Lesson 17 — Regression Beyond the Line
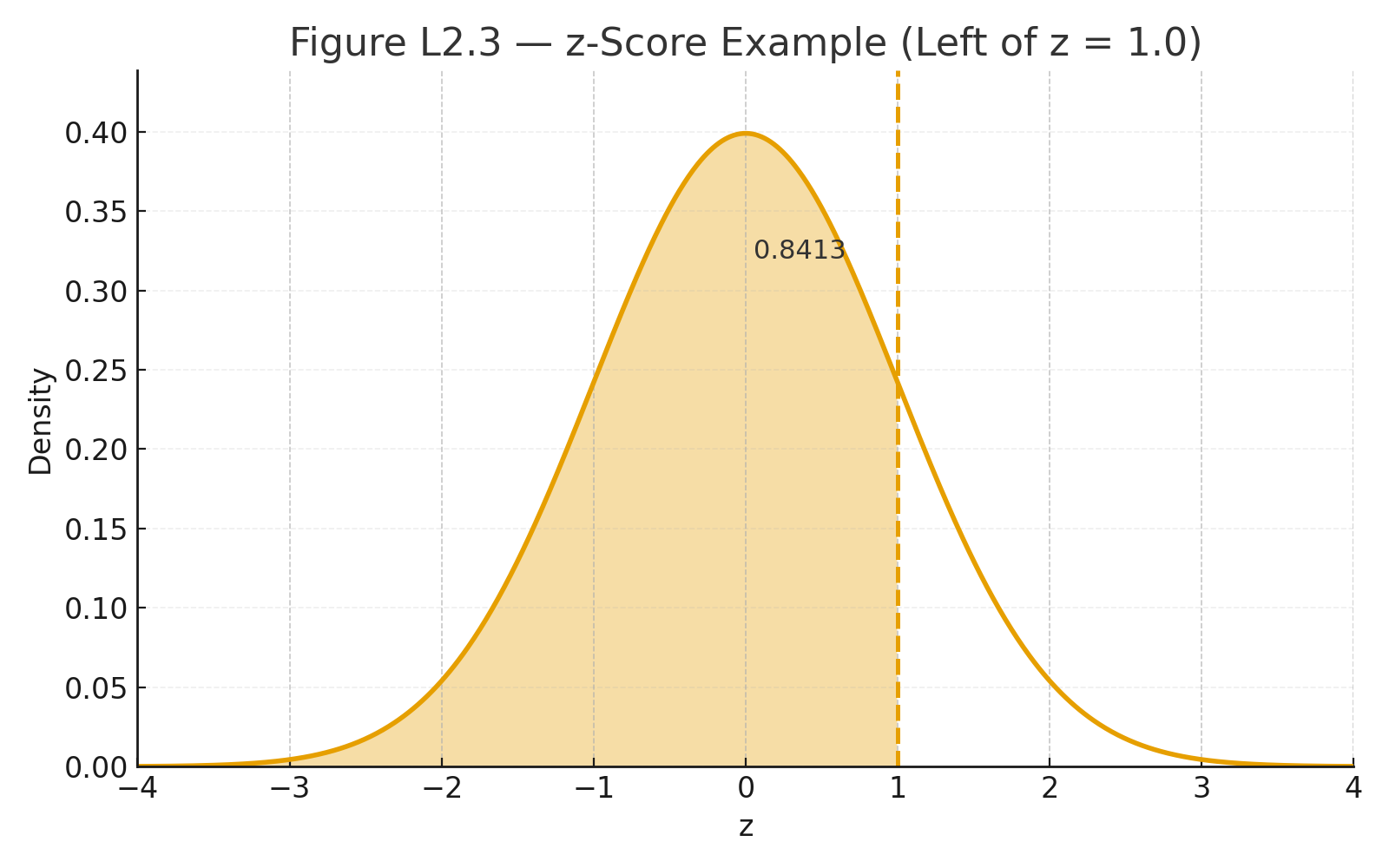
Simple regression predicts Y from one X.
But in real life, outcomes often depend on several variables — or may not be linear.
This chapter introduces multiple regression and logistic regression.
Multiple Regression
Formula:
$$\hat{Y} = a + b_1X_1 + b_2X_2 + \dots + b_kX_k$$
In words:
$$\text{Predicted Y} = \text{intercept} + (b_1 \times X_1) + (b_2 \times X_2) + \dots$$
Where:
- $$X_1, X_2, \dots X_k$$ = predictors
- $$b_1, b_2, \dots b_k$$ = slopes (weights for each predictor)
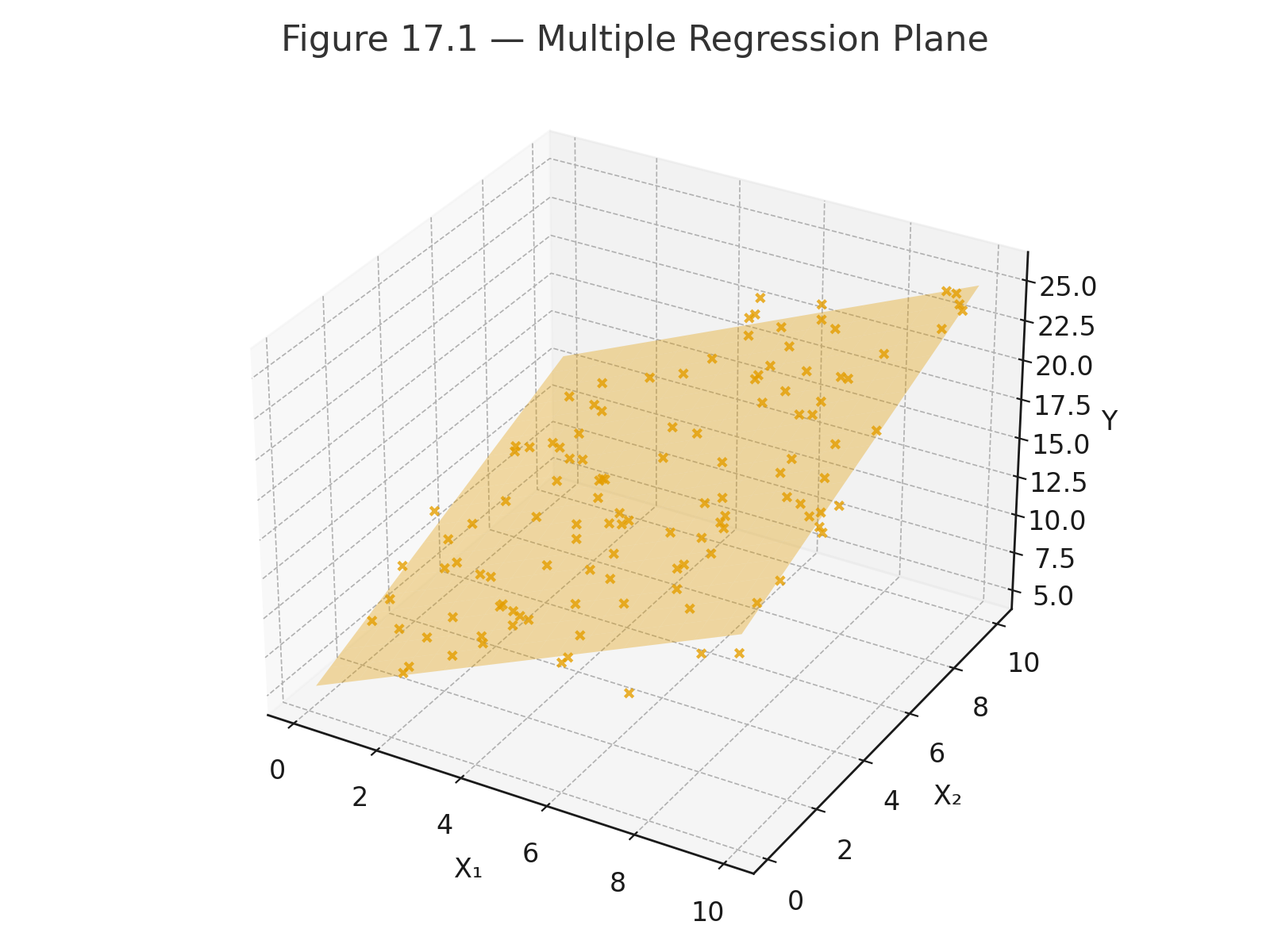
Example: Predicting college GPA from:
- High school GPA ($$X_1$$)
- Study hours ($$X_2$$)
Equation:
$$\hat{Y} = 1.0 + 0.5X_1 + 0.1X_2$$
Interpretation:
- For each 1-point increase in HS GPA, college GPA rises 0.5.
- For each extra study hour, GPA rises 0.1.
Coefficient of Determination
In multiple regression, $$R^2$$ tells us the proportion of variance explained by all predictors together.
Example: $$R^2 = 0.65$$ → predictors explain 65% of the outcome’s variability.
Logistic Regression
What if the outcome is yes/no (categorical)?
Example: Will a student pass or fail?
We use logistic regression.
Formula:
$$P(Y=1) = \frac{1}{1 + e^{-(a + bX)}}$$
In words:
$$\text{Probability of success} = \frac{1}{1 + e^{-(\text{intercept} + \text{slope} \times X)}}$$
Output: probability between 0 and 1.
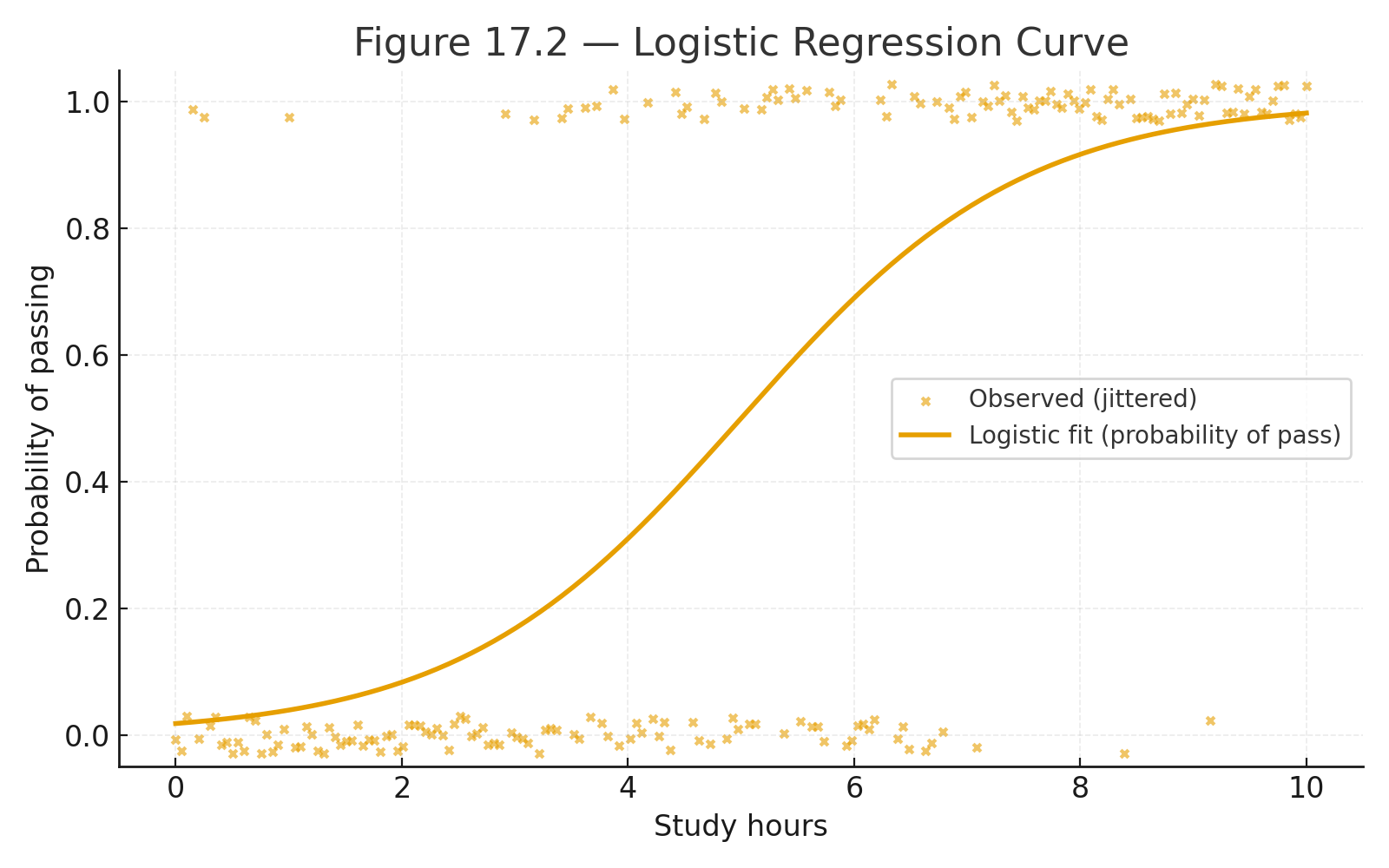
Example: Predicting pass/fail from study hours.
- Equation: $$P = \frac{1}{1 + e^{-( -2 + 0.5X )}}$$
- If X = 6 hours: $$P = \frac{1}{1 + e^{-1}} = 0.73$$
- About 73% chance of passing.
Visuals
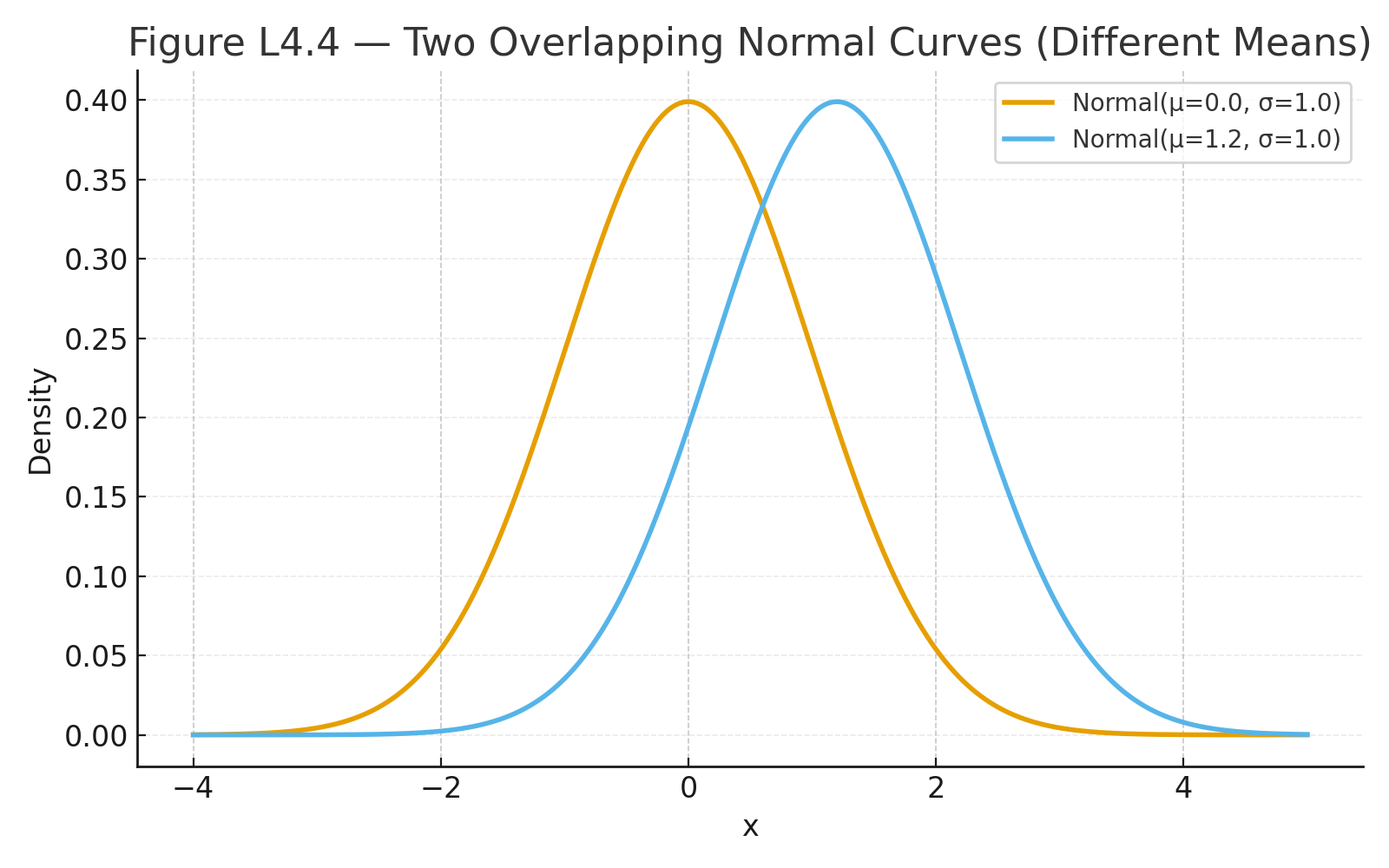
Figure 17.1 — Multiple regression plane: Y predicted from two predictors.
Figure 17.2 — Logistic regression curve: probability vs. study hours.
Why This Matters
- Multiple regression = prediction with many factors
- Logistic regression = prediction when the outcome is categorical
- $$R^2$$ = strength of prediction
These methods expand the power of regression beyond a straight line, preparing for modern predictive modeling.
Practice self-test quiz
In the space below, please find practice problems and self-test quizzes. For full access, please signup free.