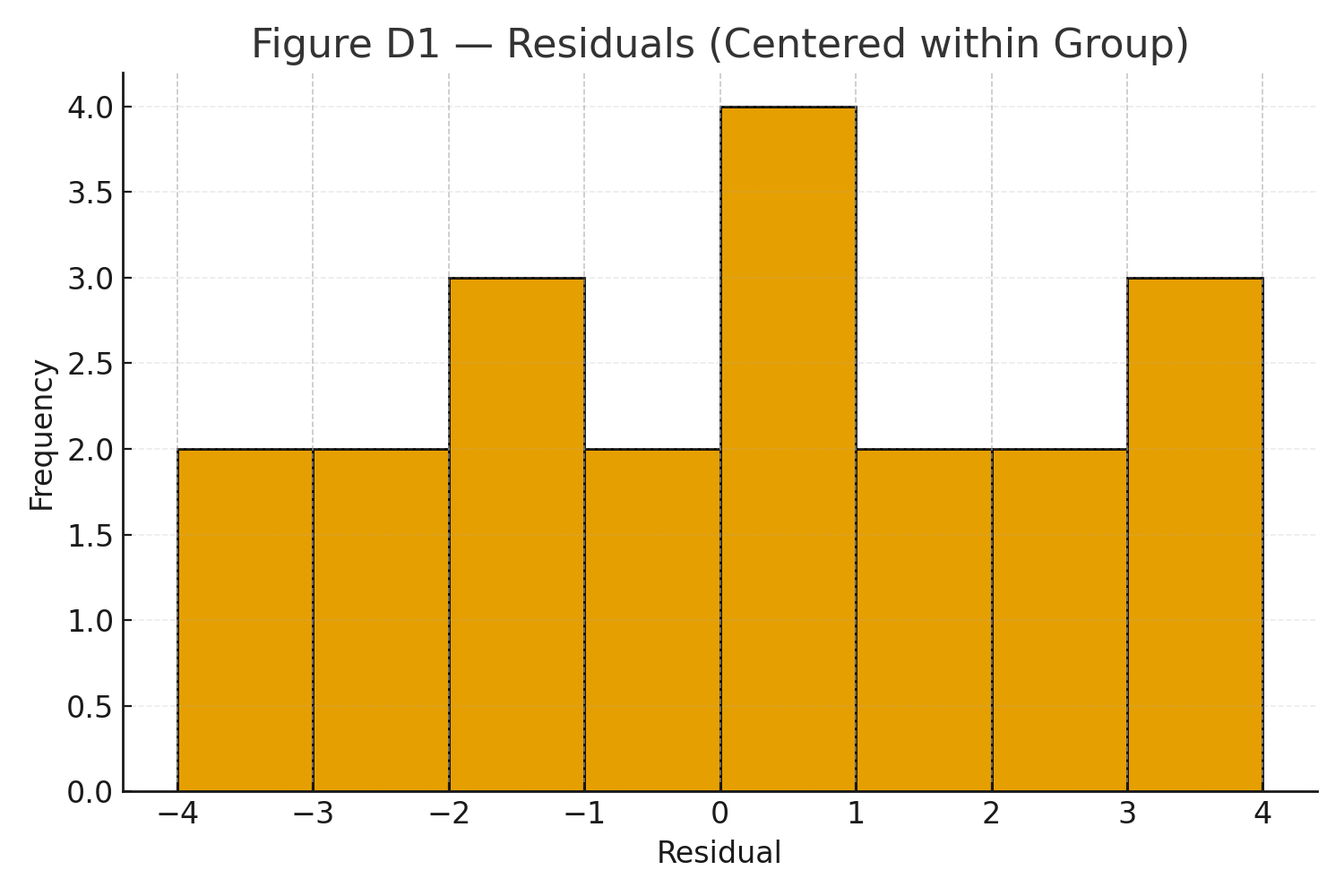
Figure D1: QQ plots and Levene/Brown–Forsythe sketch.
Practice self-test quiz
In the space below, please find practice problems and self-test quizzes. For full access, please signup free.